
引言:
在现代社会中,极端天气条件对人们的生活和工作带来了很大的挑战。对于一些特定领域,如交通运输、安全监控等,准确的目标检测与测距算法在极端天气下尤为重要。本文将分点概述极端天气下目标检测与测距算法的关键问题及解决办法。
1. 雷暴天气中的目标检测与测距算法
a. 雷暴天气中的目标检测面临的挑战:强烈的闪电和大量的云层会产生背光和阴影,使得目标检测变得困难。
b. 解决方案:结合多帧图像处理技术,利用时间序列信息对目标进行建模和跟踪,从而提高目标检测的准确性。
2. 沙尘暴天气中的目标检测与测距算法
a. 沙尘暴天气中的目标检测面临的挑战:沙粒的扬起会导致图像模糊和降低可见度,干扰目标的清晰展示。
b. 解决方案:利用计算机视觉算法对沙尘暴图像进行预处理,消除噪声和模糊效果,同时采用自适应的阈值处理方法,提高目标的检测效果。
3. 雪暴天气中的目标检测与测距算法
a. 雪暴天气中的目标检测面临的挑战:大量的雪花会干扰目标的视觉特征,使得目标难以区分。
b. 解决方案:通过图像分割算法将雪花与目标进行分离,提取目标的特征并进行分类,从而实现准确的目标检测。
4. 阴雨天气中的目标检测与测距算法
a. 阴雨天气中的目标检测面临的挑战:天空的暗淡和反射会使目标的轮廓模糊,影响目标的检测和距离测量。
b. 解决方案:结合多模态图像处理技术,利用多个光谱波段的信息,通过图像增强和背景去除,提高目标的可见性和识别准确性。
5. 晚间天气中的目标检测与测距算法
a. 晚间天气中的目标检测面临的挑战:夜晚光线不足,目标的细节难以捕捉。
b. 解决方案:利用红外热像仪和夜视技术,结合目标的红外辐射特征进行目标检测和测距,以实现对晚间目标的准确识别。
结论:
随着科技的不断发展和进步,目标检测与测距算法在极端天气下的应用得到了显著提升。通过合理地结合各种先进的计算机视觉技术和传感器设备,我们能够克服极端天气条件下的困难,提高目标检测和测距的准确性和可靠性。然而,还有许多挑战需要克服,例如更多的复杂环境条件以及传感器的实时性和精度等。因此,目标检测和测距算法的研究仍然具有重要的意义和价值,将会极大地推动相关领域的发展和应用。
本文主要工作:
科技的发展与进步促使自动驾驶车辆逐渐成为全球汽车产业发展的重要战略 方向。但自动驾驶车辆面对如:大雨、大雾、大雪等极端环境时,智能汽车图像 采集与处理系统将面临巨大挑战。并且自动驾驶需要实时关注周围物体的威胁, 实时进行目标检测以及精确测量周围目标的距离是提高汽车安全性的可行之策。 本文首先训练出一种天气分类模型,实时识别当下天气情况。其次针对不同天气 情况则采取不同的图像去噪方法来提高图像质量。天气前处理完成后将采取改进 的 Yolo 模型对前方行人、车辆等道路环境目标进行目标检测。最后对目标检测定 位到的物体采用改进目标点的测距方法进行距离测量,为自动驾驶主动安全行为 提供支持。
总结:本文完成了去雾、去雨、去雪,目标检测与车辆距离测量。运用了yoloV3目标检测,单目测距,prescan仿真。本文代码分享与论文撰写相关的同学可以一起交流。如果对你有用,欢迎私聊点赞交流–

1.天气分类
为了实时识别出当下的天气情况,利用卷积神经网络搭建了天气分类模型。 针对搜集到的天气图像数量少且不具代表性的问题,通过改进 mosaic 和图像合成 手段进行数据增强与扩充。为了提升模型精度,将数据集划分成 6 种大小不同的 批尺寸,改进激活函数并引入模型优化方案。最终将数据集输送到天气分类模型 训练后得到了良好的权重系数。该模型可以对实时出现的晴天、雨天、雾天、雪 天四种天气进行识别分类,分类精确度可达 93.46%。
mosic天空区域图像增强:
数据增强主要代码部分:
def readxml(image_file):
if image_file.split(".")[1] == 'png':
xml_path = os.path.join(path_origin_xml, image_file.replace('png', 'xml'))
else:
xml_path = os.path.join(path_origin_xml, image_file.replace('jpg', 'xml'))
root = ET.parse(xml_path).getroot()
bb = []
for obj in root.iter('object'): # 获取object节点中的name子节点
bbox = obj.find('bndbox')
xmin = int(float(bbox.find('xmin').text.strip()))
ymin = int(float(bbox.find('ymin').text.strip()))
xmax = int(float(bbox.find('xmax').text.strip()))
ymax = int(float(bbox.find('ymax').text.strip()))
####-----------------非常重要----------------######## 下面的1需要修改 具体修改见链接
bb.append(np.array([xmin, ymin, xmax, ymax, 1]))
return np.array(bb)
if __name__ == "__main__":
lines = []
for filename in os.listdir(os.path.join(image_path, '')):
if filename.endswith(".jpg") or filename.endswith(".JPG") or filename.endswith(".png"):
lines.append(filename)
print(lines)
list1 = list(range(0,len(lines)))
print("list1:",list1)
四种天气数据集:**

天气分类代码部分:
data_transforms = {
'train': transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
data_dir = 'data/weather_data'
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x),
data_transforms[x])
for x in ['train', 'val']}
dataloaders = {x: torch.utils.data.DataLoader(image_datasets[x], batch_size=4,
shuffle=True, num_workers=4)
for x in ['train', 'val']}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
2.极端天气下图像前处理**
(1)去雾*
针对不同的天气则采取不同的图像前处理方法来提升图像质量。雾天天气 时,针对当下求解的透射率会导致去雾结果出现光晕、伪影现象,本文采用加权最小二乘法细化透射率透。针对四叉树法得到的大气光值不精确的问题,改进四叉树法来解决上述问题。将上述得到的透射率和大气光值代入大气散射模型完成去雾处理;下图为去雾前后对比图。
去雾前:

去雾后:

去雾关键代码
ef Transmission(src_img):
temp = np.min(src_img,2)
r1=1
s = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (r1,r1))
dst = cv2.erode(temp, s)
h,w=temp.shape
window=np.zeros((h,w))
r=1
for i in range(r,h-r,1):
for j in range(r,w-r,1):
window[i-r:i+r+1,j-r:j+r+1]=dst[i-r:i+r+1,j-r:j+r+1]
sum_=np.sum(window[i-r:i+r+1,j-r:j+r+1])
devide=sum_/((2*r+1)*(2*r+1))
window[i-r:i+r,j-r:j+r]=devide
darkChannel=cv2.dilate(window,np.ones((r1,r1)))
darkChannel=(1-darkChannel)*255.0
return darkChannel
(2)去雨*
面对雨天环境则采取主成分分析方法获取雨线图中雨线噪声的大小和形状信息,并将其与自适应阈值进行比较。当满足条件时,利用一种方法将雨线与之邻近的无雨背景层进行关联来达到去雨目的;
去雨流程图:

去雨关键代码:
ef pre_mark(I,b,g,r):
w1=w2=7
K_Left_Up = np.zeros((2*w1-1, 2*w2-1))
K_Right_Up = np.zeros((2*w1-1, 2*w2-1))
K_Center = 1/(w1*w2)*np.ones((w1, w2))
K_Left_Down =np.zeros((2*w1-1, 2*w2-1))
K_Right_Down = np.zeros((2*w1-1, 2*w2-1))
K_Left_Up[0:w1, 0:w2] = 1/(w1*w2)*np.ones((w1, w2))
# print(K_Left_Up.shape)
K_Right_Up[0:w1,w2-1:2*w2] = 1/(w1*w2)*np.ones((w1, w2))
# print(K_Right_Up)
K_Left_Down[w1-1:2*w1, 0:w2] = 1/(w1*w2)*np.ones((w1, w2))
K_Right_Down[w1-1:2*w1, w2-1:2*w2] = 1/(w1*w2)*np.ones((w1, w2))
#LU
b1=scipy.ndimage.filters.convolve(b, K_Left_Up, mode='nearest')
g1=scipy.ndimage.filters.convolve(g, K_Left_Up, mode='nearest')
r1=scipy.ndimage.filters.convolve(r, K_Left_Up, mode='nearest')
I_LU=cv2.merge((b1,g1,r1))
#RU
b2=scipy.ndimage.filters.convolve(b, K_Right_Up, mode='nearest')
g2=scipy.ndimage.filters.convolve(g, K_Right_Up, mode='nearest')
r2=scipy.ndimage.filters.convolve(r, K_Right_Up, mode='nearest')
I_RU=cv2.merge((b2,g2,r2))
#C
b3=scipy.ndimage.filters.convolve(b, K_Center, mode='nearest')
g3=scipy.ndimage.filters.convolve(g, K_Center, mode='nearest')
r3=scipy.ndimage.filters.convolve(r, K_Center, mode='nearest')
I_C=cv2.merge((b3,g3,r3))
#LD
b4=scipy.ndimage.filters.convolve(b, K_Left_Down, mode='nearest')
g4=scipy.ndimage.filters.convolve(g, K_Left_Down, mode='nearest')
r4=scipy.ndimage.filters.convolve(r, K_Left_Down, mode='nearest')
I_LD=cv2.merge((b4,g4,r4))
#RD
b5=scipy.ndimage.filters.convolve(b, K_Right_Down, mode='nearest')
g5=scipy.ndimage.filters.convolve(g, K_Right_Down, mode='nearest')
r5=scipy.ndimage.filters.convolve(r, K_Right_Down, mode='nearest')
I_RD=cv2.merge((b5,g5,r5))
去雨结果:

(3)去雪*
雪天天气 时,本文在去雨算法的基础上引入一种图像处理手段,完成对图像中雪斑的进一步处理。通过与经典算法定性以及定量比较,所提算法在结果中具良好的有效性和优越性。
去雪前后对比图:

去雪关键代码:
def refine_mark(I):
T1=0.04
T2=0.04
L,num = measure.label(I, neighbors = None, background = None, return_num = True, connectivity = 2)
Theta_cluster = []
for i in range(1,num,1):
b=np.argwhere(L==i)
h,_=b.shape
c=b-np.mean(b,0)
c_T=c.T
3.目标检测**
在图像处理后加入目标检测,提高了目标检测精度以及目标数量。
下图展现了雾天处理后的结果
图第一列为雾霾图像,第二列为没有加入图像处理的目标检测结果图,第三列为去雾后的目标检测结果图。
前处理前后目标检测效果对比

4.测距研究**
为了得到距离,进行了precan仿真验证。并完成10-100m的图像采集,利用测距模型进行测量。在prescan进行了如下操作。
Prescan单目测距仿真研究

上图采集到的目标框将可以用于自己模型的计算验证。
精确的对目标进行测距可以提高汽车安全性能。为了测量出目标检测得到的物体距离,本文首先完成了世界坐标到图像坐标系的公式推导,标定了相机内外参数。针对当下侧向物体测距时测量精确度不高的问题,进行了改进。得到了以下结果:

QQ767172261
5 总结/更多视觉相关项目见专栏
本文完成了去雾、去雨、去雪,目标检测与车辆距离测量。运用了yoloV3目标检测,单目测距,prescan仿真。
相关文章

基于YOLOv8深度学习+Pyqt5的电动车头盔佩戴检测系统

chatgpt的大致技术原理

云计算与边缘计算:有什么区别?

ChatGPT高效提问—prompt基础

二维平面阵列波束赋形原理和Matlab仿真

人工智能与机器学习——开启智能时代的里程碑
【GPU】深入理解GPU硬件架构及运行机制
新能源汽车智慧充电桩管理方案:环境监测与充电安全多维感知
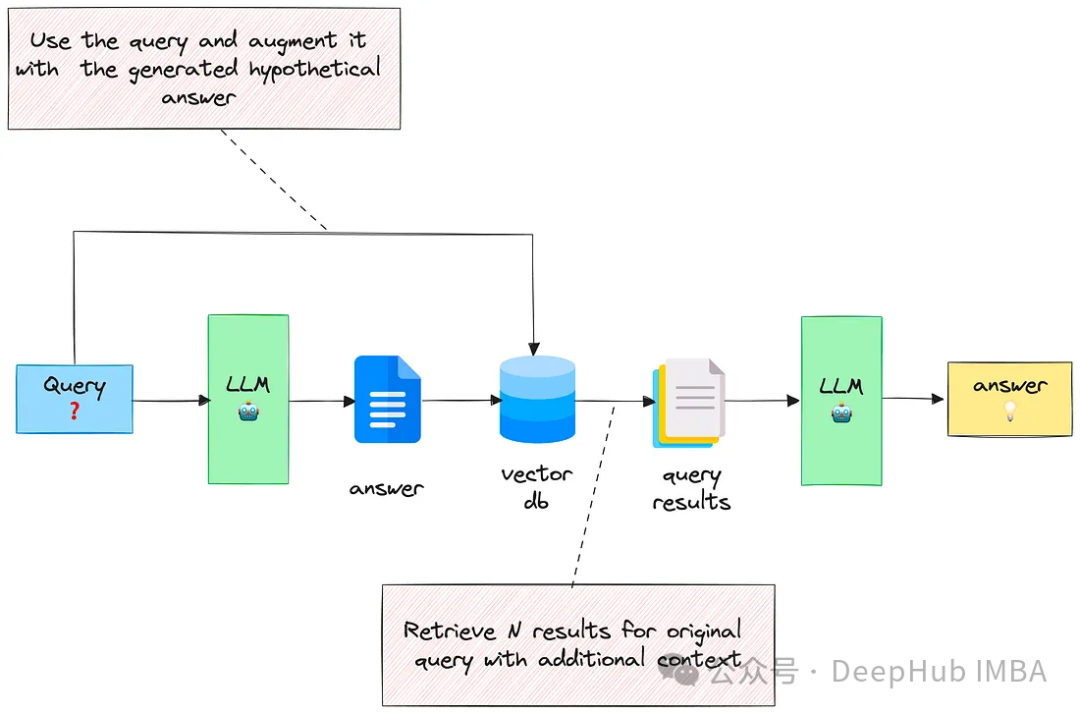
RAG中的3个高级检索技巧

大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解

从虚拟到现实:数字孪生驱动智慧城市可持续发展

如何使用人工智能优化 DevOps?
C# Onnx Chinese CLIP 通过一句话从图库中搜出来符合要求的图片

感知与认知的碰撞,大模型时代的智能文档处理范式
人工智能有哪些领域?

OpenCV:计算机视觉的强大工具库

使用LOTR合并检索提高RAG性能

【AI】人工智能复兴的推进器之神经网络

AI时代架构设计新模式

opencv中叠加Sobel算子与Laplacian算子实现边缘检测

深度解析 PyTorch Autograd:从原理到实践

AIGC实战——WGAN(Wasserstein GAN)

ChatGPT的常识
ubuntu18.04安装opencv-4.5.5+opencv_contrib-4.5.5


人工智能时代:AIGC的横空出世

【图像处理】使用各向异性滤波器和分割图像处理从MRI图像检测脑肿瘤(Matlab代码实现)
