前言
之前有看过到mysql大数据量分页情况下性能会很差,但是没有探究过它的原因,今天讲一讲mysql大数据量下偏移量很大,性能很差的问题,并附上解决方式。
原因
将原因前我们先做一个试验,我做试验使用的是mysql5.7.24版本(mysql8上我也试验出来同样的问题),看看mysql是不是在偏移量比较大的时候分页会比较慢,性能比较差
版本
mysql> select version();
+-----------+
| version() |
+-----------+
| 5.7.24 |
+-----------+
1 row in set (0.00 sec)
表结构
CREATE TABLE `trace_monitor_log` (
`id` varchar(30) NOT NULL COMMENT '表主键id',
`user_id` varchar(30) DEFAULT NULL COMMENT '用户id',
`trace_id` varchar(30) DEFAULT NULL COMMENT '追踪id',
`trace_type` varchar(30) DEFAULT NULL COMMENT '追踪类型',
`path` mediumtext COMMENT '追踪路径',
`source_ip` varchar(255) DEFAULT NULL COMMENT '来源ip',
`ext_params` mediumtext COMMENT '请求扩展参数',
`costs` int(11) DEFAULT '0' COMMENT '请求耗时(毫秒)',
`exception` mediumtext COMMENT '异常信息',
`create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
PRIMARY KEY (`id`),
KEY `trace_id` (`trace_id`),
KEY `trace_type` (`trace_type`),
KEY `create_time` (`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='监控日志表';
试验过程
这个是我从测试环境找的一张日志表,里面的数据量是580万左右,我们先看看只查询普通10条数据的情况。
数据量
mysql> select count(*) from trace_monitor_log;
+----------+
| count(*) |
+----------+
| 5806836 |
+----------+
1 row in set (1.66 sec)
explain select * from trace_monitor_log order by trace_id limit 10;

可以看到没有offset偏移量的时候可以直接走索引,key是trace_id,并且只查询了10条数据。
我们在来看看如果offset是1000的时候。
explain select * from trace_monitor_log order by trace_id limit 10 offset 1000;

可以看到偏移量比较小的时候还是可以走索引,rows是1010,这时候发现虽然我们只要查询10条数据,但是查询的时候还是会扫描1000条无用的索引记录。
我们接下往下把offset加到100万
explain select * from trace_monitor_log order by trace_id limit 10 offset 1000000;

这个时候就会发现一个神奇的现象,竟然没有走索引了,type是ALL,就是全表扫描了,执行时间大概花了40多秒,性能确实很差。这里的原因,本来根据索引查出来100万条记录,然后把不需要的数据给丢弃掉,mysql会计算查询成本,发现这样走索引还没有全表扫描快,所以用了全表扫描,但是全表扫描就为了拿到十条数据显然是性能很差的。mysql并不会自动判断先根据trace_id的索引找到偏移量需要的10条数据,再根据这10条索引找到叶子节点的主键记录去回表查询数据,导致了这么差的性能。
解决方式
1.延迟关联
先使用覆盖索引的方式找到对应order by 之后的limit条索引,因为是覆盖索引,直接用的索引记录,没有回表所以很快。接着在使用join的方式,将索引记录和原表关联起来就可以查出来对应的limit条数据。
explain select * from trace_monitor_log t1 join (select trace_id from trace_monitor_log order by trace_id limit 1000000,10) t2 on t1.trace_id = t2.trace_id

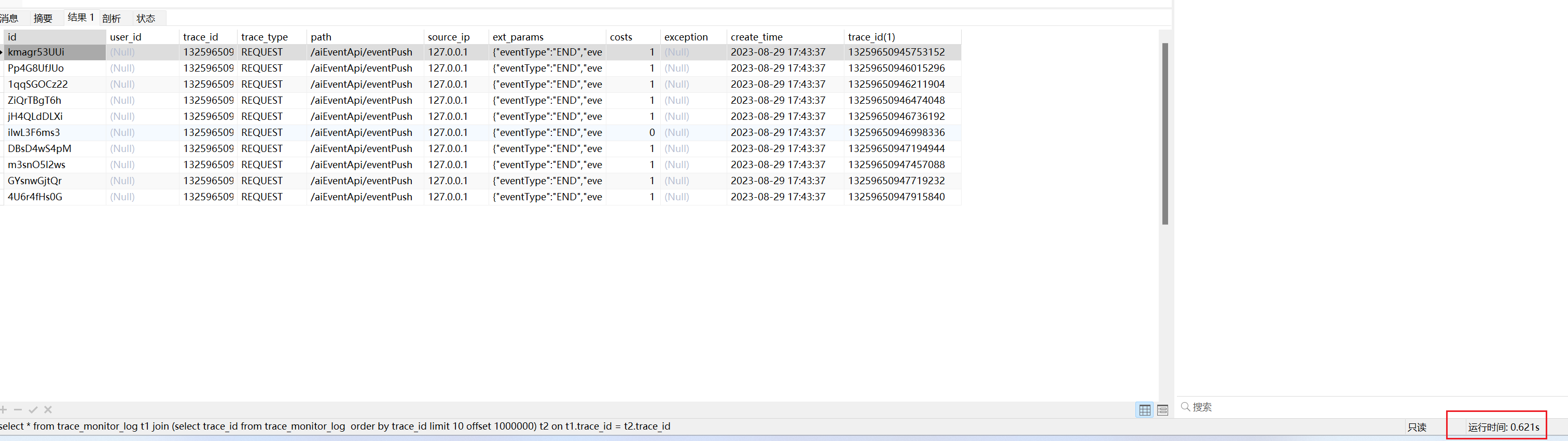
执行时间平均在500-600毫秒左右,相比全表扫描快了很多。
2.书签记录
这个概念我也是从网上看到的,还没找到具体这个概念的出处在哪里。不过不要困于这个概念,只要理解是先找到对应要查询一条索引记录(书签),再根据这个索引去范围查询对应的limit条数数据就容易理解了。
explain select * from trace_monitor_log t1 where trace_id > (select trace_id from trace_monitor_log order by trace_id limit 999999,1) order by trace_id limit 10

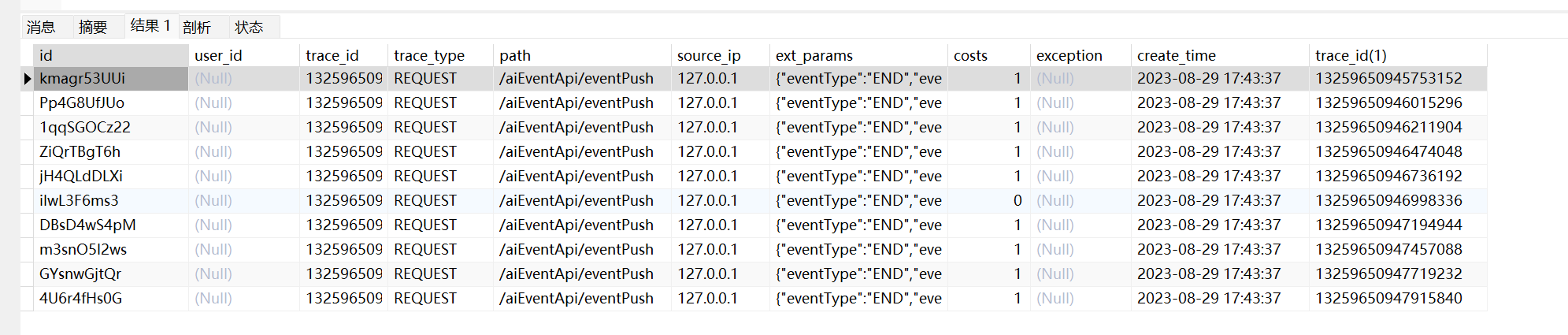
执行时间和延迟关联差不多,也都走了索引,所以性能也比较好。
参考资料
相关文章
Redis高并发分布锁实战

Redis是否为单线程?

MySQL中的高级查询

ubuntu20.04安装实时内核补丁PREEMPT_RT
mysql中文首字母排序查询
使用redis-insight连接到服务器上的redis数据库

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案
数据湖Paimon入门指南

虚拟机Windows Server 2016 安装 MySQL8
基于SQL数据库的大模型RAG实现
MySQL运行在docker容器中会损失多少性能
oracle data block , extent 和segment区别
MySQL数据库主从复制集群原理概念以及搭建流程
【MySQL】MySQL表的约束-空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
CentOS本地部署SQL Server数据库无公网ip环境实现远程访问

[redis] redis的安装,配置与简单操作

Redis的IO多路复用原理解析
在 Docker 中配置 MySQL 数据库并初始化 Project 项目
Redis内存使用率高,内存不足问题排查和解决

深入理解Mysql事务隔离级别与锁机制

Redis数据一致解决方案

MySQL:为什么明明创建了索引还是走了全表扫描
深入理解Mysql底层数据结构和算法
如何在Linux设置JumpServer实现无公网ip远程访问管理界面


复杂 SQL 实现分组分情况分页查询
