检索增强生成 (RAG) 涉及从外部数据库获取当前或上下文相关信息,并在请求大型语言模型 (LLM) 生成响应时将其呈现给大型语言模型 (LLM) 的过程。 这种方法有效地解决了生成不正确或误导性信息的问题。 你能够存储专有业务数据或全局知识,并使你的应用程序能够在响应生成阶段为 LLM 检索此数据。
1、RAG有什么帮助?
LLM 缺乏领域知识,但我们可以通过利用 RAG 从数据库中检索上下文信息并将其与用户输入一起传递给 LLM 并生成丰富的相关响应来填补这一空白。
在本文中,我们将了解如何使用 LangChain 连接到我们的 SQL 数据库、检索上下文信息、将用户查询和上下文一起传递给 LLM 并生成准确的响应。
2、案例概览
我们将为职业介绍所构建一个定制的 QA 聊天机器人,帮助用户获取就业市场的相关信息。 用户可能想了解热门职位、特定角色在特定领域的受欢迎程度等。
我们使用 Langchain 作为框架、MySQL 数据库和 OpenAI 的 LLM 来构建我们的应用程序。
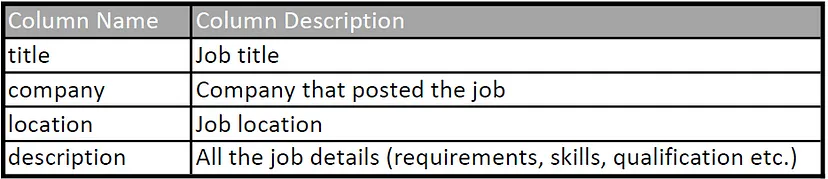
我们的数据库由一个包含以下列的表组成:
让我们从实施开始。
安装依赖项:
pip install langchain langchain-experimental openai pymysql导入必要的包:
from langchain.utilities import SQLDatabase
from langchain.llms import OpenAI
from langchain_experimental.sql import SQLDatabaseChain
from langchain.prompts import PromptTemplate
from langchain.prompts.chat import HumanMessagePromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage初始化LLM:
OPENAI_API_KEY = "your-key-here"
llm = ChatOpenAI(temperature=0, openai_api_key=OPENAI_API_KEY)我们使用 Langchain 的 ChatOpenAI,它使用 OpenAI 的 gpt3.5-turbo 模型。
数据库设置:
host = 'localhost'
port = '3306'
username = 'root'
password = 'password'
database_schema = 'agency_db'
mysql_uri = f"mysql+pymysql://{username}:{password}@{host}:{port}/{database_schema}"
db = SQLDatabase.from_uri(mysql_uri, include_tables=['job_details'],sample_rows_in_table_info=2)
db_chain = SQLDatabaseChain.from_llm(llm, db, verbose=True)我们首先构造一个 URI 来连接数据库,这里我使用 pymysql 作为连接 mysql 的驱动程序,但你可以根据你的数据库方言更改它,例如 - postgresql 数据库的连接字符串将与以下完全相同 上面给出的,你只需要将“mysql+pymysql”替换为“postgresql+psycopg2”并通过pip安装psycopg2。
初始化数据库时,我们使用 langchain 中的 SQLDatabase.from_uri() 方法,并传递 URI 和其他一些参数,它们的作用如下:
- include_tables:我们仅引用 job_details 表并仅查询该表
- Sample_rows_in_table_info:与数据库交互时,langchain 将接收该表的前 2 行作为示例,以提供额外的上下文和更好的检索
最后一步是设置一个数据库链,这将帮助我们的 LLM 与数据库交互,我们使用 SQLDatabaseChain 来完成此操作。
设置检索功能:
def retrieve_from_db(query: str) -> str:
db_context = db_chain(query)
db_context = db_context['result'].strip()
return db_context该函数会将用户提供的查询作为输入,将其传递到我们的数据库链,并从数据库中检索相关信息并将其作为字符串返回。
我们将使用提示模板来保持其简洁和易于理解。 提示模板帮助我们构建提示的骨架,我们可以根据用户输入和用例填写模板。
system_message = """You are a professional representative of an employment agency.
You have to answer user's queries and provide relevant information to help in their job search.
Example:
Input:
Where are the most number of jobs for an English Teacher in Canada?
Context:
The most number of jobs for an English Teacher in Canada is in the following cities:
1. Ontario
2. British Columbia
Output:
The most number of jobs for an English Teacher in Canada is in Toronto and British Columbia
"""
human_qry_template = HumanMessagePromptTemplate.from_template(
"""Input:
{human_input}
Context:
{db_context}
Output:
"""
)
messages = [
SystemMessage(content=system_message),
human_qry_template.format(human_input=query, db_context=db_context)
]
response = chat(messages).content由于我们使用的是聊天模型,因此我们在系统消息中提供说明和示例,使其成为一次性推理任务。
在人类消息中,我们将从数据库检索到的数据与用户查询一起提供给模型。
最后,使用用户输入的查询和从我们的数据库检索的上下文来格式化人工消息模板,并点击聊天模型来生成响应。
将一切拼凑在一起:
def generate(query: str) -> str:
db_context = retrieve_from_db(query)
system_message = """You are a professional representative of an employment agency.
You have to answer user's queries and provide relevant information to help in their job search.
Example:
Input:
Where are the most number of jobs for an English Teacher in Canada?
Context:
The most number of jobs for an English Teacher in Canada is in the following cities:
1. Ontario
2. British Columbia
Output:
The most number of jobs for an English Teacher in Canada is in Toronto and British Columbia
"""
human_qry_template = HumanMessagePromptTemplate.from_template(
"""Input:
{human_input}
Context:
{db_context}
Output:
"""
)
messages = [
SystemMessage(content=system_message),
human_qry_template.format(human_input=query, db_context=db_context)
]
response = llm(messages).content
return response输入和输出示例:

在这里,我们可以看到数据库链获取了多伦多最受欢迎的工作,并将其作为上下文传递给我们的法学硕士,为我们提供了自然语言的正确答案。
3、结束语
在本文中,我们探讨了检索增强生成 (RAG) 如何在构建特定领域的聊天机器人时改变游戏规则。 RAG 弥合了大型语言模型 (LLM) 和外部数据库之间的差距,确保做出更明智、更准确的响应。
我们讨论了 RAG 通过从数据库动态检索上下文信息来弥补LLM缺乏领域知识的能力。 实际示例是就业机构的 ChatBot,展示了 Langchain 在连接 SQL 数据库并利用 OpenAI 的 LLM 进行精确响应方面的作用。
通过采用 RAG 和 Langchain 等框架,我们为更多上下文感知的人工智能应用程序铺平了道路。 通过提供准确、上下文丰富的信息,可以实现更好的用户体验和决策。 充分利用 RAG 的潜力,释放数据驱动的对话式 AI 的财富。
相关文章
Redis高并发分布锁实战

Redis是否为单线程?

MySQL中的高级查询

ubuntu20.04安装实时内核补丁PREEMPT_RT
mysql中文首字母排序查询
使用redis-insight连接到服务器上的redis数据库

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案
数据湖Paimon入门指南

虚拟机Windows Server 2016 安装 MySQL8
MySQL运行在docker容器中会损失多少性能

Mysql大数据量分页优化
oracle data block , extent 和segment区别
Centos系统上安装PostgreSQL和常用PostgreSQL功能
MySQL数据库主从复制集群原理概念以及搭建流程
【MySQL】MySQL表的约束-空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
CentOS本地部署SQL Server数据库无公网ip环境实现远程访问

[redis] redis的安装,配置与简单操作

Redis的IO多路复用原理解析
在 Docker 中配置 MySQL 数据库并初始化 Project 项目
Redis内存使用率高,内存不足问题排查和解决

深入理解Mysql事务隔离级别与锁机制

Redis数据一致解决方案

MySQL:为什么明明创建了索引还是走了全表扫描
深入理解Mysql底层数据结构和算法
如何在Linux设置JumpServer实现无公网ip远程访问管理界面

