文章目录
专栏导读
🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专门针对零基础和需要进阶提升的同学所准备的一套完整教学,从0到100的不断进阶深入,后续还有实战项目,轻松应对面试,专栏订阅地址:https://blog.csdn.net/yuan2019035055/category_11466020.html
- 优点:订阅限时9.9付费专栏进入千人全栈VIP答疑群,作者优先解答机会(代码指导、远程服务),群里大佬众多可以抱团取暖(大厂内推机会)
- 专栏福利:简历指导、招聘内推、每周送实体书、80G全栈学习视频、300本IT电子书:Python、Java、前端、大数据、数据库、算法、爬虫、数据分析、机器学习、面试题库等等
一、漏斗图介绍
1. 说明
漏斗图(Funnel plot)是一种用于可视化数据偏倚或选择性报告的图表。它通常用于汇总研究结果或元分析中的小样本研究或临床试验。漏斗图可以帮助研究人员或读者判断研究结果是否存在偏倚或选择性报告的情况。
漏斗图的基本结构是一个倒置的漏斗形状,其中包含了每个研究或试验的效应估计值(通常是效应量)和其置信区间。效应估计值通常在横轴上,而研究或试验的数量在纵轴上。漏斗图的宽度代表了每个研究或试验的精确度或权重,通常是以标准误差或置信区间的宽度表示。
2. 应用场景
漏斗图的主要应用场景包括:
研究结果的可视化:漏斗图可以将多个研究或试验的结果汇总在一起,直观地展示每个研究的效应估计值和置信区间。这有助于读者或决策者了解整体研究结果的分布情况。
发现选择性报告:漏斗图可以帮助检测研究结果的选择性报告。如果存在选择性报告,即小样本研究或试验的结果倾向于报告正向结果,那么漏斗图将会显示一个不对称的形状,即底部较宽,顶部较窄。
评估偏倚风险:漏斗图可以用于评估研究结果的偏倚风险。如果存在偏倚,即小样本研究或试验的结果倾向于偏离总体效应,那么漏斗图将会显示一个不对称的形状,即整个漏斗向左或向右倾斜。
检测出离群值:漏斗图可以帮助检测研究结果中的离群值。离群值可能是由于研究方法、样本特征或其他因素引起的异常结果。通过观察漏斗图,我们可以发现那些与其他研究结果相比明显偏离的研究或试验。
综上所述,漏斗图是一种用于可视化数据偏倚或选择性报告的图表工具。它可以帮助研究人员或读者判断研究结果是否存在偏倚或选择性报告,并在汇总研究结果或元分析中起到重要的辅助作用。
二、漏斗图类说明
1. 导包
from pyecharts.charts import Funnel
2. add函数
向图表中添加一个数据系列,包括系列名称、数据序列、颜色、排序方式、间隔、标签配置、提示框配置和样式配置等参数
add(
self,
series_name: str, # 系列名称,用于标识不同的数据系列
data_pair: types.Sequence, # 数据序列,包含一组数据对,每个数据对包括数据的名称和值
*,
color: types.Optional[str] = None, # 数据系列的颜色,可选参数,默认为None
sort_: str = "descending", # 数据排序方式,默认为降序排序
gap: types.Numeric = 0, # 数据之间的间隔,默认为0
label_opts: types.Label = opts.LabelOpts(), # 数据标签的配置选项,默认为空
tooltip_opts: types.Tooltip = None, # 数据提示框的配置选项,默认为None
itemstyle_opts: types.ItemStyle = None, # 数据项的样式配置选项,默认为None
)
三、漏斗图实战
1. 基础漏斗图
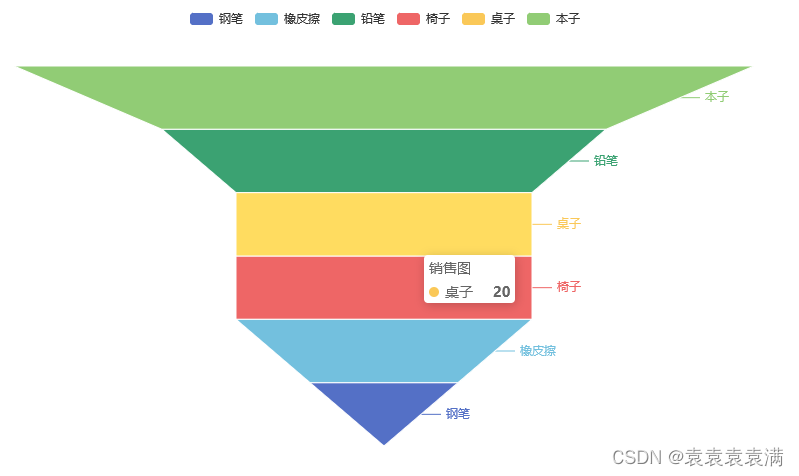
下面代码创建了一个基本的漏斗图,展示了商品的销售情况。Funnel()创建了一个漏斗图实例,.add()方法用于添加数据,[list(z) for z in zip(goods, sales)]将商品和销售数据进行组合。通过c.render()方法可以将图表保存为HTML文件,c.render_notebook()可以在Jupyter Notebook中直接显示漏斗图。
# 导入Funnel模块
from pyecharts.charts import Funnel
# 定义商品和销售数据
goods = ['钢笔', '本子', '桌子', '椅子', '橡皮擦', '铅笔']
sales = [10, 50, 20, 20, 20, 30]
# 创建漏斗图实例
c = (
Funnel()
.add("销售图", [list(z) for z in zip(goods, sales)]) # 添加数据
)
# 保存为HTML文件
c.render("basic_funnel.html")
# 在Jupyter Notebook中显示漏斗图
c.render_notebook()
运行结果:
2. 标签内漏斗图
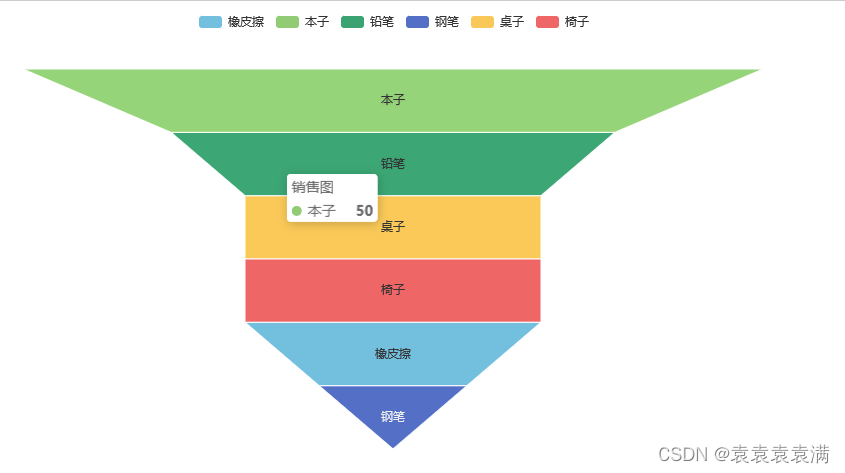
通过设置label_opts参数的position属性,你可以控制标签的位置。
position参数可以设置为以下值之一:
- “inside”:标签显示在漏斗图的内部,默认位置。
- “outside”:标签显示在漏斗图的外部。
例如,使用position="inside"可以将标签显示在漏斗图的内部。
# 导入Funnel模块
from pyecharts.charts import Funnel
from pyecharts import options as opts
# 定义商品和销售数据
goods = ['钢笔', '本子', '桌子', '椅子', '橡皮擦', '铅笔']
sales = [10, 50, 20, 20, 20, 30]
# 创建漏斗图实例
c = (
Funnel()
.add("销售图",
[list(z) for z in zip(goods, sales)],# 添加数据
label_opts=opts.LabelOpts(position="inside") # 标签设置在漏斗图内
)
)
# 保存为HTML文件
c.render("basic_funnel.html")
# 在Jupyter Notebook中显示漏斗图
c.render_notebook()
运行结果:
3. 百分比漏斗图
要在漏斗图中显示每个阶段的百分比,可以使用label_opts参数和formatter属性进行设置。以下是修改后的代码:
from pyecharts.charts import Funnel
from pyecharts import options as opts
# 定义商品和销售数据
goods = ['钢笔', '本子', '桌子', '椅子', '橡皮擦', '铅笔']
sales = [10, 50, 20, 20, 20, 30]
# 创建漏斗图实例
c = (
Funnel()
.add(
"销售图",
[list(z) for z in zip(goods, sales)],
label_opts=opts.LabelOpts(formatter="{b}: {d}%"), # 设置标签格式为 "商品名称: 百分比"
)
)
# 保存为HTML文件
c.render("百分比漏斗图.html")
# 在Jupyter Notebook中显示漏斗图
c.render_notebook()
在label_opts参数中,通过formatter属性设置标签的显示格式为"{b}: {d}%",其中{b}表示商品名称,{d}表示百分比。这样每个阶段的标签就会显示为"商品名称: 百分比"的形式。修改后的代码会生成一个带有百分比的漏斗图,并保存为HTML文件或在Jupyter Notebook中显示。
运行结果:
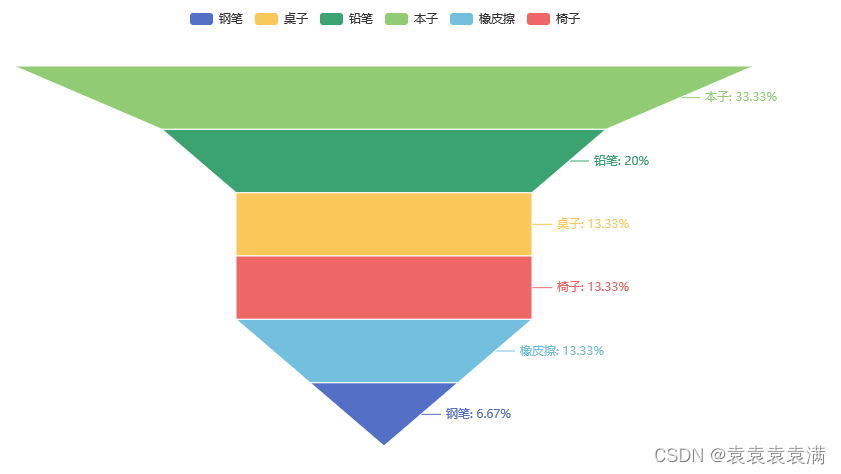
4. 向上排序漏斗图
通过在add函数添加sort_="ascending"参数修改排序方式:
from pyecharts.charts import Funnel
from pyecharts import options as opts
# 定义商品和销售数据
goods = ['钢笔', '本子', '桌子', '椅子', '橡皮擦', '铅笔']
sales = [10, 50, 20, 20, 20, 30]
# 创建漏斗图实例
c = (
Funnel()
.add(
"销售图",
[list(z) for z in zip(goods, sales)],
sort_="ascending", # 排序方法
label_opts=opts.LabelOpts(formatter="{b}: {d}%"), # 设置标签格式为 "商品名称: 百分比"
)
)
# 保存为HTML文件
c.render("百分比漏斗图.html")
# 在Jupyter Notebook中显示漏斗图
c.render_notebook()
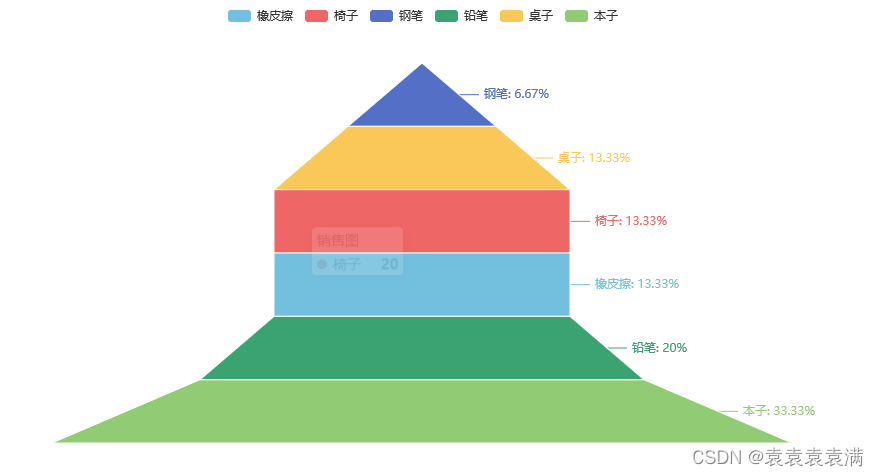
5. 标准漏斗图
from pyecharts import options as opts
from pyecharts.charts import Funnel
c = (
Funnel()
.add(
series_name="漏斗图系列名称",
data_pair=[("步骤1", 100), ("步骤2", 80), ("步骤3", 60), ("步骤4", 40), ("步骤5", 20)],
# 数据序列,每个数据对包括步骤名称和对应的值
gap=2, # 数据之间的间隔
sort_="descending", # 数据排序方式,这里使用降序排序
label_opts=opts.LabelOpts(position="inside"), # 数据标签的配置选项,这里设置标签在内部显示
)
.set_global_opts(
title_opts=opts.TitleOpts(title="标准漏斗图"), # 设置图表标题
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a} <br/>{b} : {c}%"), # 设置提示框的格式
)
)
# 保存为HTML文件
c.render("标准漏斗图.html")
# 在Jupyter Notebook中显示漏斗图
c.render_notebook()
运行结果:
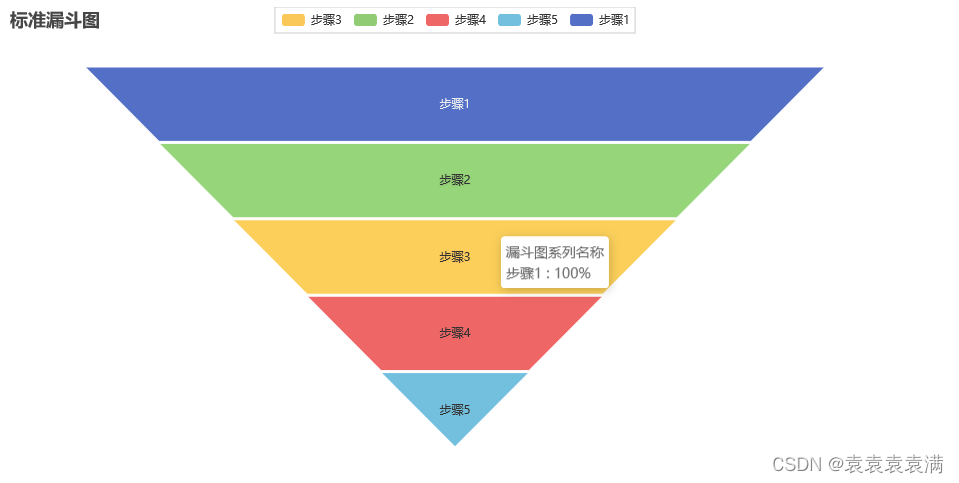
书籍推荐

清华社【秋日阅读企划】领券立享优惠
IT好书 5折叠加10元 无门槛优惠券:https://u.jd.com/Yqsd9wj
活动时间:9月4日-9月17日,先到先得,快快来抢

内容介绍:
《Vue.js从入门到精通》从初学者角度出发,通过通俗易懂的语言、丰富多彩的实例,详细介绍了使用Vue.js进行程序开发需要掌握的各方面技术。全书分为4篇,共19章,内容包括初识Vue.js、ECMAScript 6语法介绍、Vue实例与数据绑定、条件判断指令、v-for指令、计算属性和监听属性、元素样式绑定、事件处理、表单元素绑定、自定义指令、组件、组合API、过渡和动画效果、渲染函数、使用Vue Router实现路由、使用axios实现Ajax请求、Vue CLI、状态管理,以及51购商城项目实战。书中的大多数知识点都结合具体实例进行介绍,涉及的程序代码给出了详细的注释,使读者可轻松领会Vue.js程序开发的精髓,快速提高开发技能。
相关文章

使用Go Validator在Go应用中有效验证数据
C语言中关于#include的一些小知识


Go 是否有三元运算符?Rust 和 Python 是怎么做的?


Python3基础之import和from import的用法和区别
【C++】类与对象(构造函数、析构函数、拷贝构造函数、常引用)
C语言中的作用域与生命周期
Python和Java的区别(不断更新)


C#中的浅度和深度复制(C#如何复制一个对象)
梯度是什么,为什么联邦学习传递这个就可以更新模型?

VSCode python插件:找不到自定义包导致语法解析失败

C++ STL精通之旅:向量、集合与映射等容器详解

C#之linq和lamda表达式GroupBy分组拼接字符串


解决Linux环境下gdal报错:ERROR 4: `/xxx.hdf‘ not recognized as a supported file format.
C语言常见面试题:什么是枚举,枚举的作用是什么?

使用Opencv-python库读取图像、本地视频和摄像头实时数据
为什么Java中的String类被设计为final类?
Promise和箭头函数和普通函数的区别
详解动态网页数据获取以及浏览器数据和网络数据交互流程-Python

学习如何使用 Python 连接 MongoDB: PyMongo 安装和基础操作教程
ElasticSearch 集群搭建与状态监控cerebro

详解静态网页数据获取以及浏览器数据和网络数据交互流程-Python
【HarmonyOS】ArkTS语言介绍与组件方式运用
