RAG系统检索的文档可能并不总是与用户的查询保持一致,这是一个常见的现象。当文档可能缺乏查询的完整答案或者包含冗余信息或包含不相关的细节,或者文档的顺序可能与用户的意图不一致时,就会经常出现这种情况。
本文将探讨三种有效的技术来增强基于rag的应用程序中的文档检索,通过结合这些技术,可以检索与用户查询密切匹配的更相关的文档,从而生成更好的答案。
查询扩展
查询扩展指的是一组重新表述原始查询的技术。
本文将讨论两种易于实现的流行方法。
1、使用生成的答案扩展查询
给定一个输入查询,首先让LLM提供一个假设答案(不管其正确性),然后将查询和生成的答案组合在一个提示中并发送给检索系统。
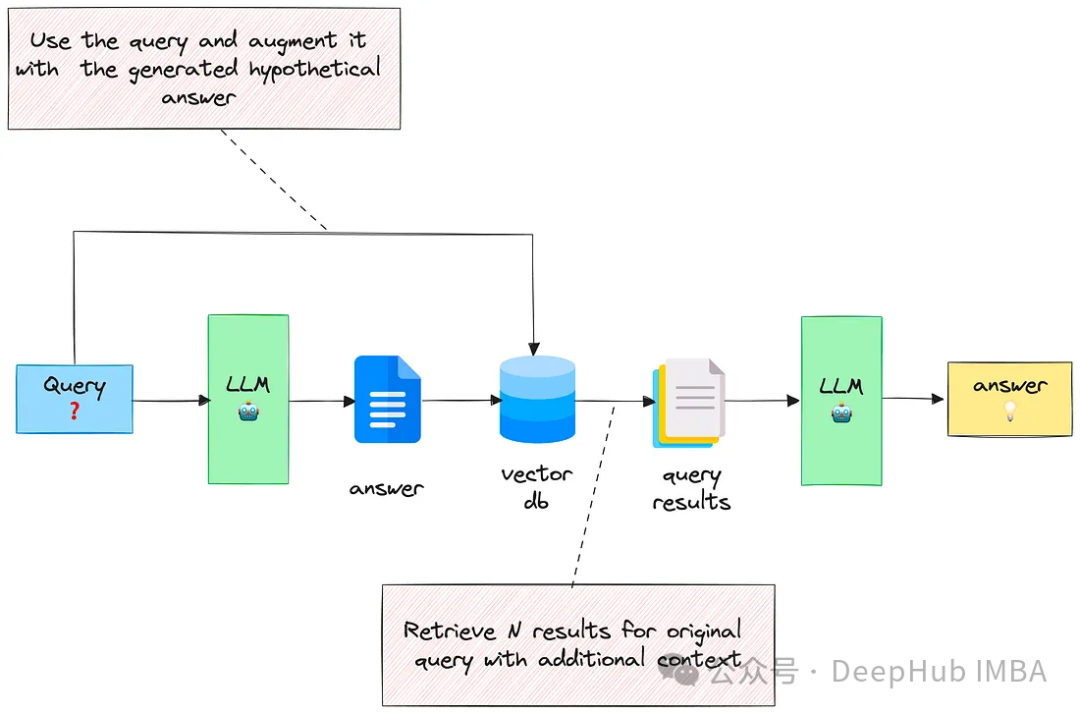
这种技术效果非常的好。这篇论文有详细的介绍:https://arxiv.org/abs/2212.10496
这个方法的思想是,我们希望检索看起来更像答案的文档,我们感兴趣的是它的结构和表述。所以可以将假设的答案视为帮助识别嵌入空间中相关邻域的模板。
下面是一个示例提示:
You are a helpful expert financial research assistant.
Provide an example answer to the given question, that might
be found in a document like an annual report.
2、通过包含多个相关问题扩展查询
第二种方法指示LLM生成与原始查询相关的N个问题,然后将它们(+原始查询)全部发送到检索系统。
这样可以从vectorstore中检索更多文档。但是其中一些将是重复的,所以需要执行后处理来删除它们。
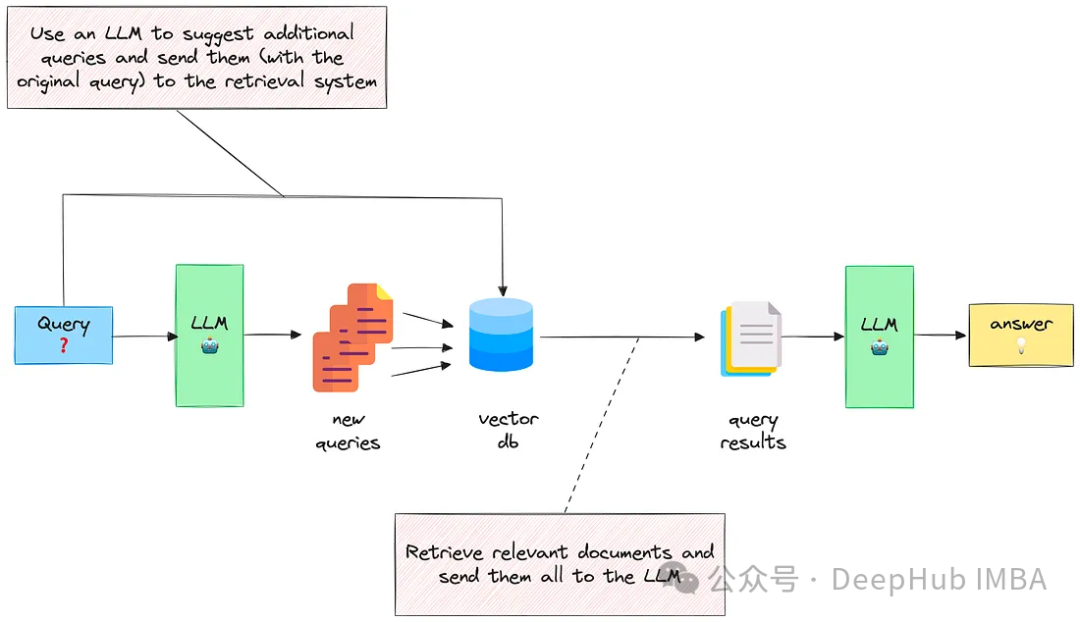
这个方法的思想是扩展可能不完整或不明确的初始查询,合并成最终可能相关和互补最终结果。
下面是用来生成相关问题的提示:
You are a helpful expert financial research assistant.
Your users are asking questions about an annual report.
Suggest up to five additional related questions to help them
find the information they need, for the provided question.
Suggest only short questions without compound sentences.
Suggest a variety of questions that cover different aspects of the topic.
Make sure they are complete questions, and that they are related to
the original question.
Output one question per line. Do not number the questions.
这种方法的缺点是最终会得到更多的文档,而这些文档可能会分散LLM的注意力,使其无法生成有用的答案。
所以就衍生出一个新的方法,重排序
重排序
该方法根据量化其与输入查询的相关性的分数对检索到的文档重新排序。
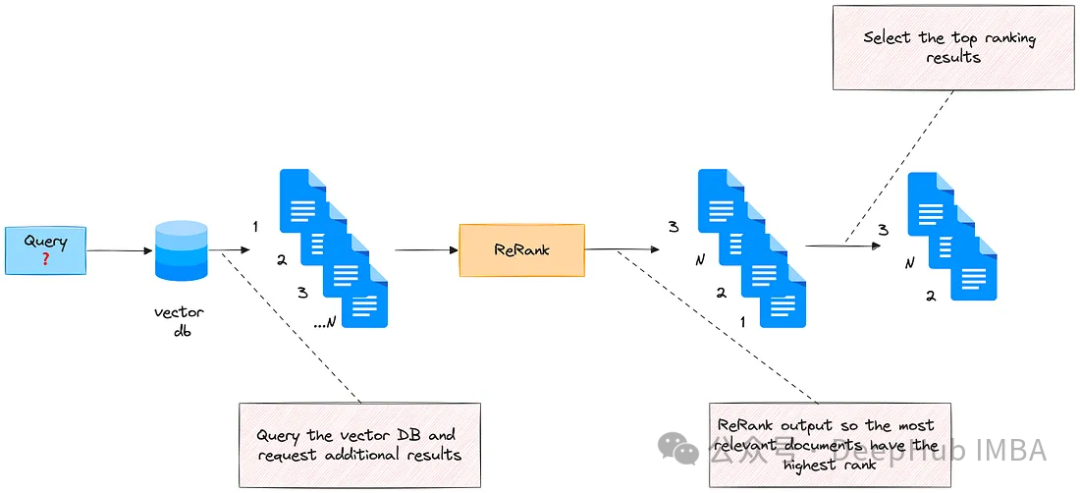
使用cross-encoder进行重新排序:
交叉编码器cross-encoder是一种深度神经网络,它将两个输入序列作为单个输入处理。允许模型直接比较和对比输入,以更综合和细致的方式理解它们的关系。
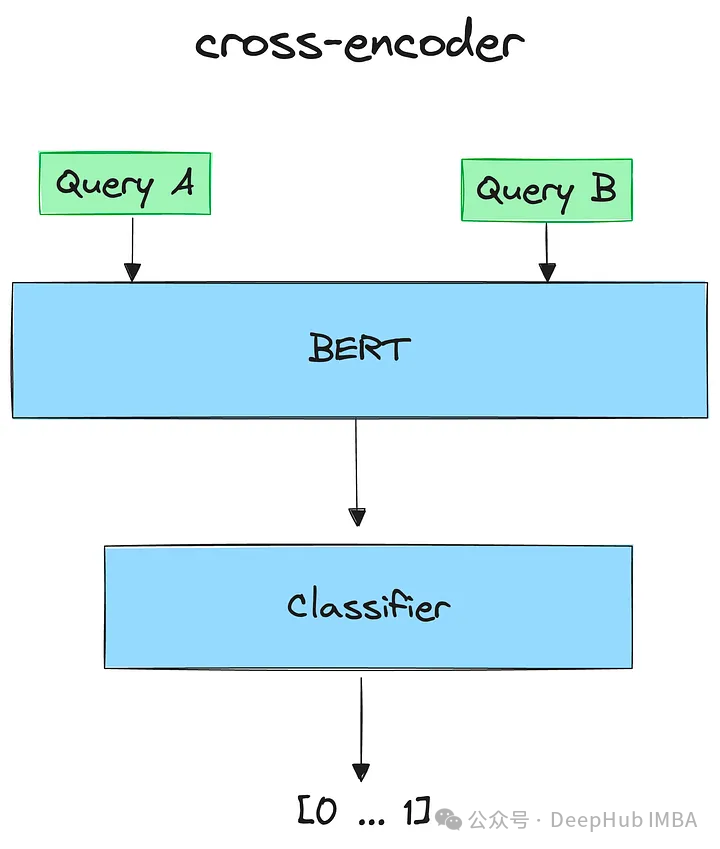
给定一个查询,用所有检索到的文档对其进行编码。然后按降序排序。得分高的认为是最相关的文件。
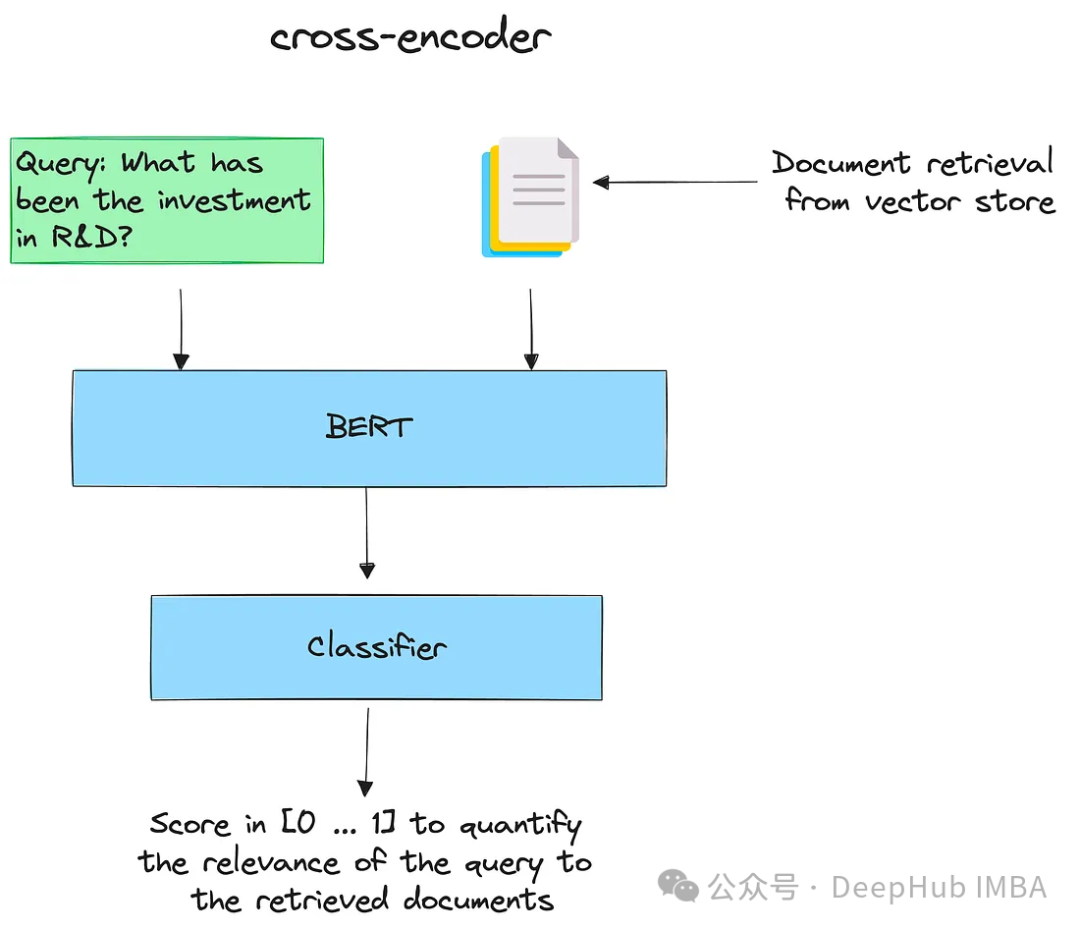
下面有一个简单的示例:
首先安装sentence-transformers
pip install -U sentence-transformers
使用它加载cross-encoder模型:
from sentence_transformers import CrossEncoder
cross_encoder = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
这里我们选择ms-marco-MiniLM-L-6-v2,对于排序的性能度量可以参考SBERT选择更好的模型。
每对(查询,文档)打分:
pairs = [[query, doc] for doc in retrieved_documents]
scores = cross_encoder.predict(pairs)
print("Scores:") for score in scores:
print(score)
# Scores:
# 0.98693466
# 2.644579
# -0.26802942
# -10.73159
# -7.7066045
# -5.6469955
# -4.297035
# -10.933233
# -7.0384283
# -7.3246956
重新整理文件:
print("New Ordering:")
for o in np.argsort(scores)[::-1]:
print(o+1)
重排序可以与查询扩展一起使用,在生成多个相关问题并检索相应文档(假设最终有M个文档)之后,对它们重新排序并选择最前面的K (K < M)。这样可以选择最重要的部分并且减小上下文的大小。
嵌入的适配器
这个方法利用用户检索文档相关性的反馈来训练一个新的适配器。
适配器是完全微调预训练模型的轻量级替代方案。一盘情况下适配器会插入到预训练模型层之间的小型前馈神经网络中,所以训练适配器的目标是更改嵌入查询,以便为特定任务生成更好的检索结果。
嵌入适配器是一个可以在嵌入阶段之后和检索之前插入的阶段。把它想象成一个对原始嵌入进行缩放的矩阵。
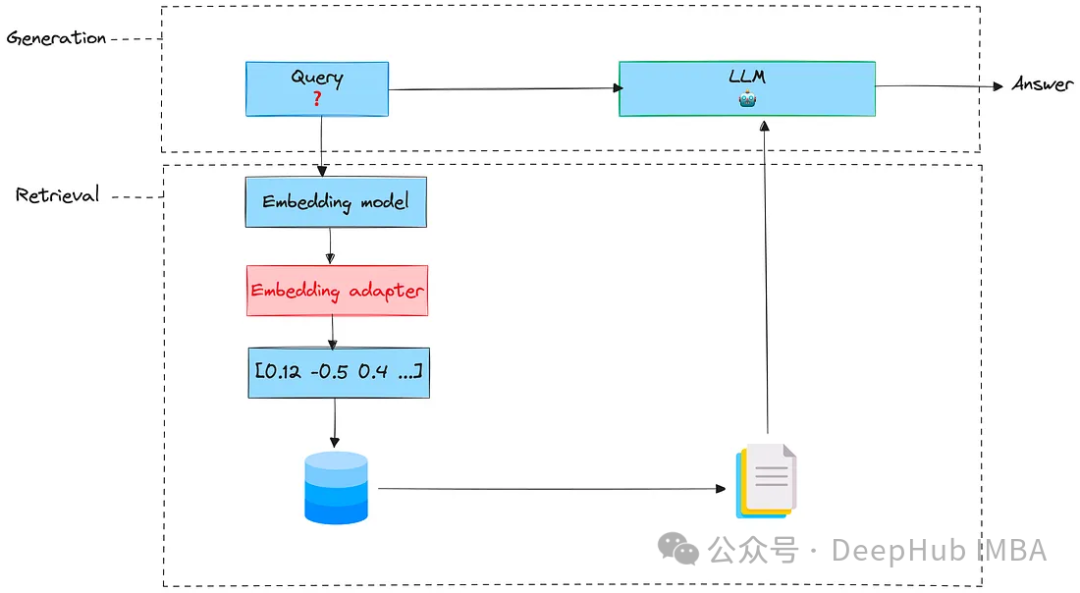
要训练适配器,需要执行以下步骤。
1、准备数据
这些数据可以手工标记或由LLM生成。数据必须包括元组(query, document)及其相应的标签(如果文档与查询相关,则为1,否则为-1)。
为了演示,我们将创建一个合成数据集,首先生成金融分析师在分析财务报告时可能会问的示例问题。
让我们使用LLM直接生成:
import os
import openai
from openai import OpenAI
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai.api_key = os.environ['OPENAI_API_KEY']
PROMPT_DATASET = """
You are a helpful expert financial research assistant.
You help users analyze financial statements to better understand companies.
Suggest 10 to 15 short questions that are important to ask when analyzing
an annual report.
Do not output any compound questions (questions with multiple sentences
or conjunctions).
Output each question on a separate line divided by a newline.
"""
def generate_queries(model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": PROMPT_DATASET,
},
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
)
content = response.choices[0].message.content
content = content.split("\n")
return content
generated_queries = generate_queries()
for query in generated_queries:
print(query)
# 1. What is the company's revenue growth rate over the past three years?
# 2. What are the company's total assets and total liabilities?
# 3. How much debt does the company have? Is it increasing or decreasing?
# 4. What is the company's profit margin? Is it improving or declining?
# 5. What are the company's cash flow from operations, investing, and financing activities?
# 6. What are the company's major sources of revenue?
# 7. Does the company have any pending litigation or legal issues?
# 8. What is the company's market share compared to its competitors?
# 9. How much cash does the company have on hand?
# 10. Are there any major changes in the company's executive team or board of directors?
# 11. What is the company's dividend history and policy?
# 12. Are there any related party transactions?
# 13. What are the company's major risks and uncertainties?
# 14. What is the company's current ratio and quick ratio?
# 15. How has the company's stock price performed over the past year?
然后,我们对每个生成的问题进行文档检索,得到了一个结果的合集
results = chroma_collection.query(query_texts=generated_queries, n_results=10, include=['documents', 'embeddings'])
retrieved_documents = results['documents']
然后需要评估每个问题与其相应文件的相关性。这里也使用LLM来完成这项任务:
PROMPT_EVALUATION = """
You are a helpful expert financial research assistant.
You help users analyze financial statements to better understand companies.
For the given query, evaluate whether the following satement is relevant.
Output only 'yes' or 'no'.
"""
def evaluate_results(query, statement, model="gpt-3.5-turbo"):
messages = [
{
"role": "system",
"content": PROMPT_EVALUATION,
},
{
"role": "user",
"content": f"Query: {query}, Statement: {statement}"
}
]
response = openai_client.chat.completions.create(
model=model,
messages=messages,
max_tokens=1
)
content = response.choices[0].message.content
if content == "yes":
return 1
return -1
现在就得到了我们的训练数据:每个元组将包含查询的嵌入、文档的嵌入和标签(1,-1)。
retrieved_embeddings = results['embeddings']
query_embeddings = embedding_function(generated_queries)
adapter_query_embeddings = []
adapter_doc_embeddings = []
adapter_labels = []
for q, query in enumerate(tqdm(generated_queries)):
for d, document in enumerate(retrieved_documents[q]):
adapter_query_embeddings.append(query_embeddings[q])
adapter_doc_embeddings.append(retrieved_embeddings[q][d])
adapter_labels.append(evaluate_results(query, document))
然后将它们放在Torch Dataset中作为训练集
adapter_query_embeddings = torch.Tensor(np.array(adapter_query_embeddings))
adapter_doc_embeddings = torch.Tensor(np.array(adapter_doc_embeddings))
adapter_labels = torch.Tensor(np.expand_dims(np.array(adapter_labels),1))
dataset = torch.utils.data.TensorDataset(adapter_query_embeddings, adapter_doc_embeddings, adapter_labels)
2、定义模型
我们定义了一个函数,它将查询嵌入、文档嵌入和适配器矩阵作为输入。该函数首先将查询嵌入与适配器矩阵相乘,并计算该结果与文档嵌入之间的余弦相似度。
def model(query_embedding, document_embedding, adaptor_matrix):
updated_query_embedding = torch.matmul(adaptor_matrix, query_embedding)
return torch.cosine_similarity(updated_query_embedding, document_embedding, dim=0)
3、损失
我们的目标是最小化由前一个函数计算的余弦相似度。所以可以直接使用均方误差(MSE)
def mse_loss(query_embedding, document_embedding, adaptor_matrix, label):
return torch.nn.MSELoss()(model(query_embedding, document_embedding, adaptor_matrix), label)
4、训练过程
初始化适配器矩阵并训练它超过100次。
# Initialize the adaptor matrix
mat_size = len(adapter_query_embeddings[0])
adapter_matrix = torch.randn(mat_size, mat_size, requires_grad=True)
min_loss = float('inf')
best_matrix = None
for epoch in tqdm(range(100)):
for query_embedding, document_embedding, label in dataset:
loss = mse_loss(query_embedding, document_embedding, adapter_matrix, label)
if loss < min_loss:
min_loss = loss
best_matrix = adapter_matrix.clone().detach().numpy()
loss.backward()
with torch.no_grad():
adapter_matrix -= 0.01 * adapter_matrix.grad
adapter_matrix.grad.zero_()
训练完成后,适配器可用于扩展原始嵌入并适应用户任务。
我们需要做的就是将原始的嵌入输出与适配器矩阵相乘,然后再将其输入到检索系统。
test_vector = torch.ones((mat_size,1))
scaled_vector = np.matmul(best_matrix, test_vector).numpy()
test_vector.shape
# torch.Size([384, 1])
scaled_vector.shape
# (384, 1)
best_matrix.shape
# (384, 384)
这样,我们检索系统后续使用的嵌入向量就是经过我们微调后的向量了,这相当于针对特定的任务进行优化
总结
我们介绍的这些检索技术有助于提高文档的相关性。但是这方面的研究还正在进行,还有很多其他方法例如,
利用真实反馈数据对嵌入模型进行微调;直接微调LLM以使其检索能力最大化(RA-DIT);探索更复杂的嵌入适配器使用深度神经网络而不是矩阵;深度和智能分块技术
这些技术我们也会在后面进行整理和介绍,感谢阅读。
https://avoid.overfit.cn/post/2f2d747462c44425be906b7c5611fe37
作者:Ahmed Besbes
相关文章

基于YOLOv8深度学习+Pyqt5的电动车头盔佩戴检测系统

chatgpt的大致技术原理

云计算与边缘计算:有什么区别?

ChatGPT高效提问—prompt基础

二维平面阵列波束赋形原理和Matlab仿真

人工智能与机器学习——开启智能时代的里程碑
【GPU】深入理解GPU硬件架构及运行机制
新能源汽车智慧充电桩管理方案:环境监测与充电安全多维感知

大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解

从虚拟到现实:数字孪生驱动智慧城市可持续发展

如何使用人工智能优化 DevOps?
C# Onnx Chinese CLIP 通过一句话从图库中搜出来符合要求的图片

感知与认知的碰撞,大模型时代的智能文档处理范式
人工智能有哪些领域?

OpenCV:计算机视觉的强大工具库

使用LOTR合并检索提高RAG性能

【AI】人工智能复兴的推进器之神经网络

目标检测与测距算法在极端天气下的应用

AI时代架构设计新模式

深度解析 PyTorch Autograd:从原理到实践

AIGC实战——WGAN(Wasserstein GAN)

ChatGPT的常识


人工智能时代:AIGC的横空出世

【图像处理】使用各向异性滤波器和分割图像处理从MRI图像检测脑肿瘤(Matlab代码实现)

用AI攻克“智能文字识别创新赛题”,这场大学生竞赛掀起了什么风潮?
