文章目录
前言
在处理数据库查询时,分页是一个常见的需求。
尤其是在处理大量数据时,一次性返回所有结果可能会导致性能问题。
因此,我们需要使用分页查询来限制返回的结果数量。同时,根据特定的条件筛选数据也是非常常见的需求。
在本博客中,我们将探讨如何根据 camp_status 字段分为 6 种情况进行分页查询,并根据 camp_type 字段区分活动类型,返回不同的字段。
我们将使用 SQL 变量来实现这一功能,并通过示例进行详细解释。
一、根据 camp_status 字段分为 6 种情况
1.1 SQL语句
要将分页结果按 6 种情况来区分。
SQL如下:
SELECT count(*) AS allCampCount,
SUM(CASE WHEN CAMP_STATUS IN ('31', '32', '35', '55') THEN 1 ELSE 0 END) AS approvalCampCount,
SUM(CASE WHEN CAMP_STATUS IN ('40', '41', '56') THEN 1 ELSE 0 END) AS toExecuteCampCount,
SUM(CASE WHEN CAMP_STATUS IN ('42', '66', '67') THEN 1 ELSE 0 END) AS executeCampCount,
SUM(CASE WHEN CAMP_STATUS IN ('50', '60') THEN 1 ELSE 0 END) AS completeCampCount,
SUM(CASE WHEN CAMP_STATUS IN ('30') THEN 1 ELSE 0 END) AS overruleCampCount
FROM BMA_MARKET_CAMP
WHERE USER_ID = #{userId}1.2 SQL解释
这是一个SQL查询,用于从名为BMA_MARKET_CAMP的表中选择和计算数据。下面是对这个查询的逐行解释:
SELECT count(*) AS allCampCount: 这一行计算了BMA_MARKET_CAMP表中的总记录数,并将这个数量命名为allCampCount。SUM(CASE WHEN CAMP_STATUS IN ('31', '32', '35', '55') THEN 1 ELSE 0 END) AS approvalCampCount: 这一行计算了CAMP_STATUS字段值为'31', '32', '35', 或 '55'的总数,并将这个数量命名为approvalCampCount。这些状态可能是表示“待批准”或“正在批准”的状态代码。SUM(CASE WHEN CAMP_STATUS IN ('40', '41', '56') THEN 1 ELSE 0 END) AS toExecuteCampCount: 这一行计算了CAMP_STATUS字段值为'40', '41', 或 '56'的总数,并将这个数量命名为toExecuteCampCount。这些状态可能是表示“待执行”或“即将执行”的状态代码。SUM(CASE WHEN CAMP_STATUS IN ('42', '66', '67') THEN 1 ELSE 0 END) AS executeCampCount: 这一行计算了CAMP_STATUS字段值为'42', '66', 或 '67'的总数,并将这个数量命名为executeCampCount。这些状态可能是表示“正在执行”或“已执行”的状态代码。SUM(CASE WHEN CAMP_STATUS IN ('50', '60') THEN 1 ELSE 0 END) AS completeCampCount: 这一行计算了CAMP_STATUS字段值为'50'或'60'的总数,并将这个数量命名为completeCampCount。这些状态可能是表示“已完成”或“完全完成”的状态代码。SUM(CASE WHEN CAMP_STATUS IN ('30') THEN 1 ELSE 0 END) AS overruleCampCount: 这一行计算了CAMP_STATUS字段值为'30'的总数,并将这个数量命名为overruleCampCount。这个状态可能是表示“已否决”或“推翻”的状态代码。FROM BMA_MARKET_CAMP WHERE USER_ID = #{userId}: 最后,指定了数据来源的表是BMA_MARKET_CAMP,并且只选择那些USER_ID字段等于给定参数#{userId}的记录。
总的来说,这个查询是为了获取与特定用户相关的各种 camp 状态的数量。
二、分页 SQL 实现
2.1 SQL语句
这是整个 SQL 语句,下面会细细讲解!
SQL如下:
SELECT TOUCH_TYPE,
t1.CAMP_TYPE,
NAME,
SMS_CONTENT,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
NULL
ELSE
START_DATE END AS START_DATE,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
EXE_START_TIME
ELSE
START_TIME END AS START_TIME,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
NULL
ELSE
END_DATE END AS END_DATE,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
NULL
ELSE
END_TIME END AS END_TIME
FROM CAMP t1
left join CAMP_INFO t2 on t1.ID = t2.CAMP_ID
WHERE CAMP_STATUS in
<foreach close=")" collection="campStatus" item="campStatus" open="(" separator=", ">
#{campStatus,jdbcType=VARCHAR}
</foreach>
AND USER_ID = #{userId}2.2 根据 camp_type 区分返回字段
- 当活动类型为 0 时,只需要返回 EXE_STRAR_TIME 字段。
- 其他的活动类型要返回 START_DATE , START_TIME , END_DATE , END_TIME 四个字段。
SQL部分如下:
CASE
WHEN t1.CAMP_TYPE = '0' THEN
NULL
ELSE
START_DATE END AS START_DATE,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
EXE_START_TIME
ELSE
START_TIME END AS START_TIME,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
NULL
ELSE
END_DATE END AS END_DATE,
CASE
WHEN t1.CAMP_TYPE = '0' THEN
NULL
ELSE
END_TIME END AS END_TIME2.3 根据 camp_status 字段分为 6 种情况
解释如下:
WHERE CAMP_STATUS in: 这表示我们要在SQL查询中添加一个条件,即CAMP_STATUS的值必须在给定的列表中。<foreach ...>: 这是MyBatis的循环语句,用于遍历集合或数组,并动态生成SQL的部分内容。collection="campStatus": 这表示我们要遍历的集合或数组的名称是campStatus。item="campStatus": 在每次循环中,当前的元素值会被赋值给名为campStatus的变量。open="("和close=")": 这些指示MyBatis在循环开始前添加一个左括号(,并在循环结束后添加一个右括号)。separator=", ">: 这表示在每次循环后,我们添加一个逗号,`和一个空格。#{campStatus,jdbcType=VARCHAR}: 这是MyBatis的参数占位符。它表示我们要将当前循环中的campStatus变量的值插入到SQL查询中。jdbcType=VARCHAR指定了参数的类型,这里假设它是VARCHAR类型。
综上所述,这个片段的作用是动态生成一个SQL查询的条件,该条件检查CAMP_STATUS是否在给定的campStatus列表中。
SQL部分如下:
SELECT
...
FROM
...
WHERE CAMP_STATUS in
<foreach close=")" collection="campStatus" item="campStatus" open="(" separator=", ">
#{campStatus,jdbcType=VARCHAR}
</foreach>
...这里传入的是一个 list,这样传入即可:

定义一个请求类:
@Data
public class CampDataInfoInIndexRequest {
List<Integer> campStatusList;
private int pageNum;
private int pageSize;
}三、分页实现
实现一个 PageUtils 。
代码如下:
public class PageUtils {
/**
* 泛型方法 进行结果的分页
* 当pageNum*pageSize>result.size那么就取result的最后一页数据
* 否则就取相应页的数据
*
* @param result
* @param pageNum
* @param pageSize
* @return
*/
public static <T> List<T> pageResult(List<T> result, Integer pageNum, Integer pageSize) {
if (Objects.isNull(result) || result.size() == 0) {
return result;
}
int maxSize = result.size();
if (maxSize < pageNum * pageSize + pageSize) {
int maxPage = maxSize / pageSize;
return result.subList(maxPage * pageSize, result.size());
}
return result.subList(pageNum * pageSize, (pageNum + 1) * pageSize);
}
}再通过一个 PageResultVO 返回即可。
代码如下:
@Data
public class PageResultVO {
private Integer total;
private List<?> list;
}
//ServiceImpl层
List<CampInfoVO> infoList = PageUtils.pageResult(info, pageNum, pageSize);
PageResultVO pageResultVO = new PageResultVO();
pageResultVO.setTotal(info.size());
pageResultVO.setList(infoList);
四、总结
在这篇博客中,我们探讨了如何使用SQL实现分页查询,并根据camp_status和camp_type字段进行筛选。
通过使用变量和适当的SQL语法,我们可以根据特定的条件动态地构建查询,从而返回满足我们需求的结果。
通过这种方式,我们可以灵活地构建和执行查询,以满足不同的需求。这对于处理大量数据和实现复杂的筛选条件非常有用。
希望这篇博客能帮助你更好地理解和应用SQL分页查询和筛选功能!
相关文章
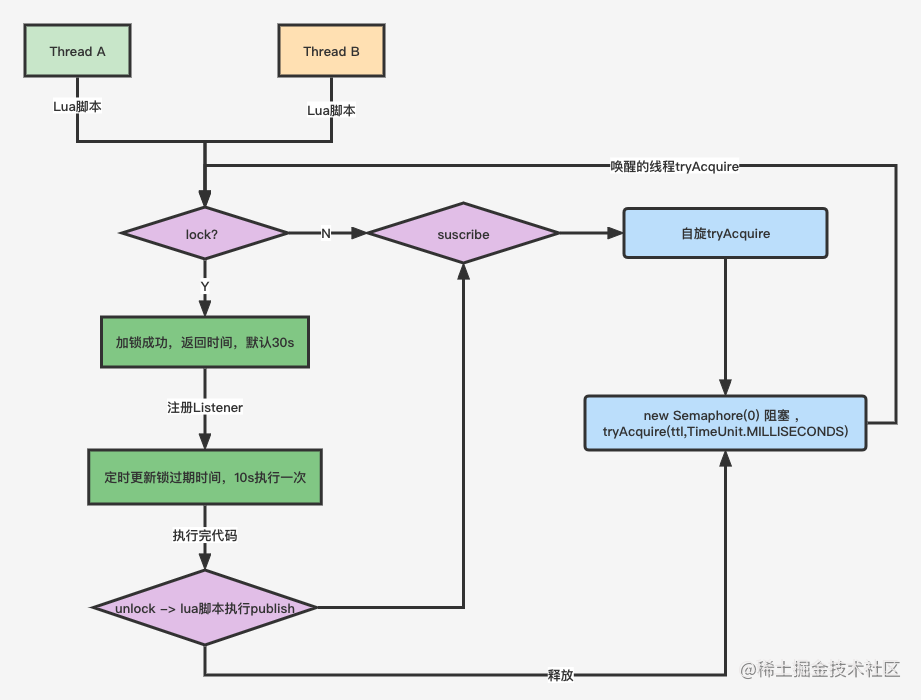
Redis高并发分布锁实战
Redis分布式锁自己去实现可能会出现几个问题没有在finally显示释放锁,当客户端挂掉了,锁没有被及时删除,这样会导致死锁问题,它这个是需要我们显示的释放锁假如此时我们设置过期时间,但是我们用的是同一个key,就可能出现下一个线程删除上一个线程的锁,但是上一个线程还没有执行完,它这个需要key是不能重复的假如我们既设置了过期时间也指定了不同的key,此时可能因为网络延迟出现上一个线程删除下一个线程的锁,也就是说业务执行的时间超过了锁过期的时间,它这个需要一个锁续命的功能。
编程日记 2024/02/28 09:11:20

Redis是否为单线程?
在深入讨论Redis是否为单线程之前,我们先来了解一下Redis的基本架构。Redis采用了基于内存的数据存储方式,数据存储在内存中,并通过持久化机制将数据定期写入磁盘。客户端:与Redis进行通信的应用程序。Server:负责处理客户端请求、执行命令和管理数据。数据结构:Redis支持多种数据结构,如字符串、列表、哈希表等。事件处理器:用于处理网络事件和命令请求。
编程日记 2024/02/28 09:10:26

MySQL中的高级查询
通过条件查询可以查询到符合条件的数据,但如同要实现对字段的值进行计算、根据一个或多个字段对查询结果进行分组等操作时,就需要使用更高级的查询,MySQL提供了聚合函数、分组查询、排序查询、限量查询、内置函数以实现更复杂的查询需求。接下来将针对这些高级查询的知识进行讲解。
编程日记 2024/02/24 08:33:50

ubuntu20.04安装实时内核补丁PREEMPT_RT
下载实时内核补丁,我下载patch-5.15.148-rt74.patch.sign和patch-5.15.148-rt74.patch.xz。通过以下指令看具体报错并输出日志到make.log:make -j1 deb-pkg 2>&1 | tee ~/make.log。比较幸运没遇到问题,重启进入后,启动页面没有变化,还是进入ubuntu,但是查看内核版本已经自动变到5.15.148。我下载linux-5.15.148.tar.xz和linux-5.15.148.tar.sign。
编程日记 2024/02/23 08:40:54

mysql中文首字母排序查询
MySQL中的排序涉及到字符集和排序规则。默认情况下,MySQL按照ASCII码对字符进行排序,数字>字母>中文。但是,特殊字符(非字母、数字、中文)的排序需要一些额外处理。匹配到非字母数字中文的内容,做排序,字母数字中文为null,排序优先级最高,排在上面。为什么用HEX()函数做十六进制编码?因为中文用常规的正则不能匹配到结果。试过SUBSTRING、LEFT等,都不能完美实现多中文的首字母排序。为什么要把字母数字中文放在一起匹配?因为处理复杂度会更高。这样可以处理更复杂的排序需求。
编程日记 2024/02/20 22:31:36
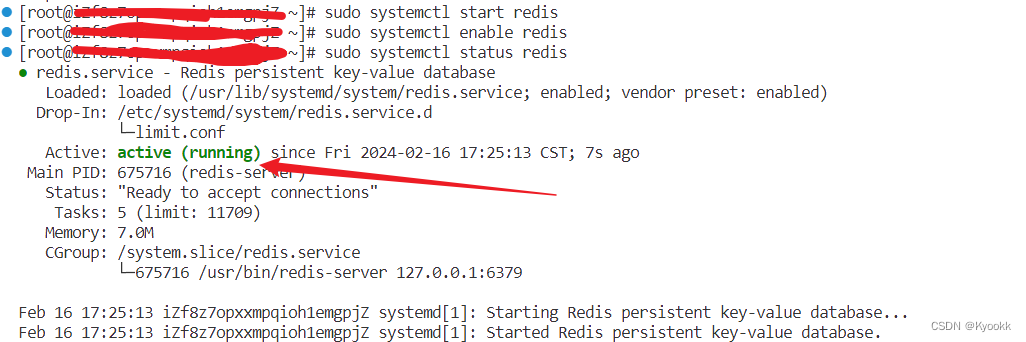
使用redis-insight连接到服务器上的redis数据库
我们现在虽然安装好了redis数据库,但是外界是连接不到的,我们需要打破这个限制!设置完之后,可以按以下图的命令查看,redis的密码是不是起作用了。的更改,并退出编辑器。在网上下载好redis-insight的客户端,打开。默认情况下,它可能被设置为只监听本地连接,如。这允许在没有进行身份验证的情况下接受外部连接。(3)为了增强安全性,强烈建议设置访问密码。三、使用redis-insight连接数据库。1.查找redis的配置文件。指令,并确保将其设置为。替换为你自己的强密码。
编程日记 2024/02/16 20:32:27

二叉搜索树删除操作的递归与非递归写法
对于二叉搜索树的删除操作,主要分为以下3种情况讨论:1、删除的结点没有左右孩子2、删除的结点只有一个孩子3、删除的结点有左右孩子。
编程日记 2024/02/13 19:59:36

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案
mysql8登录第一次遇到MYSQL_ROOT_PASSWORD时会自动把该密码尽兴登录,生成一个秘钥放在mysql的数据文件里面,命令里带的MYSQL_ROOT_PASSWORD密码是个参数,除了第一次运行mysql带上会设置密码生成秘钥,其他次启动而不是设置mysql的密码,而是作为参数去验证这个最初的秘钥是否核对正确,于是我进入挂载的data目录,发现我的猜想是对的。通过docker将服务部署完后,navicat连接报错,密码错误,于是我尝试进入mysql容器登录 发现也报错。
编程日记 2024/02/08 18:08:55
数据湖Paimon入门指南
如果用户建表时指定'merge-engine' = 'partial-update',那么就会使用部分更新表引擎,可以做到多个 Flink 流任务去更新同一张表,每条流任务只更新一张表的部分列,最终实现一行完整的数据的更新,对于需要拉宽表的业务场景,partial-update 非常适合此场景,而且构建宽表的操作也相对简单。这种方式的成本相对较高,同时官方不建议这样使用,因为下游任务在 State 中存储一份全量的数据,即每条数据以及其变更记录都需要保存在状态中。流式查询将不断产生最新的更改。
编程日记 2024/02/05 08:46:01

虚拟机Windows Server 2016 安装 MySQL8
在虚拟机Windows Server 2016 中 安装MySQL8.0 并通过本机Navicat远程连接
编程日记 2024/02/04 09:56:57
Java开发四则运算-使用递归和解释器模式
四则运算Expression implement。ExpressionParser 核心实现类。Context 编写测试代码。
编程日记 2024/02/03 10:54:40
基于SQL数据库的大模型RAG实现
检索增强生成 (RAG) 涉及从外部数据库获取当前或上下文相关信息,并在请求大型语言模型 (LLM) 生成响应时将其呈现给大型语言模型 (LLM) 的过程。这种方法有效地解决了生成不正确或误导性信息的问题。你能够存储专有业务数据或全局知识,并使你的应用程序能够在响应生成阶段为 LLM 检索此数据。
编程日记 2024/02/02 15:05:48
MySQL运行在docker容器中会损失多少性能
自从使用docker以来,就经常听说MySQL数据库最好别运行在容器中,性能会损失很多。一些之前没使用过容器的同事,对数据库运行在容器中也是忌讳莫深,甚至只要数据库跑在容器中出现性能问题时,首先就把问题推到容器上。
编程日记 2024/02/02 14:07:43

Mysql大数据量分页优化
之前有看过到mysql大数据量分页情况下性能会很差,但是没有探究过它的原因,今天讲一讲mysql大数据量下偏移量很大,性能很差的问题,并附上解决方式。
编程日记 2024/01/29 17:55:30
oracle data block , extent 和segment区别
总结来说,Data block是数据库中最小的逻辑存储单位,用于存储实际的数据记录;Extent是由若干个连续的Data blocks组成的区域,表示一段连续的存储空间;data block是数据库中最小的逻辑存储单元。当数据库的对象需要更多的物理存储空间时,连续的data block就组成了extent . 一个数据库对象拥有的所有extents被称为该对象的segment.Data block、extent和segment是数据库中不同层次的数据存储和管理单位,它们各自具有不同的功能和特点。
编程日记 2024/01/24 10:38:37
Centos系统上安装PostgreSQL和常用PostgreSQL功能
PostgreSQL安装成功之后,会默认创建一个名为postgres的Linux用户,初始化数据库后,会有名为postgres的数据库,来存储数据库的基础信息,例如用户信息等等,相当于MySQL中默认的名为mysql数据库。权限代码:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、USAGE。为了方便我们使用postgres账号进行管理,我们可以修改该账号的密码。
编程日记 2024/01/21 15:11:21
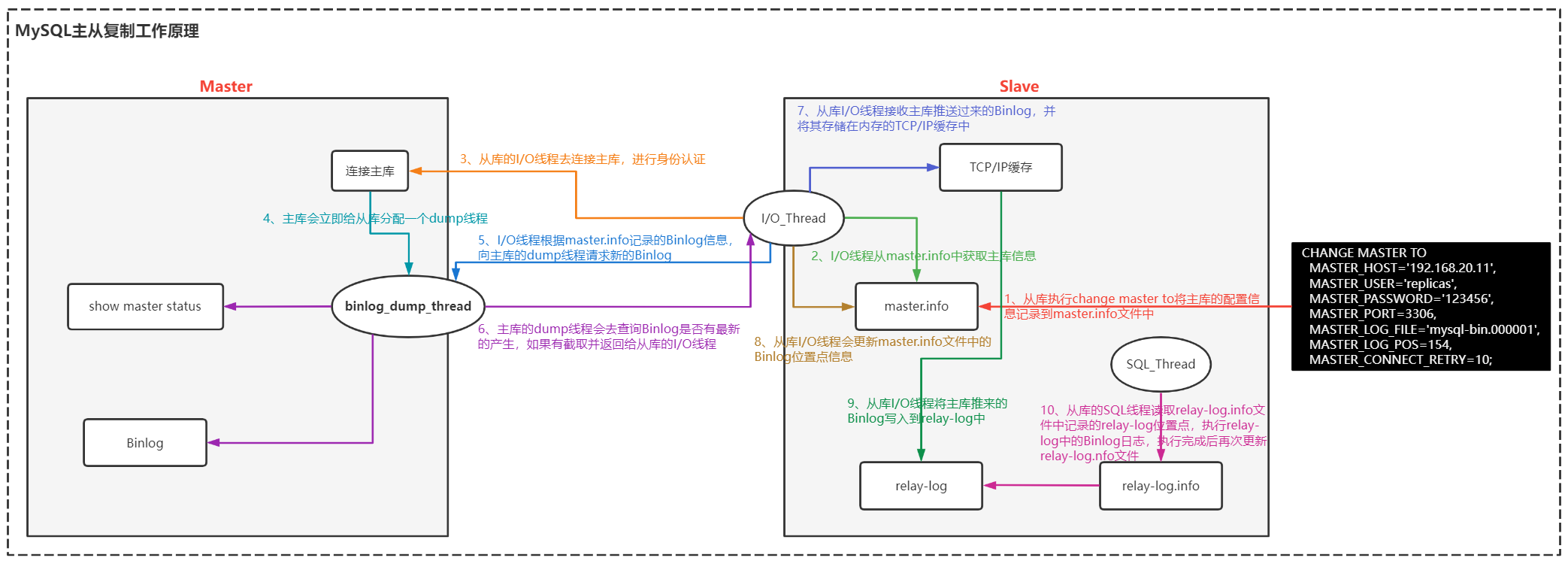
MySQL数据库主从复制集群原理概念以及搭建流程
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。主库出现问题,可以快速切换到从库提供服务。实现读写分离,降低主库的访问压力。可以在从库中执行备份,以避免备份期间影响主库服务。
编程日记 2024/01/18 16:22:43
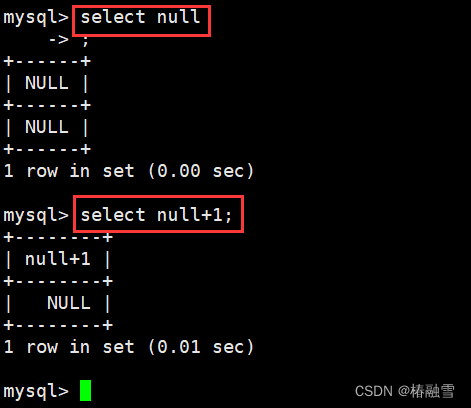
【MySQL】MySQL表的约束-空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
本文介绍了mysql中表的约束--空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
编程日记 2024/01/14 09:29:47
CentOS本地部署SQL Server数据库无公网ip环境实现远程访问
GeoServer是OGC Web服务器规范的J2EE实现,利用GeoServer可以方便地发布地图数据,允许用户对要素数据进行更新、删除、插入操作,通过GeoServer可以比较容易地在用户之间迅速共享空间地理信息。另外,GeoServer是开源软件。下面介绍GeoServer web ui 管理界面 结合cpolar 内网穿透工具实现远程访问,
编程日记 2024/01/11 10:40:30

[redis] redis的安装,配置与简单操作
Redis是一个开源、基于内存、使用C语言编写的key-value数据库,并提供了多种语言的API。它的数据结构十分丰富,主要可以用于数据库、缓存、分布式锁、消息队列等...Redis服务器程序是单进程模型,也就是在一台服务器上可以同时启动多个Redis进程,Redis的实际处理速度则是完全依靠于主进程的执行效率。若在服务器上只运行一个Redis进程,当多个客户端同时访问时,服务器的处理能力是会有一定程度的下降;
编程日记 2024/01/08 19:32:16

Redis的IO多路复用原理解析
模拟一个tcp服务器处理30个客户socket,一个监考老师监考多个学生,谁举手就应答谁。假设你是一个监考老师,让30个学生解答一道竞赛考题,然后负责验收学生答卷,你有下面几个选择:第一种选择:按顺序逐个验收,先验收A,然后是B,之后是C、D。。。这中间如果有一个学生卡住,全班都会被耽误,你用循环挨个处理socket,根本不具有并发能力。第二种选择:你创建30个分身线程,每个分身线程检查一个学生的答案是否正确。这种类似于为每一个用户创建一个进程或者线程处理连接。
大数据 2024/01/07 16:00:47
在 Docker 中配置 MySQL 数据库并初始化 Project 项目
这样,您就完成了在 Docker 中配置 MySQL 数据库并初始化 Project 项目的过程。希望这篇博客对您有所帮助!创建目录 /project/mysql 以及 /project/mysql_data。在每个 SQL 文件中,将 AUTO_INCREMENT 修改为 1。将准备好的 SQL 文件复制到 /project/mysql 目录。将 init.sql 放到 /project/mysql 目录。在 SQL 文件中插入管理员相关数据。在 SQL 文件中插入机型相关数据。1.4. 插入管理员。
编程日记 2024/01/05 16:29:56
Redis内存使用率高,内存不足问题排查和解决
在使用redis的对象或者list队列等实例时,要记得给key设置过期时间,避免数据一直堆积无法释放。对于重要的异常数据队列的数据,要进行业务处理:重回队列或数据持久化。
编程日记 2024/01/02 14:54:27

深入理解Mysql事务隔离级别与锁机制
我们的数据库一般都会并发执行多个事务,多个事务可能会并发的对相同的一批数据进行增删改查操作,可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。这些问题的本质都是数据库的多事务并发问题,为了解决多事务并发问题,数据库设计了事务隔离机制、锁机制、MVCC多版本并发控制隔离机制,用一整套机制来解决多事务并发问题。接下来,我们会深入讲解这些机制,让大家彻底理解数据库内部的执行原理。
编程日记 2023/12/31 19:32:25
Jupyter Notbook+cpolar内网穿透实现公共互联网访问使用数据分析工作
在数据分析工作中,使用最多的无疑就是各种函数、图表、代码和说明文档,这些复杂的内容不仅让使用的人头晕脑胀,也让普通的聊天工具一脸蒙圈。沟通工具不给力,就没法协同办公,可数据分析又离不开多人配合,所以Jupyter Notebook就成为大部分数据工作人员的必备工具。正如之前所说,Jupyter Notebook很适应复杂内容的沟通,因此现在也在机器学习、深度学习和教育工作中获得广泛应用。但Jupyter Notebook也有缺陷,就是被局限在局域网范围。
编程日记 2023/12/29 09:56:39

Redis数据一致解决方案
在高并发的业务场景下redis与mysql数据库非常容易产生数据不一致的情况,我们可以采用redis缓存延迟双删除策略达到数据的最终一致性,也可以采用一部缓存更新自定义监听mysql binblog和采用canal开源中间件实现缓存的实时一致性方案。总的来说,都是比较简单的,而且都能够达到良好的效果。
编程日记 2023/12/27 09:56:04