问题现象
表面现象是系统登录突然失效,排查原因发现,使用redis查询用户信息异常,从而定位到redis问题
if (PassWord.equals(dbPassWord)) {
map.put("rtn", 1);
map.put("value", validUser);
session.setAttribute("username", user.getUsername());
redisWarehouseControlUtil.addObjectData(user.getUsername(),user.getUsername(),30);
}排查原因
我的redis使用的是华为云的redis分布式缓存服务,所以在问题排查方面,我们可以结合华为云提供的丰富的分析诊断工具来辅助排查解决问题。
1、问题定位到redis上,登陆redis服务器,发现服务器内存使用率100%。
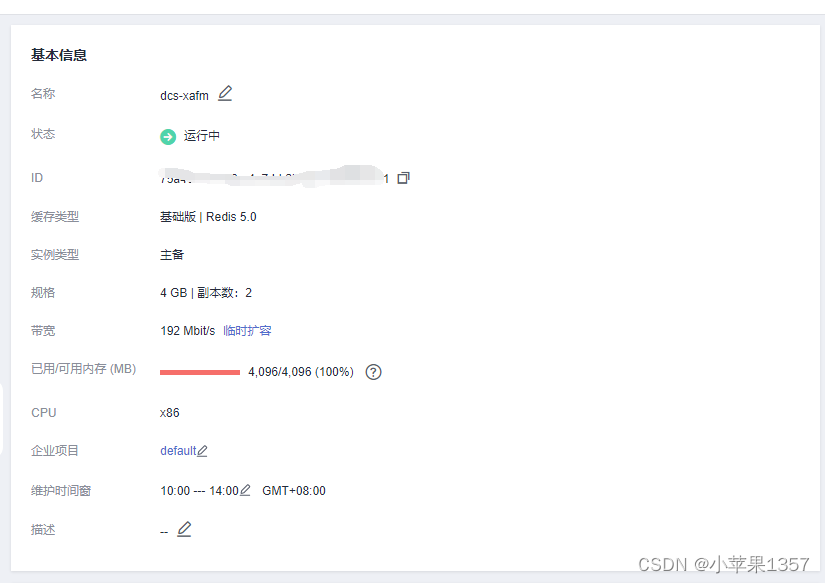
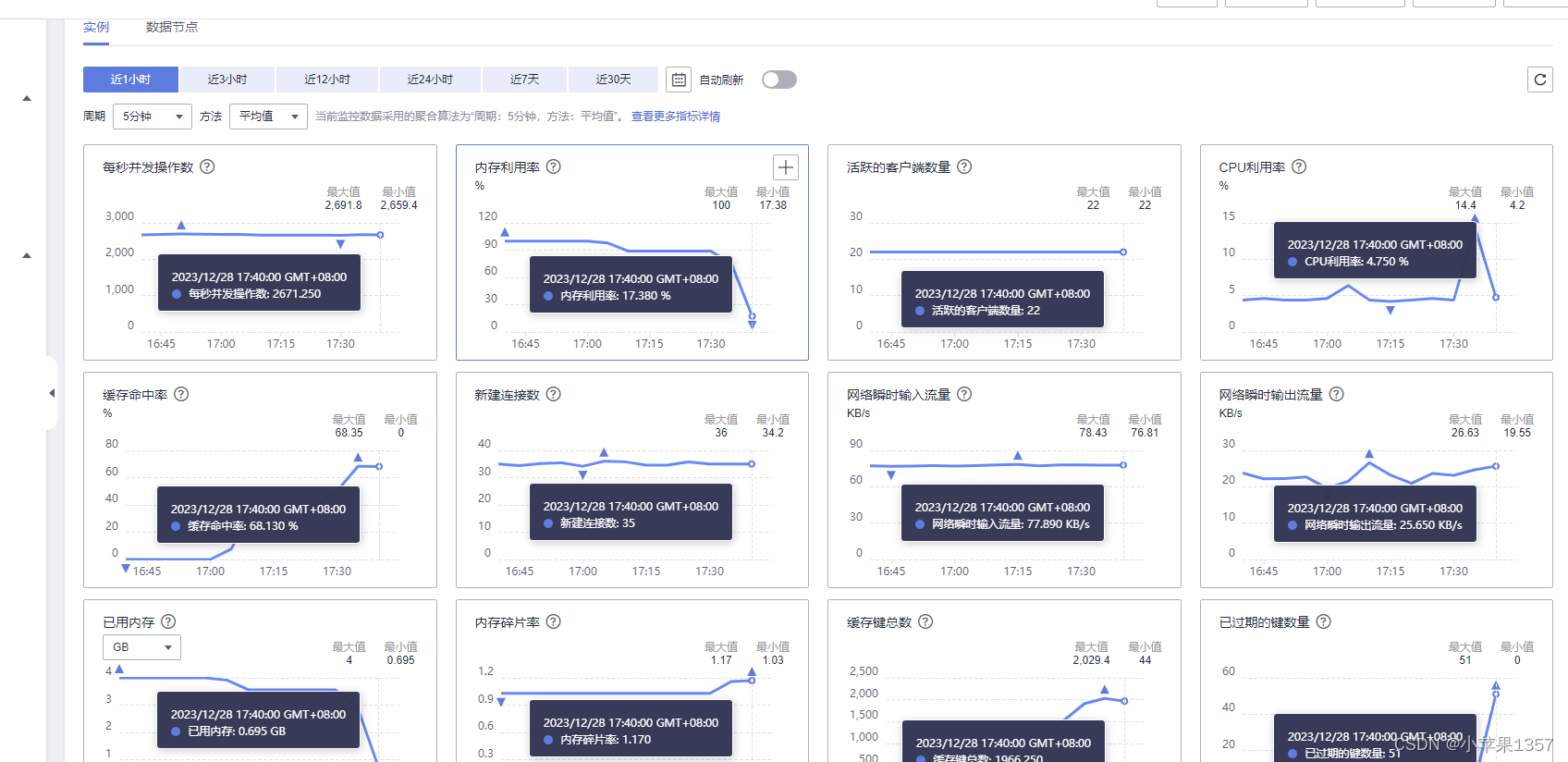
2、使用华为云的性能监控功能,查询指定时段的内存使用率信息。发现“内存利用率”指标持续接近100%。查询内存使用率超过95%的时间段内,“已逐出的键数量”和“命令最大时延”,均呈现显著上升趋势,表明存在内存不足的问题。
当内存不足时,可能导致Key频繁被逐出、响应时间上升、QPS(每秒访问次数)不稳定等问题,基本上redis服务已经瘫痪。

3、先使用实例诊断功能,大体分析一下可能得问题原因:主要还是内存占用过高问题。

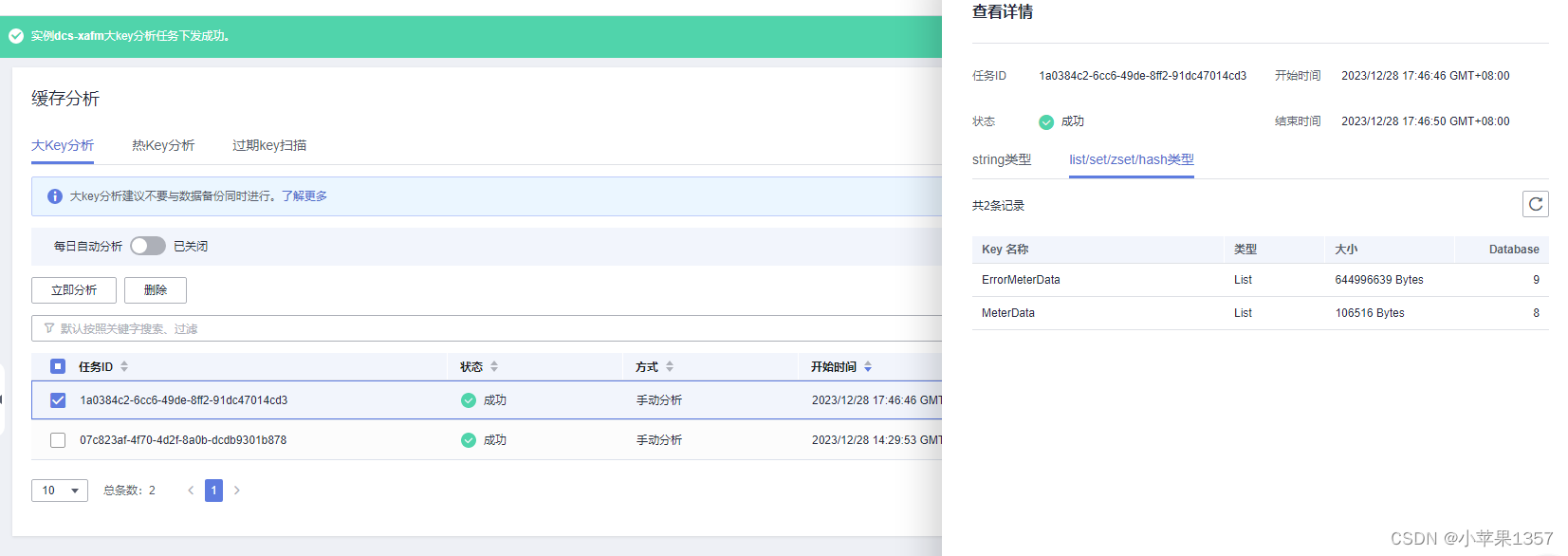
4、使用华为云的缓存分析功能,执行大Key扫描,发现另一个项目的ErrorMeterData key,他是一个list队列,竟然存储数据占了2.6G,还有两个key存储数据占用了几百M,就是这三个key把服务器的内存占满了。
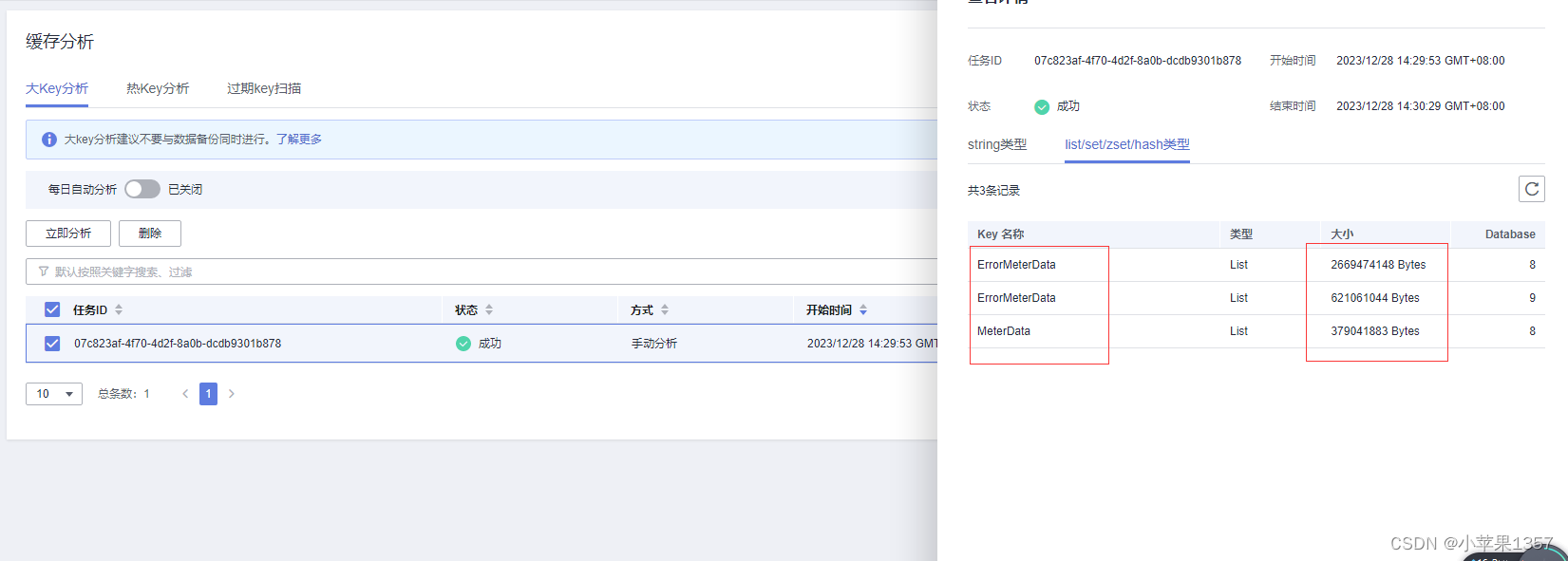
5、分析查找原因:去代码中查找ErrorMeterData key对应的功能,找到了问题所在,这个key存储的是解析出现异常的数据队列,但问题是,开发这个功能的同事,并没有给这个key设置过期时间,也没有对这个异常数据队列的数据进行其他处理,就一直存在这个队列中,随着时间的增长,以及异常数据的日复一日的不断累加,会导致存储数据太多,终于内存被占满。这是一个非常严重的bug。
问题就出在:redisMeterDataUtil.AddErrorMeterDataList(baseMessage);这一步
private void MeterDataExtractProcess() {
boolean rtn = false;
while (!needClose) {
// 普通表数据的解析
try {
BaseMessage baseMessage = redisMeterDataUtil.getMeterData();
if (baseMessage != null) {
if (!baseMessage.getFunctionCode().equals("") && baseMessage.getFunctionCode() != null) {
switch (baseMessage.getFunctionCode()) {
// 温控面板解析 --主动上传 批量
case FunctionCode.UploadTcStateData:
UploadTcStateDataMessage tcStateDataMessage =
new UploadTcStateDataMessage(baseMessage);
rtn = tcStateDataService.addUploadTcStateDataDataMessage(tcStateDataMessage);
break;
// //根据表号读取,单条 温控面板解析
case FunctionCode.getTcStateData:
ReplyTcStateDataMessage replyTcStateDataMessage =
new ReplyTcStateDataMessage(baseMessage);
rtn = tcStateDataService.addTcStateDataMessage(replyTcStateDataMessage);
break;
default:
break;
}
if (rtn == false) {
// 解析方法存储失败,将数据添加到错误队列
redisMeterDataUtil.AddErrorMeterDataList(baseMessage);
}
} else {
// 若队列数据为空,则线程休眠1s后继续执行
ThreadSleep(1000);
continue;
}
}
} catch (Exception e) {
logger.error("MeterDataExtractServer--表数据redis解析出错"+e.getMessage());
ThreadSleep(1000);
}public void AddErrorMeterDataList(BaseMessage baseMessage) {
addData(ErrorMeterDataListSign, baseMessage);
}
private void addData(String type, Object data) {
String key = type;
redisTemplate.opsForList().leftPush(key, data);
}6、如果你没有使用华为云或者阿里云的专门的redis服务,而是自己在服务器搭建的Redis服务。那么排查问题的步骤和方法,大体可以分为几步:
- 查询诊断服务的CPU、内存、硬盘、网络等是否正常
- 查看日志分析异常问题
- 如果是内存占满问题,则可以在Redis-cli客户端连接实例后,执行大key扫描命令或者执行过期key扫描(过期key扫描会对键空间进行Redis的scan扫描,释放内存中已过期但是由于惰性删除机制而没有释放的内存空间),并查看key的内存占用情况。并对内存占用过大的key进行处理。
如果你想扫描Redis实例中的大key,你可以使用
SCAN命令结合TYPE命令来获取每个键的类型,并根据键的类型获取其大小。以下是一个示例的命令:
bash复制代码
redis-cli SCAN 0 MATCH * COUNT 1000 | while read key; do type=$(redis-cli TYPE $key); size=$(redis-cli -c GET $key | wc -c); echo "$key: $type, Size: $size"; done这个命令将使用
SCAN命令迭代整个数据库,并对每个键执行TYPE命令来获取键的类型。然后,对于字符串类型的键,使用GET命令获取其值,并使用wc -c命令计算其长度。最后,将键、类型和大小输出到终端。另外,如果你想查看Redis实例的output buffer占用情况,你可以使用
CONFIG GET output-buffer-limit命令来获取output buffer的配置信息。该命令将返回output buffer的配置参数,包括类型、大小和阈值。请注意,上述命令中的
redis-cli -c GET $key是用于获取字符串类型的键的大小。对于其他类型的键,你可能需要使用其他命令或方法来获取其大小。
处理措施
1、为内存占用过大的key设置过期时间,这样数据就不会一直存储在队列中
(1)比较紧急想要恢复redis,且队列中的数据不重要,则可以直接链接redis,执行命令
EXPIRE key seconds:设置键的过期时间(以秒为单位),过期后键将被自动删除。或者
DEL key:删除指定键
(2)在代码中为key设置过期时间
/**
* 设置设备缓存过期时间(分钟)
* @param type 设备分类
*/
private void setExpireTime(String type,int cacheTime) {
String key = type;
redisTemplate.expire(key,cacheTime,TimeUnit.MINUTES);
}
/**
* 设置表数据缓存失效时间list集合
*/
public void setMeterInfoExpire() {
setExpireTime(MeterDataListSign,deviceCacheTime);
}2、业务逻辑上将这个异常数据队列的数据,重新返回处理队列,设置返回次数,如果超过三次以上,还是没有被正常队列处理掉,则将异常数据持久化,并删除redis中的该异常数据。
我的实际业务中,异常数据没有重回队列处理的必要了,所以我的业务代码中,直接不在用redis队列存储异常数据,而是直接将异常数据持久化存储到mongodb中。
if (rtn == false) {
// 解析方法存储失败,将数据添加到错误队列----不再存在redis,直接持久化存储到mongodb
//redisMeterDataUtil.AddErrorMeterDataList(baseMessage);
tcErrorMessageHistoryUtil.addMessage(baseMessage);
}3、设置key的过期时间后,过了一段时间内存恢复正常
总结
在使用redis的对象或者list队列等实例时,要记得给key设置过期时间,避免数据一直堆积无法释放。对于重要的异常数据队列的数据,要进行业务处理:重回队列或数据持久化。
相关文章

【JS】【Vue3】【React】获取鼠标位置的方法:JavaScript、Vue 3和React示例
Redis高并发分布锁实战

Redis是否为单线程?

Springboot中如何记录好日志
Java实战:定制Spring MVC拦截器链
MySQL中的高级查询

ubuntu20.04安装实时内核补丁PREEMPT_RT
【Vue3】使用ref与reactive创建响应式对象
如何设置页面恢复运行事件触发回调
日常遇到Maven出现依赖版本/缓存问题通用思路。
mysql中文首字母排序查询
什么是tomcat?tomcat是干什么用的?
C# winfrom中excel文件导入导出
使用redis-insight连接到服务器上的redis数据库
maven实战:Centos7.9原生安装maven
Java 与 JavaScript 的区别与联系
C语言中的作用域与生命周期
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务
Python和Java的区别(不断更新)

服务器与电脑的区别?
windows下ngnix自启动(借助工具winSw)
synchronized 和 Lock 有什么区别?synchronized 和 ReentrantLock 区别是什么?说一下 atomic 的原理?
数据湖Paimon入门指南
Java开发四则运算-使用递归和解释器模式
基于SQL数据库的大模型RAG实现
MySQL运行在docker容器中会损失多少性能