写在前面
前言
人工智能是指使计算机系统表现出类似于人类智能的能力。其目标是实现机器具备感知、理解、学习、推理和决策等智能行为。人工智能的发展可以追溯到上世纪50年代,随着计算机技术和算法的不断进步,人工智能得以实现。
机器学习是人工智能的一个重要分支,它通过让计算机从数据中学习和改进性能,而不需要明确的编程指令。机器学习可以分为监督学习、无监督学习和强化学习三种主要类型。
人工智能与机器学习的概述

监督学习、无监督学习和强化学习的基本原理
监督学习:
通过给定输入和对应的输出样本,训练模型来预测新的输入样本的输出。常见的算法包括线性回归、决策树、支持向量机等。其基本原理是根据已知的输入和输出样本,构建一个模型,并通过优化算法调整模型的参数,使得预测结果尽可能接近真实输出。
无监督学习:
在没有明确标签的情况下,通过发现数据内部的模式和结构来进行学习。其基本原理是通过聚类、降维等方法,将相似的数据归为一类,从而找到数据中的隐藏规律和结构。常见的算法包括聚类、关联规则挖掘等。
强化学习:
通过与环境的交互和反馈,使计算机学习如何在一系列动作中选择最佳策略。其基本原理是通过定义奖励信号和状态转移函数,以最大化累积奖励为目标,训练智能体(Agent)选择最优动作。常见的算法包括Q-learning、深度强化学习等。
机器学习的算法和方法
机器学习是实现人工智能的关键技术之一。机器学习通过从数据中学习模式和规律来提高人工智能系统的性能。同时,人工智能也为机器学习提供了更广阔的应用场景和挑战,推动了机器学习算法和方法的不断创新和发展。
常见的机器学习算法和方法
线性回归:
from sklearn.linear_model import LinearRegression
# 创建线性回归模型
model = LinearRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
决策树:
from sklearn.tree import DecisionTreeClassifier
# 创建决策树分类模型
model = DecisionTreeClassifier()
# 训练模型
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
支持向量机:
python
from sklearn.svm import SVC
# 创建支持向量机分类模型
model = SVC()
# 训练模型
model.fit(X_train, y_train)
# 预测结果
y_pred = model.predict(X_test)
神经网络:
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 创建神经网络模型
model = Sequential()
model.add(Dense(64, activation='relu', input_dim=input_dim))
model.add(Dense(64, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=10, batch_size=32)
# 预测结果
y_pred = model.predict(X_test)

人工智能与机器学习的应用领域
自然语言处理和智能对话系统
人工智能在自然语言处理方面取得了显著的进展。智能对话系统可以通过理解和生成自然语言进行交流和任务执行。
import torch
from transformers import T5Tokenizer, T5ForConditionalGeneration
# 加载预训练模型和分词器
model = T5ForConditionalGeneration.from_pretrained('t5-base')
tokenizer = T5Tokenizer.from_pretrained('t5-base')
# 输入文本
input_text = "Translate this text to French."
# 分词和编码
input_ids = tokenizer.encode(input_text, return_tensors='pt')
# 生成翻译
translated_ids = model.generate(input_ids)
translated_text = tokenizer.decode(translated_ids[0], skip_special_tokens=True)
print("Translated Text:", translated_text)
图像和视频识别、人脸识别技术
人工智能在图像和视频识别方面成果丰硕。计算机可以通过机器学习算法识别和分类图像,实现人脸识别、目标检测等功能。
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
# 加载预训练模型和图像预处理
model = models.resnet50(pretrained=True)
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载图像
image = Image.open("image.jpg")
# 图像预处理
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
# 使用GPU加速
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
input_batch = input_batch.to(device)
# 前向传播
with torch.no_grad():
output = model(input_batch)
# 输出预测结果
_, predicted_idx = torch.max(output, 1)
predicted_label = predicted_idx.item()
print("Predicted Label:", predicted_label)
机器学习可以帮助企业从大量数据中发现有价值的信息,进行数据挖掘和预测分析。这些信息可以用于市场预测、用户行为分析等领域。
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 创建神经网络模型
class QNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
def forward(self, x):
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化环境和模型
env = gym.make('CartPole-v0')
state_size = env.observation_space.shape[0]
action_size = env.action_space.n
model = QNetwork(state_size, action_size)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练过程
num_episodes = 100
for episode in range(num_episodes):
state = env.reset()
done = False
while not done:
# 选择动作
state_tensor = torch.tensor(state, dtype=torch.float).unsqueeze(0)
q_values = model(state_tensor)
action = torch.argmax(q_values, dim=1).item()
# 执行动作并观察结果
next_state, reward, done, _ = env.step(action)
# 计算损失函数
next_state_tensor = torch.tensor(next_state, dtype=torch.float).unsqueeze(0)
target_q_values = reward + 0.99 * torch.max(model(next_state_tensor))
loss = F.mse_loss(q_values, target_q_values.unsqueeze(0))
# 反向传播和优化器步骤
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
# 输出每个回合的总奖励
print("Episode:", episode, "Reward:", reward)

人工智能与机器学习的未来发展
人工智能与机器学习将与计算机视觉、语音识别和自然语言处理等感知技术相结合,实现多模态智能,提高对真实世界的理解和交互能力。
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Flatten, Dense, Embedding, LSTM, concatenate
# 创建多模态智能模型
image_input = Input(shape=(img_height, img_width, num_channels))
conv_layer = Conv2D(32, kernel_size=(3, 3), activation='relu')(image_input)
pooling_layer = MaxPooling2D(pool_size=(2, 2))(conv_layer)
flatten_layer = Flatten()(pooling_layer)
image_output = Dense(64, activation='relu')(flatten_layer)
text_input = Input(shape=(max_seq_len,))
embedding_layer = Embedding(input_dim=num_words, output_dim=embedding_dim)(text_input)
lstm_layer = LSTM(units=32)(embedding_layer)
text_output = Dense(64, activation='relu')(lstm_layer)
merged = concatenate([image_output, text_output])
final_output = Dense(num_classes, activation='softmax')(merged)
model = Model(inputs=[image_input, text_input], outputs=final_output)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit([X_train_images, X_train_text], y_train, epochs=num_epochs, batch_size=batch_size)
人工智能的发展目标不是取代人类,而是与人类合作共生。未来,人工智能将与人类共同解决复杂问题,提高生产力和生活质量。
import matplotlib.pyplot as plt
import cv2
# 加载图像
img = cv2.imread('image.jpg')
# 显示图像
plt.imshow(img)
plt.show()
# 创建交互式界面
while True:
# 获取用户输入
user_input = input('请输入需要进行的操作:')
# 根据用户输入进行相应处理
if user_input == '边缘检测':
# 边缘检测处理
edges = cv2.Canny(img, 100, 200)
# 显示结果
plt.imshow(edges, cmap='gray')
plt.show()
elif user_input == '灰度化':
# 灰度化处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 显示结果
plt.imshow(gray, cmap='gray')
plt.show()
elif user_input == '退出':
# 退出程序
break
else:
# 输入错误提示
print('输入错误,请重新输入!')

结论:
人工智能和机器学习在当今科技发展中扮演着重要的角色。通过不断创新和突破,它们正在改变我们的生活和工作方式。然而,我们也要关注其伦理和社会影响,确保其发展是可持续、公正和安全的。未来,人工智能与机器学习将不仅是科技进步的驱动力,也是引领人类进入智能时代的里程碑。
相关文章

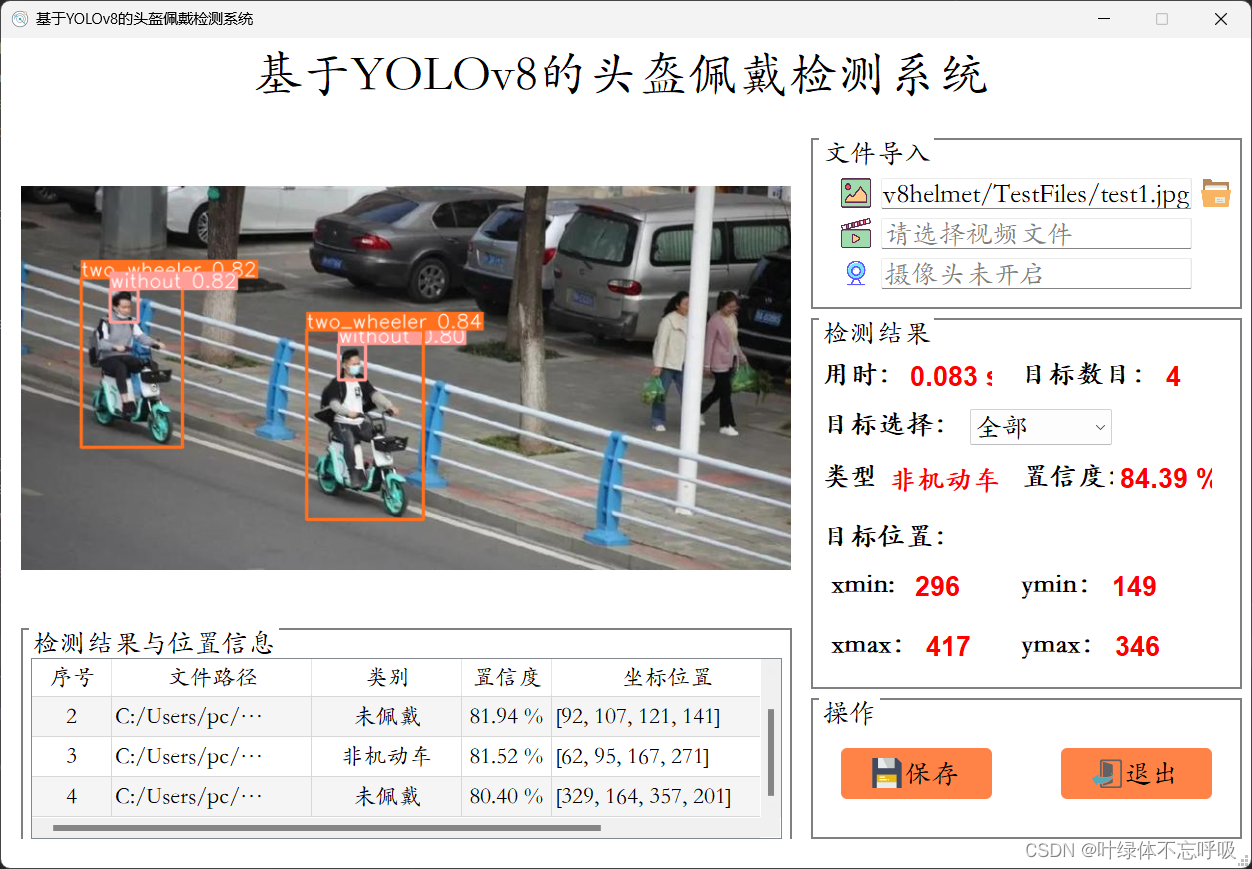
基于YOLOv8深度学习+Pyqt5的电动车头盔佩戴检测系统

chatgpt的大致技术原理

云计算与边缘计算:有什么区别?

ChatGPT高效提问—prompt基础
梯度是什么,为什么联邦学习传递这个就可以更新模型?

二维平面阵列波束赋形原理和Matlab仿真
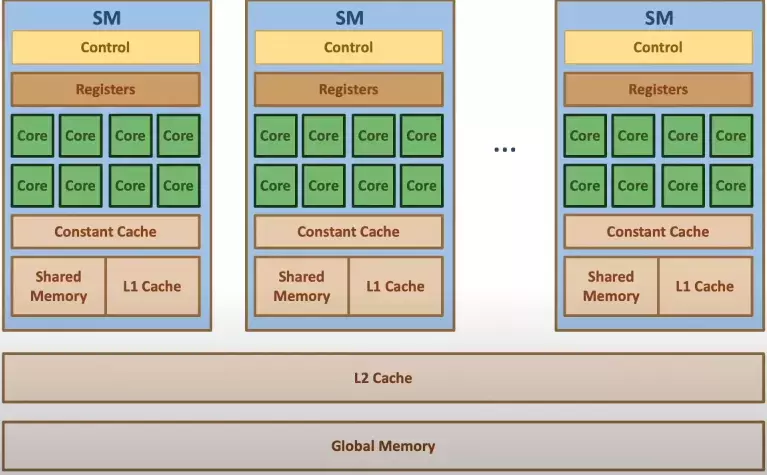
【GPU】深入理解GPU硬件架构及运行机制
新能源汽车智慧充电桩管理方案:环境监测与充电安全多维感知
RAG中的3个高级检索技巧

大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解

从虚拟到现实:数字孪生驱动智慧城市可持续发展

如何使用人工智能优化 DevOps?
C# Onnx Chinese CLIP 通过一句话从图库中搜出来符合要求的图片

感知与认知的碰撞,大模型时代的智能文档处理范式
人工智能有哪些领域?

OpenCV:计算机视觉的强大工具库

使用LOTR合并检索提高RAG性能

【AI】人工智能复兴的推进器之神经网络

目标检测与测距算法在极端天气下的应用

AI时代架构设计新模式

Python将列表中的数据写入csv并正确解析出来

深度解析 PyTorch Autograd:从原理到实践

AIGC实战——WGAN(Wasserstein GAN)

ChatGPT的常识


人工智能时代:AIGC的横空出世

【图像处理】使用各向异性滤波器和分割图像处理从MRI图像检测脑肿瘤(Matlab代码实现)
