
本文主要介绍在MongoDB使用数组字段和子文档字段进行索引。
MongoDB的高级索引
MongoDB是一个面向文档的NoSQL数据库,它提供了丰富的索引功能来加快查询性能。除了常规的单字段索引之外,MongoDB还支持高级索引,包括索引数组字段和索引子文档字段。
一、索引数组字段
索引数组字段是指在文档中的某个字段是一个数组,并且希望对这个数组中的元素建立索引。
MongoDB使用多键索引(multikey index)来实现对数组字段的索引。
例如,假设有一个文档集合存储了学生的成绩记录,每个学生可能有多门科目的成绩,可以将成绩字段建立索引,以便对成绩进行快速查找。在这种情况下,MongoDB会为每个数组中的元素创建一个索引项。
以下是一个示例,展示如何在MongoDB中使用索引数组字段:
假设我们有一个文档集合存储了学生的成绩记录,每个学生可能有多门科目的成绩,我们希望对学生的姓名和每门课程的成绩字段进行索引。
首先,创建一个名为students的集合,并向其中插入几个文档:
db.students.insertMany([
{ name: "Alice", scores: [90, 85, 95] },
{ name: "Bob", scores: [70, 80, 75] },
{ name: "Charlie", scores: [60, 65, 70] }
])
接下来,我们可以为成绩字段创建一个多键索引,以便对学生的成绩进行快速查找:
db.students.createIndex({ scores: 1 })
现在,我们可以使用find操作来查询匹配特定成绩的学生:
db.students.find({ scores: 80 })
这个查询会返回所有成绩中包含80的学生文档。
此外,我们也可以使用$elemMatch操作符来进一步筛选数组中的元素。例如,如果我们希望查询成绩中同时包含80和85的学生:
db.students.find({ scores: { $elemMatch: { $in: [80, 85] } } })
这个查询会返回所有成绩中同时包含80和85的学生文档。
需要注意的是,对于索引数组字段,需要确保数组字段的长度不会超过索引大小限制,一般建议数组长度控制在不超过1000个元素。此外,在对索引数组字段进行更新操作时,需要小心处理索引的更新情况,以避免不必要的索引重建。
索引数组字段可以帮助我们在MongoDB中更高效地进行数组元素的查询,提升查询性能和灵活性。
二、索引子文档字段
索引子文档字段是指在文档中的某个字段是一个嵌套文档(子文档),并且希望对这个子文档中的字段建立索引。
MongoDB可以对子文档字段进行深层索引(deep index),以实现更精确的查询。
例如,假设有一个文档集合存储了图书的信息,每本图书包含了作者、标题和出版信息等字段,可以将作者名字字段建立索引,以便根据作者进行快速查找。在这种情况下,MongoDB会为子文档中的字段创建索引。
下面是一个示例,展示了如何在MongoDB中创建索引子文档字段:
假设有一个名为"users"的集合,其中的文档结构如下:
{
"_id": ObjectId("5ec9a8f44ed1a74ebfe537a1"),
"name": "John",
"address": {
"street": "123 Main St",
"city": "New York",
"state": "NY"
}
}
要在"address.city"字段上创建索引,可以使用以下命令:
db.users.createIndex({"address.city": 1})
在这个示例中,我们使用了"createIndex"方法来创建索引。传递给方法的参数是一个包含索引字段和排序方向的对象。在这里,我们将"address.city"字段指定为索引字段,并将排序方向设为1,表示升序。
创建完索引后,可以使用以下命令检查索引是否已成功创建:
db.users.getIndexes()
这将返回一个包含索引信息的列表。在这个列表中,您应该能够看到"address.city"字段的索引。
在查询中使用索引子文档字段时,可以使用点符号来指定子文档字段的路径。例如,要查询"address.city"字段为"New York"的文档,可以使用以下命令:
db.users.find({"address.city": "New York"})
这将返回所有"address.city"字段为"New York"的文档。
MongoDB提供了在子文档字段上创建索引的功能,这可以提高查询性能并允许在查询中针对子文档字段进行高效的筛选和排序。示例中演示了如何在MongoDB中创建索引子文档字段,并给出了一个查询示例。
在使用MongoDB索引子文档字段时,有几个注意事项需要考虑:
索引字段的路径:在创建索引时,需要指定子文档字段的完整路径。这包括每个父级字段的名称和子文档字段的名称,使用点符号来连接它们。确保提供正确的路径,以便MongoDB能够正确地创建和使用索引。
嵌套子文档字段:如果要在多级嵌套的子文档字段上创建索引,需要确保指定完整的路径。例如,如果有一个名为"address"的子文档,它又有一个名为"location"的子文档,要在"address.location.city"字段上创建索引,需要提供完整的路径。
索引字段的选择:在创建索引时,需要仔细选择要索引的子文档字段。如果一个子文档字段经常被查询和筛选,那么在该字段上创建索引可能会提高查询性能。然而,如果索引过多或选择不当,可能会导致索引大小变大并降低性能。
频繁更新:如果子文档字段经常被更新,特别是插入或删除子文档字段,那么在该字段上的索引可能会导致索引维护成本增加。需要权衡索引的使用和维护成本之间的平衡。
复合索引:如果子文档字段经常与其他字段一起使用,可以考虑创建复合索引。复合索引可以包含多个字段,其中包括子文档字段。这样可以提高包含子文档字段的查询性能。
索引大小:当在子文档字段上创建索引时,需要注意索引大小。索引大小会影响存储和查询性能。如果索引过大,可能需要考虑使用部分索引或调整索引存储大小的配置选项。
在使用MongoDB索引子文档字段时,需要注意索引字段的路径、选择适当的字段、权衡索引的使用和维护成本,并考虑使用复合索引来提高查询性能。此外,还应该关注索引大小对存储和查询性能的影响。
相关文章
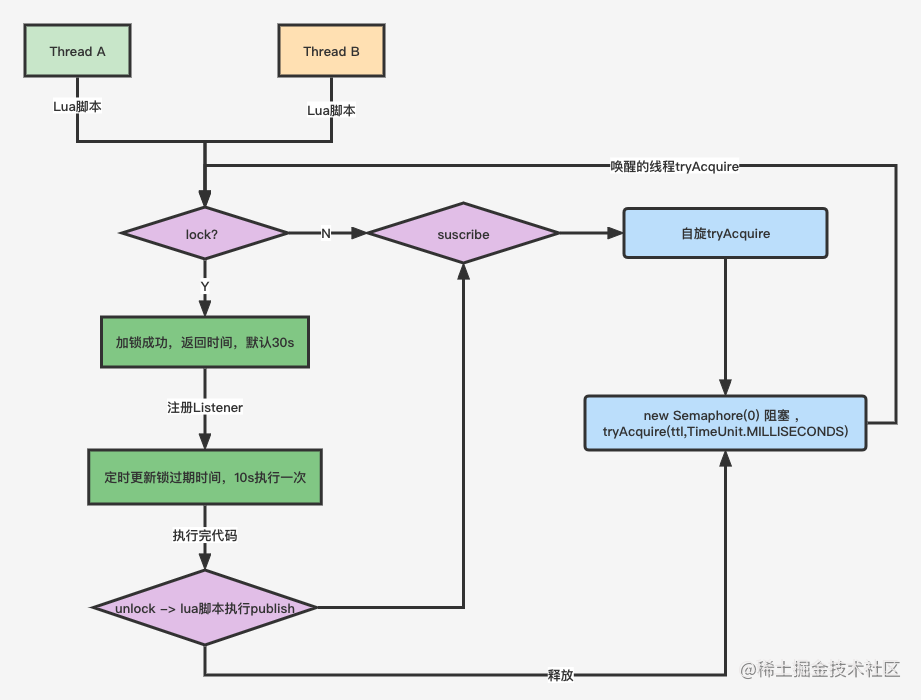
Redis高并发分布锁实战

Redis是否为单线程?

MySQL中的高级查询

ubuntu20.04安装实时内核补丁PREEMPT_RT
mysql中文首字母排序查询
使用redis-insight连接到服务器上的redis数据库
数据湖Paimon入门指南
基于SQL数据库的大模型RAG实现
MySQL运行在docker容器中会损失多少性能

Mysql大数据量分页优化
oracle data block , extent 和segment区别
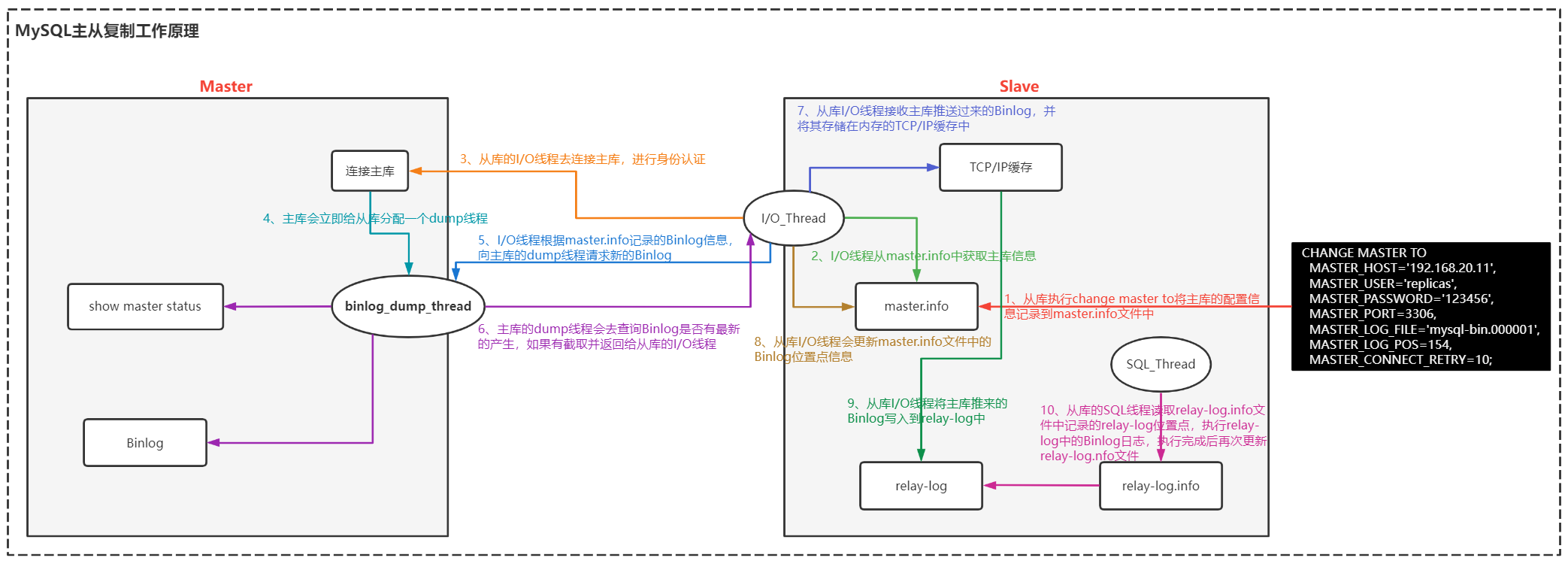
MySQL数据库主从复制集群原理概念以及搭建流程

学习如何使用 Python 连接 MongoDB: PyMongo 安装和基础操作教程
CentOS本地部署SQL Server数据库无公网ip环境实现远程访问

[redis] redis的安装,配置与简单操作

Redis的IO多路复用原理解析
在 Docker 中配置 MySQL 数据库并初始化 Project 项目
Redis内存使用率高,内存不足问题排查和解决

深入理解Mysql事务隔离级别与锁机制

Redis数据一致解决方案

MySQL:为什么明明创建了索引还是走了全表扫描
深入理解Mysql底层数据结构和算法
如何在Linux设置JumpServer实现无公网ip远程访问管理界面

复杂 SQL 实现分组分情况分页查询

Hadoop3.x完全分布式模式下slaveDataNode节点未启动调整

