1、安装qrcode库

我们在Terminal中用如下指令进行库的安装:
pip install qrcode[pil]
2、生成简单的二维码
import qrcode
img = qrcode.make('you are a pig.')
img.save('test.png')在上方代码中首先导入qrcode,然后用qrcode.make来对二维码所含信息进行填充,最后用save来对生成的二维码进行命名,从而得到一个简单的二维码。
3、生成自定义样式的二维码
import qrcode
from PIL import Image
# 定义要生成二维码的内容
data = "Hello, World!"
# 创建QRCode对象
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_H,
box_size=10,
border=4,
)
# 将数据添加到QRCode对象中
qr.add_data(data)
qr.make(fit=True)
# 生成QRCode图像
img = qr.make_image(fill_color="black", back_color="white")
# 添加Logo到二维码
logo = Image.open("logo.png")
img.paste(logo, (50, 50))
# 保存生成的二维码图像
img.save("custom_qrcode.png")
# 显示生成的二维码图像
img.show()在这个示例中,我们首先定义了要生成二维码的内容data。然后创建了一个QRCode对象,并设置了一些参数。接着,将数据添加到QRCode对象中,并生成二维码图像。我们还加载了一个Logo图像,并将其粘贴到生成的二维码图像上。最后,保存了生成的自定义样式的二维码图像,并显示了生成的二维码图像。
下面我将代码进行分开进行逐个讲解。
# 创建QRCode对象
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_H,
box_size=10,
border=4,
)在这段代码中,我们创建了一个
QRCode对象,并设置了一些参数来定义生成二维码的样式和属性。下面来解释一下这些参数的含义:
version=1: 这个参数指定了生成的二维码的版本。版本号从1到40,表示二维码的大小和数据容量。较高的版本号意味着更大的二维码,可以容纳更多的数据。在这里,我们设置为1,表示生成一个较小的二维码。
error_correction=qrcode.constants.ERROR_CORRECT_H: 这个参数指定了二维码的容错级别。容错级别决定了二维码在受损情况下的纠错能力。ERROR_CORRECT_H表示高级别的容错,可以在一定程度上修复受损的二维码数据。
box_size=10: 这个参数指定了二维码中每个小方块(模块)的像素大小。在生成的二维码图像中,每个数据点都映射为一个正方形的小模块,box_size指定了这个小模块的大小。
border=4: 这个参数指定了二维码图像周围的空白边框的大小,以保留一定的空间来避免二维码与其他元素重叠。border表示边框的宽度,这里设置为4个小模块的宽度。
qr.make(fit=True)在这段代码中,
qr.make(fit=True)是调用QRCode对象的make方法来生成二维码图像的操作。让我解释一下fit=True参数的含义:
fit=True: 这个参数指定了在生成二维码图像时,是否自动调整二维码的大小以适应数据。当fit参数设置为True时,生成的二维码图像会根据包含的数据自动调整大小,以确保所有数据都能被正确编码到二维码中。通过设置
fit=True参数,可以确保生成的二维码图像适合包含的数据,避免数据被截断或溢出。这样可以保证生成的二维码图像具有最佳的可读性和准确性。
4、生成带有链接的二维码
import qrcode
# 定义要生成二维码的链接
link = "https://www.example.com"
# 创建QRCode对象
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_Q,
box_size=10,
border=4,
)
# 将链接添加到QRCode对象中
qr.add_data(link)
qr.make(fit=True)
# 生成QRCode图像
img = qr.make_image(fill_color="black", back_color="white")
# 保存生成的二维码图像
img.save("link_qrcode.png")
# 显示生成的二维码图像
img.show()在这个示例中,我们定义了要生成二维码的链接link。然后创建了一个QRCode对象,并设置了一些参数。接着,将链接添加到QRCode对象中,并生成包含链接的二维码图像。最后,保存了生成的带有链接的二维码图像,并显示了生成的二维码图像。
5、可莉的小创作

可莉将一位优质的博主主页链接藏在了这个二维码里了,大家快去扫吧~
相关文章

使用Go Validator在Go应用中有效验证数据
C语言中关于#include的一些小知识

Go 是否有三元运算符?Rust 和 Python 是怎么做的?


Python3基础之import和from import的用法和区别
【C++】类与对象(构造函数、析构函数、拷贝构造函数、常引用)
C语言中的作用域与生命周期
Python和Java的区别(不断更新)


C#中的浅度和深度复制(C#如何复制一个对象)
梯度是什么,为什么联邦学习传递这个就可以更新模型?

VSCode python插件:找不到自定义包导致语法解析失败

C++ STL精通之旅:向量、集合与映射等容器详解

C#之linq和lamda表达式GroupBy分组拼接字符串


解决Linux环境下gdal报错:ERROR 4: `/xxx.hdf‘ not recognized as a supported file format.
C语言常见面试题:什么是枚举,枚举的作用是什么?

使用Opencv-python库读取图像、本地视频和摄像头实时数据
为什么Java中的String类被设计为final类?
Promise和箭头函数和普通函数的区别
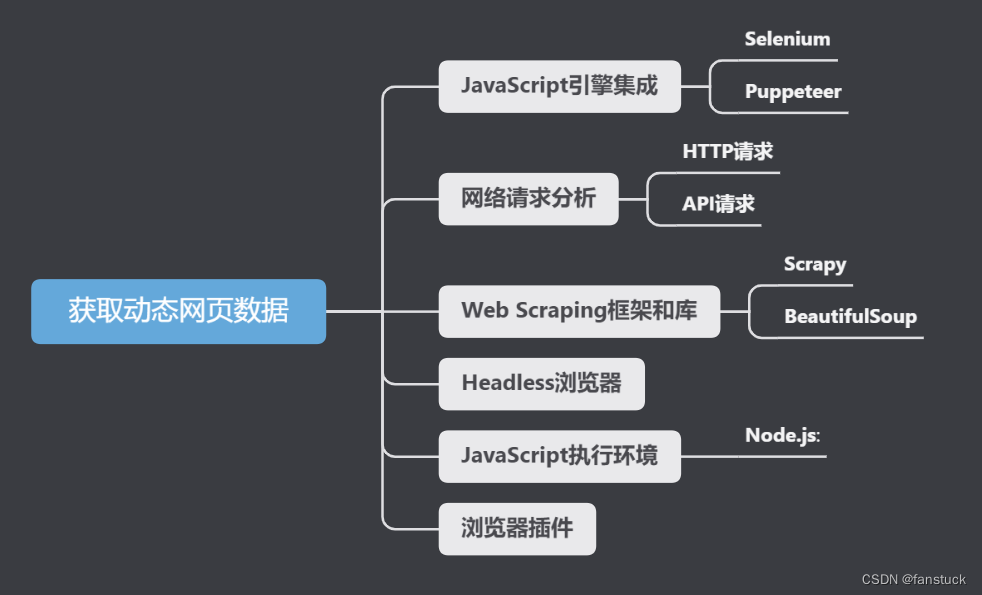
详解动态网页数据获取以及浏览器数据和网络数据交互流程-Python

学习如何使用 Python 连接 MongoDB: PyMongo 安装和基础操作教程
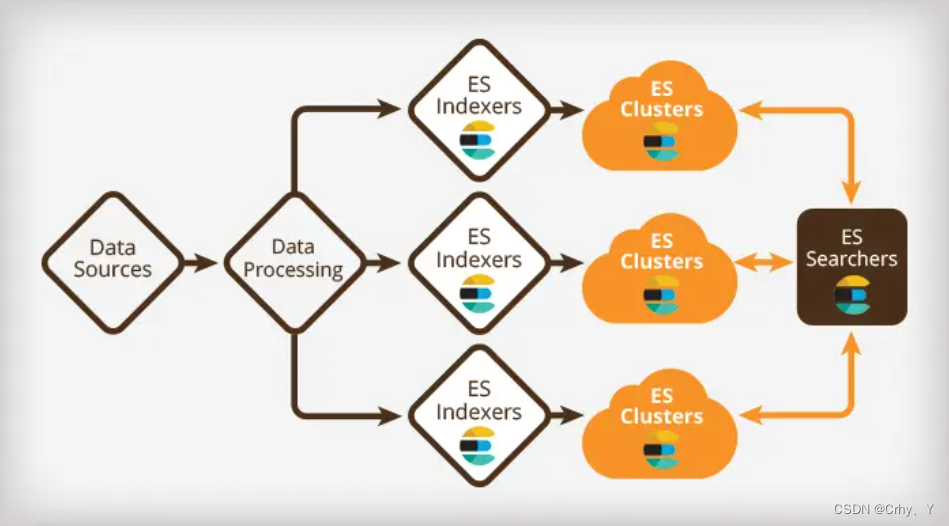
ElasticSearch 集群搭建与状态监控cerebro

详解静态网页数据获取以及浏览器数据和网络数据交互流程-Python
【HarmonyOS】ArkTS语言介绍与组件方式运用