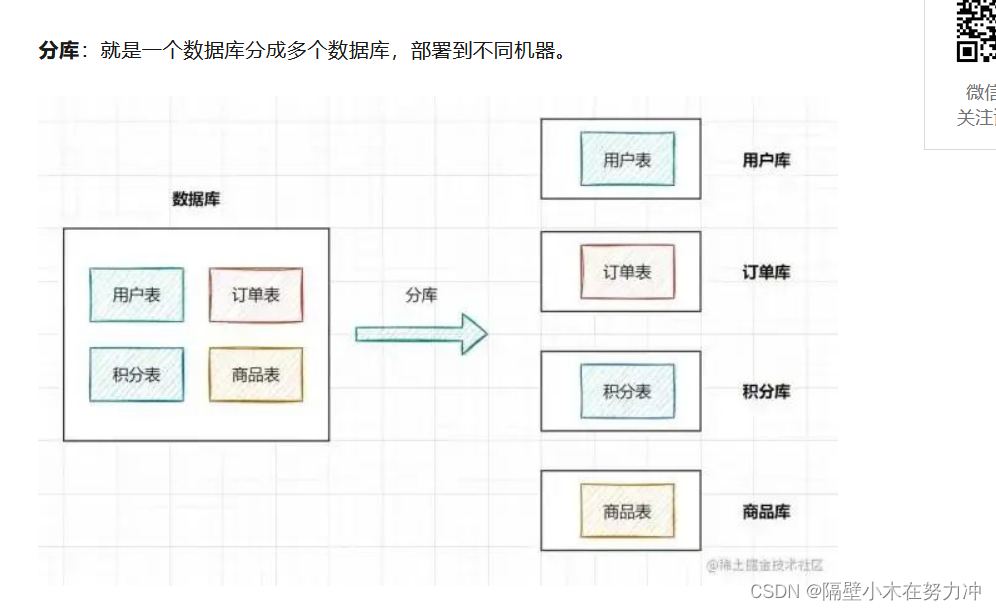
一.数据库的分库分表?

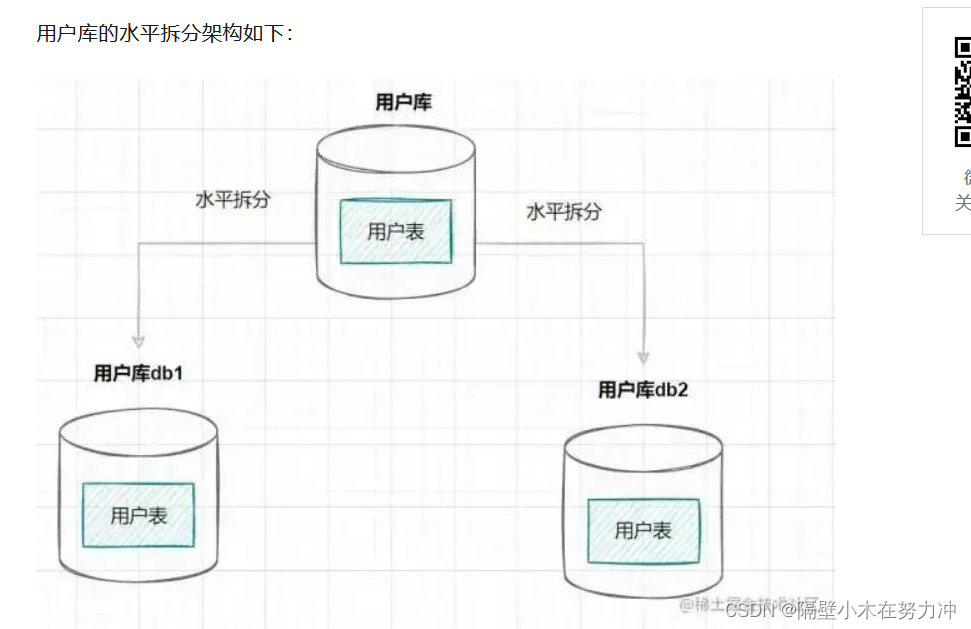
二.为什么需要分库分表?

 三.如何分库分表?
三.如何分库分表?



四.配置分库分表的准备工作
4.1.创建三个数据库:compay,jiaowu,goods
#创建“company”数据库
MariaDB [(none)]> create database company character set utf8;
Query OK, 1 row affected (0.001 sec)
MariaDB [(none)]> use company
Database changed
#在‘company’中创建“emp”表
MariaDB [company]> CREATE TABLE `emp` (
-> `empno` int(4) NOT NULL,
-> `ename` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
-> `job` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
-> `mgr` int(4) NULL DEFAULT NULL,
-> `hiredate` date NOT NULL,
-> `sai` int(255) NOT NULL,
-> `comm` int(255) NULL DEFAULT NULL,
-> `deptno` int(2) NOT NULL,
-> PRIMARY KEY (`empno`) USING BTREE
-> );
Query OK, 0 rows affected (0.015 sec)
#在‘emp’中插入数据
INSERT INTO `emp` VALUES (1001, '甘宁', '文员', 1013, '2000-12-17', 8000, NULL, 20);
INSERT INTO `emp` VALUES (1002, '黛绮丝', '销售员', 1006, '2001-02-20', 16000, 3000, 30);
INSERT INTO `emp` VALUES (1003, '殷天正', '销售员', 1006, '2001-02-22', 12500, 5000, 30);
INSERT INTO `emp` VALUES (1004, '刘备', '经理', 1009, '2001-04-02', 29750, NULL, 20);
INSERT INTO `emp` VALUES (1005, '谢逊', '销售员', 1006, '2001-09-28', 12500, 14000, 30);
INSERT INTO `emp` VALUES (1006, '关羽', '经理', 1009, '2001-05-01', 28500, NULL, 30);
INSERT INTO `emp` VALUES (1007, '张飞', '经理', 1009, '2001-09-01', 24500, NULL, 10);
INSERT INTO `emp` VALUES (1008, '诸葛亮', '分析师', 1004, '2007-04-19', 30000, NULL, 20);
INSERT INTO `emp` VALUES (1009, '曾阿牛', '董事长', NULL, '2001-11-17', 50000, NULL, 10);
INSERT INTO `emp` VALUES (1010, '韦一笑', '销售员', 1006, '2001-09-08', 15000, 0, 30);
INSERT INTO `emp` VALUES (1011, '周泰', '文员', 1006, '2007-05-23', 11000, NULL, 20);
INSERT INTO `emp` VALUES (1012, '程普', '文员', 1006, '2001-12-03', 9500, NULL, 30);
INSERT INTO `emp` VALUES (1013, '庞统', '分析师', 1004, '2001-12-03', 30000, NULL, 20);
INSERT INTO `emp` VALUES (1014, '黄盖', '文员', 1007, '2002-01-23', 13000, NULL, 10);
INSERT INTO `emp` VALUES (1015, '张三', '保洁员', 1001, '2013-05-01', 80000, 50000, 50);
#在‘company’数据库中建立‘dept’表
MariaDB [company]> CREATE TABLE `dept` (
-> `deptno` int NOT NULL ,
-> `dname` char(9) NOT NULL ,
-> `loc` char(6) NOT NULL
-> );
Query OK, 0 rows affected (0.055 sec)
#在‘dept’中插入数据
MariaDB [company]> INSERT INTO `dept` VALUES (10, '教研部', '北京');
Query OK, 1 row affected (0.003 sec)
MariaDB [company]> INSERT INTO `dept` VALUES (20, '学工部', '上海');
Query OK, 1 row affected (0.001 sec)
MariaDB [company]> INSERT INTO `dept` VALUES (30, '销售部', '广州');
Query OK, 1 row affected (0.003 sec)
MariaDB [company]> INSERT INTO `dept` VALUES (40, '财务部', '武汉');
Query OK, 1 row affected (0.002 sec)
#上传jiaowu数据库及表
MariaDB [jiaowu]> source /root/jiaowu.sql
#上传goods数据库及表
MariaDB [jiaowu]> source /root/goods.sql
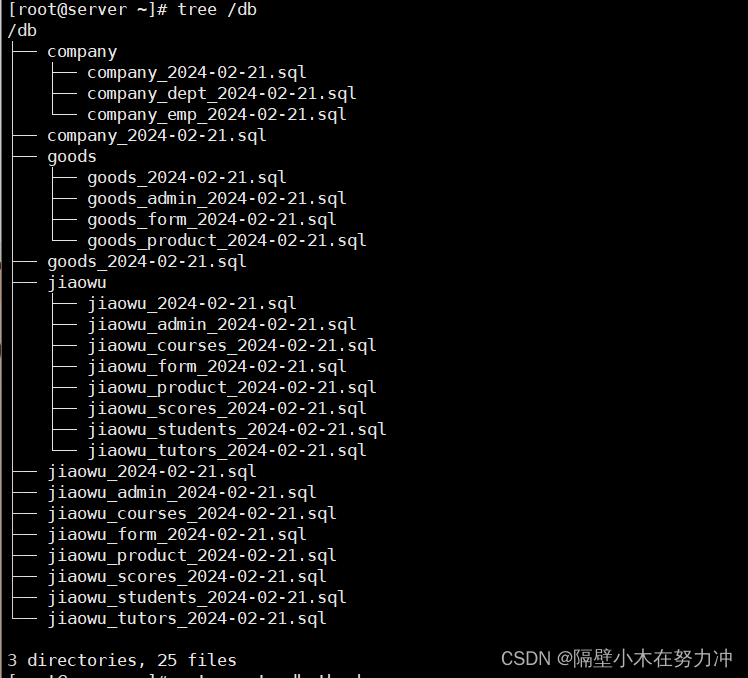
4.2.查看数据库及表
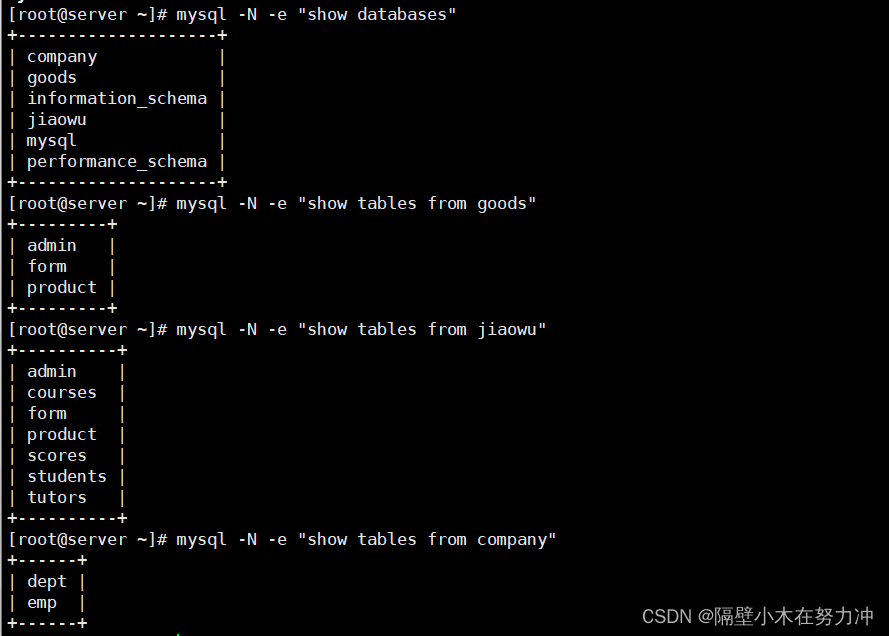
-e 后面跟上要执行的SQL语句
-N 参数是不显示表头
五.分库分表备份
mysqldump命令备份数据的原理:就是把数据从MySQL库里以逻辑的sql语句形式直接输出或者生成备份的文件的过程。
-B: 用于备份多个数据库
grep的主要作用是根据关键字检索内容,egrep是grep的拓展,egrep包含grep所有的功能
-v 取反(显示不包含关键词的行)
在bash中,
$( )与` `(反引号)都是用来作命令替换的一般情况下,$var与${var}是没有区别的,但是用${ }会比较精确的界定变量名称的范围
5.1.分库备份
#编写脚本
#!/bin/bash
BAK_DIR=/db
[ -d ${BAK_DIR} ] || mkdir ${BAK_DIR} -pv
for name in $(mysql -N -e "show databases" | egrep -v "information_schema|mysql|performance_schema")
do
mysqldump -B $name > ${BAK_DIR}/${name}_$(date +%F).sql
done
#执行脚本
[root@server ~]# bash creat_db.sh

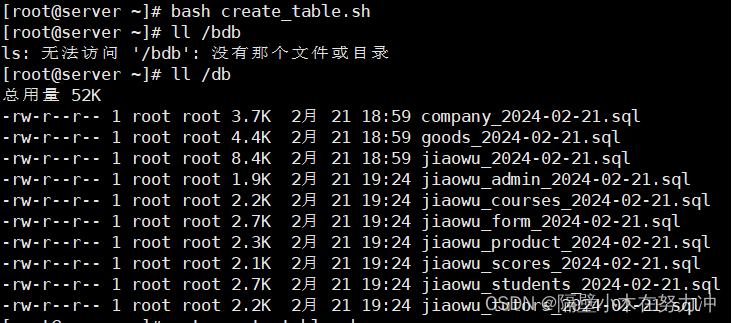
5.2.分表备份
[root@server ~]# cat create_table.sh
#!/bin/bash
BAK_DIR=/db
[ -d ${BAK_DIR} ] || mkdir ${BAK_DIR} -pv
for name in $(mysql -N -e "show tables from jiaowu")
do
mysqldump jiaowu $name > ${BAK_DIR}/jiaowu_${name}_$(date +%F).sql
done
5.3.分库分表备份
[root@server ~]# cat create_db_tb.sh
#!/bin/bash
for name in $(mysql -N -e "show databases" | egrep -v "information_schema|mysql|performance_schema")
do
BAK_DIR=/db
[ -d ${BAK_DIR}/$name ] || mkdir -pv ${BAK_DIR}/$name
mysqldump -B $name > ${BAK_DIR}/${name}/${name}_$(date +%F).sql
for table in $(mysql -N -e "show tables from $name")
do
mysqldump $name $table > ${BAK_DIR}/${name}/${name}_${table}_$(date +%F).sql
done
done
相关文章
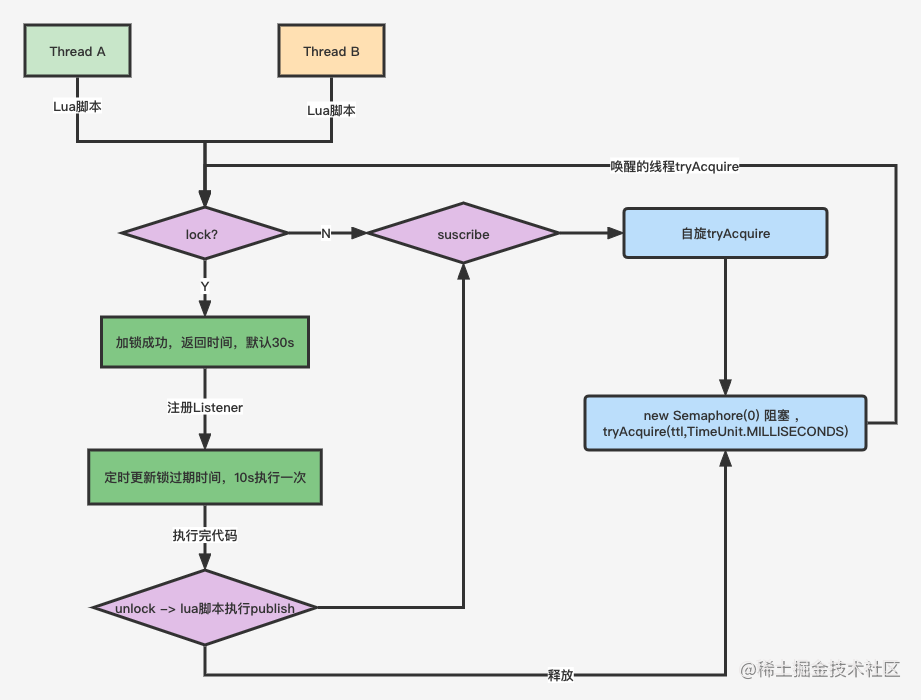
Redis高并发分布锁实战
Redis分布式锁自己去实现可能会出现几个问题没有在finally显示释放锁,当客户端挂掉了,锁没有被及时删除,这样会导致死锁问题,它这个是需要我们显示的释放锁假如此时我们设置过期时间,但是我们用的是同一个key,就可能出现下一个线程删除上一个线程的锁,但是上一个线程还没有执行完,它这个需要key是不能重复的假如我们既设置了过期时间也指定了不同的key,此时可能因为网络延迟出现上一个线程删除下一个线程的锁,也就是说业务执行的时间超过了锁过期的时间,它这个需要一个锁续命的功能。
编程日记 2024/02/28 09:11:20

Redis是否为单线程?
在深入讨论Redis是否为单线程之前,我们先来了解一下Redis的基本架构。Redis采用了基于内存的数据存储方式,数据存储在内存中,并通过持久化机制将数据定期写入磁盘。客户端:与Redis进行通信的应用程序。Server:负责处理客户端请求、执行命令和管理数据。数据结构:Redis支持多种数据结构,如字符串、列表、哈希表等。事件处理器:用于处理网络事件和命令请求。
编程日记 2024/02/28 09:10:26

MySQL中的高级查询
通过条件查询可以查询到符合条件的数据,但如同要实现对字段的值进行计算、根据一个或多个字段对查询结果进行分组等操作时,就需要使用更高级的查询,MySQL提供了聚合函数、分组查询、排序查询、限量查询、内置函数以实现更复杂的查询需求。接下来将针对这些高级查询的知识进行讲解。
编程日记 2024/02/24 08:33:50

ubuntu20.04安装实时内核补丁PREEMPT_RT
下载实时内核补丁,我下载patch-5.15.148-rt74.patch.sign和patch-5.15.148-rt74.patch.xz。通过以下指令看具体报错并输出日志到make.log:make -j1 deb-pkg 2>&1 | tee ~/make.log。比较幸运没遇到问题,重启进入后,启动页面没有变化,还是进入ubuntu,但是查看内核版本已经自动变到5.15.148。我下载linux-5.15.148.tar.xz和linux-5.15.148.tar.sign。
编程日记 2024/02/23 08:40:54
mysql中文首字母排序查询
MySQL中的排序涉及到字符集和排序规则。默认情况下,MySQL按照ASCII码对字符进行排序,数字>字母>中文。但是,特殊字符(非字母、数字、中文)的排序需要一些额外处理。匹配到非字母数字中文的内容,做排序,字母数字中文为null,排序优先级最高,排在上面。为什么用HEX()函数做十六进制编码?因为中文用常规的正则不能匹配到结果。试过SUBSTRING、LEFT等,都不能完美实现多中文的首字母排序。为什么要把字母数字中文放在一起匹配?因为处理复杂度会更高。这样可以处理更复杂的排序需求。
编程日记 2024/02/20 22:31:36
使用redis-insight连接到服务器上的redis数据库
我们现在虽然安装好了redis数据库,但是外界是连接不到的,我们需要打破这个限制!设置完之后,可以按以下图的命令查看,redis的密码是不是起作用了。的更改,并退出编辑器。在网上下载好redis-insight的客户端,打开。默认情况下,它可能被设置为只监听本地连接,如。这允许在没有进行身份验证的情况下接受外部连接。(3)为了增强安全性,强烈建议设置访问密码。三、使用redis-insight连接数据库。1.查找redis的配置文件。指令,并确保将其设置为。替换为你自己的强密码。
编程日记 2024/02/16 20:32:27

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案
mysql8登录第一次遇到MYSQL_ROOT_PASSWORD时会自动把该密码尽兴登录,生成一个秘钥放在mysql的数据文件里面,命令里带的MYSQL_ROOT_PASSWORD密码是个参数,除了第一次运行mysql带上会设置密码生成秘钥,其他次启动而不是设置mysql的密码,而是作为参数去验证这个最初的秘钥是否核对正确,于是我进入挂载的data目录,发现我的猜想是对的。通过docker将服务部署完后,navicat连接报错,密码错误,于是我尝试进入mysql容器登录 发现也报错。
编程日记 2024/02/08 18:08:55
数据湖Paimon入门指南
如果用户建表时指定'merge-engine' = 'partial-update',那么就会使用部分更新表引擎,可以做到多个 Flink 流任务去更新同一张表,每条流任务只更新一张表的部分列,最终实现一行完整的数据的更新,对于需要拉宽表的业务场景,partial-update 非常适合此场景,而且构建宽表的操作也相对简单。这种方式的成本相对较高,同时官方不建议这样使用,因为下游任务在 State 中存储一份全量的数据,即每条数据以及其变更记录都需要保存在状态中。流式查询将不断产生最新的更改。
编程日记 2024/02/05 08:46:01

虚拟机Windows Server 2016 安装 MySQL8
在虚拟机Windows Server 2016 中 安装MySQL8.0 并通过本机Navicat远程连接
编程日记 2024/02/04 09:56:57
基于SQL数据库的大模型RAG实现
检索增强生成 (RAG) 涉及从外部数据库获取当前或上下文相关信息,并在请求大型语言模型 (LLM) 生成响应时将其呈现给大型语言模型 (LLM) 的过程。这种方法有效地解决了生成不正确或误导性信息的问题。你能够存储专有业务数据或全局知识,并使你的应用程序能够在响应生成阶段为 LLM 检索此数据。
编程日记 2024/02/02 15:05:48
MySQL运行在docker容器中会损失多少性能
自从使用docker以来,就经常听说MySQL数据库最好别运行在容器中,性能会损失很多。一些之前没使用过容器的同事,对数据库运行在容器中也是忌讳莫深,甚至只要数据库跑在容器中出现性能问题时,首先就把问题推到容器上。
编程日记 2024/02/02 14:07:43

Mysql大数据量分页优化
之前有看过到mysql大数据量分页情况下性能会很差,但是没有探究过它的原因,今天讲一讲mysql大数据量下偏移量很大,性能很差的问题,并附上解决方式。
编程日记 2024/01/29 17:55:30
oracle data block , extent 和segment区别
总结来说,Data block是数据库中最小的逻辑存储单位,用于存储实际的数据记录;Extent是由若干个连续的Data blocks组成的区域,表示一段连续的存储空间;data block是数据库中最小的逻辑存储单元。当数据库的对象需要更多的物理存储空间时,连续的data block就组成了extent . 一个数据库对象拥有的所有extents被称为该对象的segment.Data block、extent和segment是数据库中不同层次的数据存储和管理单位,它们各自具有不同的功能和特点。
编程日记 2024/01/24 10:38:37
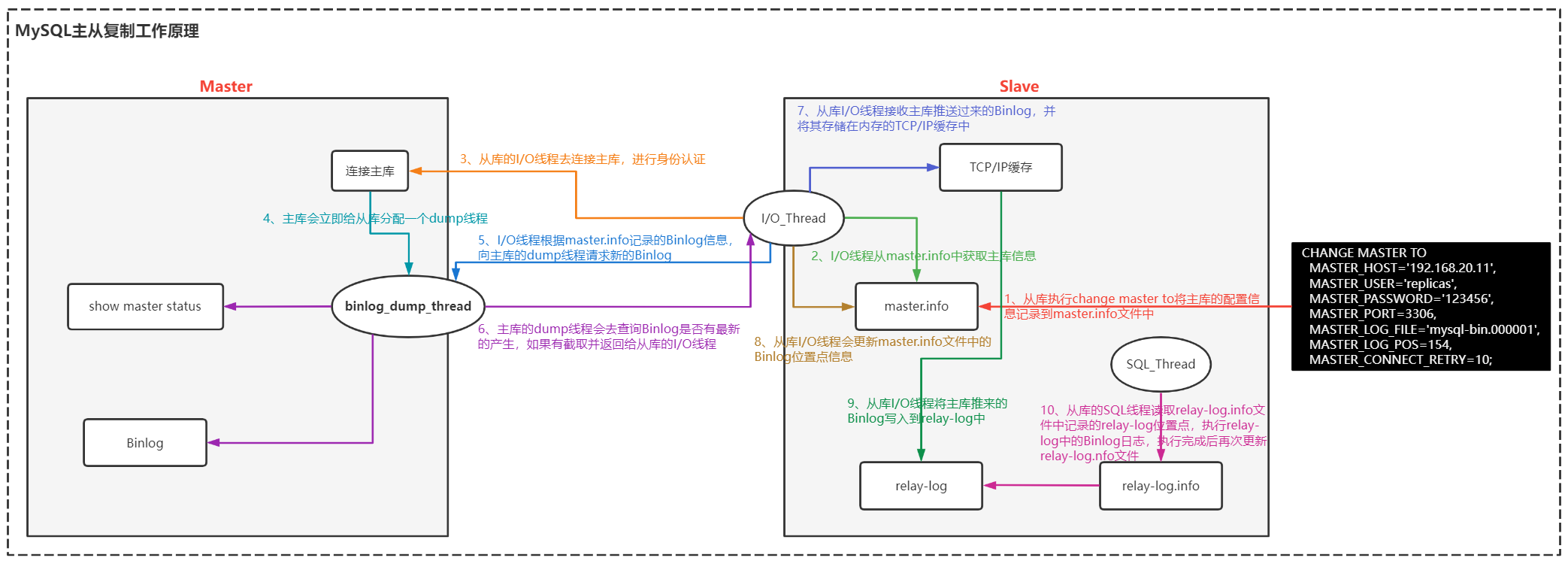
MySQL数据库主从复制集群原理概念以及搭建流程
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。主库出现问题,可以快速切换到从库提供服务。实现读写分离,降低主库的访问压力。可以在从库中执行备份,以避免备份期间影响主库服务。
编程日记 2024/01/18 16:22:43
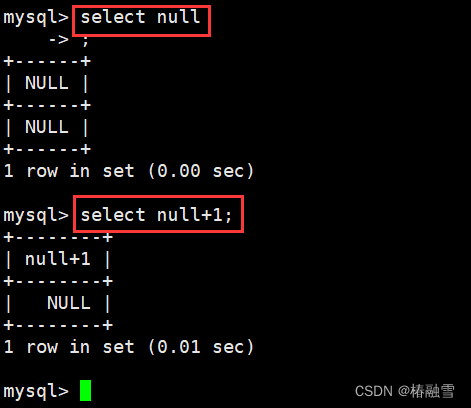
【MySQL】MySQL表的约束-空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
本文介绍了mysql中表的约束--空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
编程日记 2024/01/14 09:29:47
CentOS本地部署SQL Server数据库无公网ip环境实现远程访问
GeoServer是OGC Web服务器规范的J2EE实现,利用GeoServer可以方便地发布地图数据,允许用户对要素数据进行更新、删除、插入操作,通过GeoServer可以比较容易地在用户之间迅速共享空间地理信息。另外,GeoServer是开源软件。下面介绍GeoServer web ui 管理界面 结合cpolar 内网穿透工具实现远程访问,
编程日记 2024/01/11 10:40:30

[redis] redis的安装,配置与简单操作
Redis是一个开源、基于内存、使用C语言编写的key-value数据库,并提供了多种语言的API。它的数据结构十分丰富,主要可以用于数据库、缓存、分布式锁、消息队列等...Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;
编程日记 2024/01/08 19:32:16

Redis的IO多路复用原理解析
模拟一个tcp服务器处理30个客户socket,一个监考老师监考多个学生,谁举手就应答谁。假设你是一个监考老师,让30个学生解答一道竞赛考题,然后负责验收学生答卷,你有下面几个选择:第一种选择:按顺序逐个验收,先验收A,然后是B,之后是C、D。。。这中间如果有一个学生卡住,全班都会被耽误,你用循环挨个处理socket,根本不具有并发能力。第二种选择:你创建30个分身线程,每个分身线程检查一个学生的答案是否正确。这种类似于为每一个用户创建一个进程或者线程处理连接。
大数据 2024/01/07 16:00:47
在 Docker 中配置 MySQL 数据库并初始化 Project 项目
这样,您就完成了在 Docker 中配置 MySQL 数据库并初始化 Project 项目的过程。希望这篇博客对您有所帮助!创建目录 /project/mysql 以及 /project/mysql_data。在每个 SQL 文件中,将 AUTO_INCREMENT 修改为 1。将准备好的 SQL 文件复制到 /project/mysql 目录。将 init.sql 放到 /project/mysql 目录。在 SQL 文件中插入管理员相关数据。在 SQL 文件中插入机型相关数据。1.4. 插入管理员。
编程日记 2024/01/05 16:29:56
Redis内存使用率高,内存不足问题排查和解决
在使用redis的对象或者list队列等实例时,要记得给key设置过期时间,避免数据一直堆积无法释放。对于重要的异常数据队列的数据,要进行业务处理:重回队列或数据持久化。
编程日记 2024/01/02 14:54:27

深入理解Mysql事务隔离级别与锁机制
我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。这些问题的本质都是数据库的多事务并发问题,为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制,用一整套机制来解决多事务并发问题。接下来,我们会深入讲解这些机制,让大家彻底理解数据库内部的执行原理。
编程日记 2023/12/31 19:32:25

Redis数据一致解决方案
在高并发的业务场景下redis与mysql数据库非常容易产生数据不一致的情况,我们可以采用redis缓存延迟双删除策略达到数据的最终一致性,也可以采用一部缓存更新自定义监听mysql binblog和采用canal开源中间件实现缓存的实时一致性方案。总的来说,都是比较简单的,而且都能够达到良好的效果。
编程日记 2023/12/27 09:56:04

MySQL:为什么明明创建了索引还是走了全表扫描
为了解决线上的慢查询已经创建了索引,但是却还是走了全表扫描,甚至在测试环境能够正常运行,但是到了线上却出现了不一样的表征。
编程日记 2023/12/26 12:43:27
深入理解Mysql底层数据结构和算法
深入理解Mysql底层数据结构和算法。结合图文介绍了存储结构、mysql的索引(主键索引、非主键索引、联合索引)、B+tree、存储引擎等
编程日记 2023/12/23 21:59:15
如何在Linux设置JumpServer实现无公网ip远程访问管理界面
JumpServer 是广受欢迎的开源堡垒机,是符合 4A 规范的专业运维安全审计系统。JumpServer 帮助企业以更安全的方式管控和登录所有类型的资产,实现事前授权、事中监察、事后审计,满足等保合规要求。下面介绍如何简单设置即可使本地jump server 结合cpolar 内网穿透实现远程访问jump server 管理界面.
编程日记 2023/12/23 09:20:24


复杂 SQL 实现分组分情况分页查询
在处理数据库查询时,分页是一个常见的需求。尤其是在处理大量数据时,一次性返回所有结果可能会导致性能问题。因此,我们需要使用分页查询来限制返回的结果数量。同时,根据特定的条件筛选数据也是非常常见的需求。在本博客中,我们将探讨如何根据 camp_status 字段分为 6 种情况进行分页查询,并根据 camp_type 字段区分活动类型,返回不同的字段。我们将使用 SQL 变量来实现这一功能,并通过示例进行详细解释。
编程日记 2023/12/21 09:58:28

Hadoop3.x完全分布式模式下slaveDataNode节点未启动调整
本文描述的是在Hadoop3.1.3的完全分布式环境下,slave节点的DataNode节点未能成功启动的问题以及通过修改配置来解决的办法,希望能帮助到遇到这个问题的朋友。
大数据 2023/12/20 09:39:51