作为一名开发者,确保Go应用中处理的数据是有效和准确的非常重要。Go Validator是一个开源的数据验证库,为Go结构体提供强大且易于使用的数据验证功能。本篇文章将介绍Go Validator库的主要特点以及如何在Go应用中使用它来有效验证数据。
什么是Go Validator?
Go Validator是一个开源的包,为Go结构体提供强大且易于使用的数据验证功能。该库允许开发者为其数据结构定义自定义验证规则,并确保传入的数据满足指定的条件。Go Validator支持内置验证器、自定义验证器,甚至允许您链式多个验证规则以满足更复杂的数据验证需求。
Go Validator的主要特点
内置验证器:
Go Validator内置了多个验证器,例如 email、URL、IPv4、IPv6 等。这些验证器可以直接用于常见的验证场景,节省了您的时间和精力。
自定义验证器:
如果内置验证器无法满足您的需求,您可以通过定义自己的验证函数来创建自定义验证器。这个功能允许您实现特定于应用程序需求的验证逻辑。
验证链:
Go Validator支持将多个验证器链接在一起,用于处理更复杂的验证场景。您可以创建一个验证器链,按顺序执行验证器,并在验证失败时停止,确保数据满足所有指定的条件。
错误处理:
Go Validator提供详细的错误信息,帮助您轻松地找到验证失败的原因。您可以自定义这些错误信息,使其更适合您的特定用例。
如何使用Go Validator
要开始使用Go Validator,首先需要使用以下命令在Go项目中安装该库:
go get -u github.com/go-playground/validator/v10
安装完成后,您就可以在Go应用中开始使用它了。以下是一个使用Go Validator验证简单数据结构的示例:
package main
import (
"fmt"
"github.com/go-playground/validator/v10"
)
type User struct {
Name string `validate:"required"`
Email string `validate:"required,email"`
Age int `validate:"gte=18"`
}
func main() {
u := &User{
Name: "tim",
Email: "abcdefg@gmail",
Age: 17,
}
validate := validator.New()
err := validate.Struct(u)
if err != nil {
fmt.Println("Validation failed:")
for _, e := range err.(validator.ValidationErrors) {
fmt.Printf("Field: %s, Error: %s \n", e.Field(), e.Tag())
}
} else {
fmt.Println("Validation succeeded")
}
}
对应的输出为:
Validation failed:
Field: Email, Error: email
Field: Age, Error: gte
在这个示例中,我们定义了一个User结构体,包含三个字段:Name、Email和Age。我们使用validate结构标签为每个字段指定验证规则。然后,我们创建一个新的验证器实例,并调用Struct方法验证我们的User实例。如果验证失败,将打印出错误信息,帮助我们找到失败的原因。
结论
Go Validator是一个强大而灵活的库,可用于在Go应用中验证数据。通过使用内置验证器、自定义验证器和验证链,您可以创建健壮的验证逻辑,确保应用程序处理准确和有效的数据。通过引入Go Validator,您可以提高应用程序的数据质量,并减少潜在的错误和问题。
相关文章

Springboot中如何记录好日志

C语言中关于#include的一些小知识


Go 是否有三元运算符?Rust 和 Python 是怎么做的?


Python3基础之import和from import的用法和区别
【C++】类与对象(构造函数、析构函数、拷贝构造函数、常引用)
C语言中的作用域与生命周期
Python和Java的区别(不断更新)


C#中的浅度和深度复制(C#如何复制一个对象)

C++ STL精通之旅:向量、集合与映射等容器详解
C#之linq和lamda表达式GroupBy分组拼接字符串
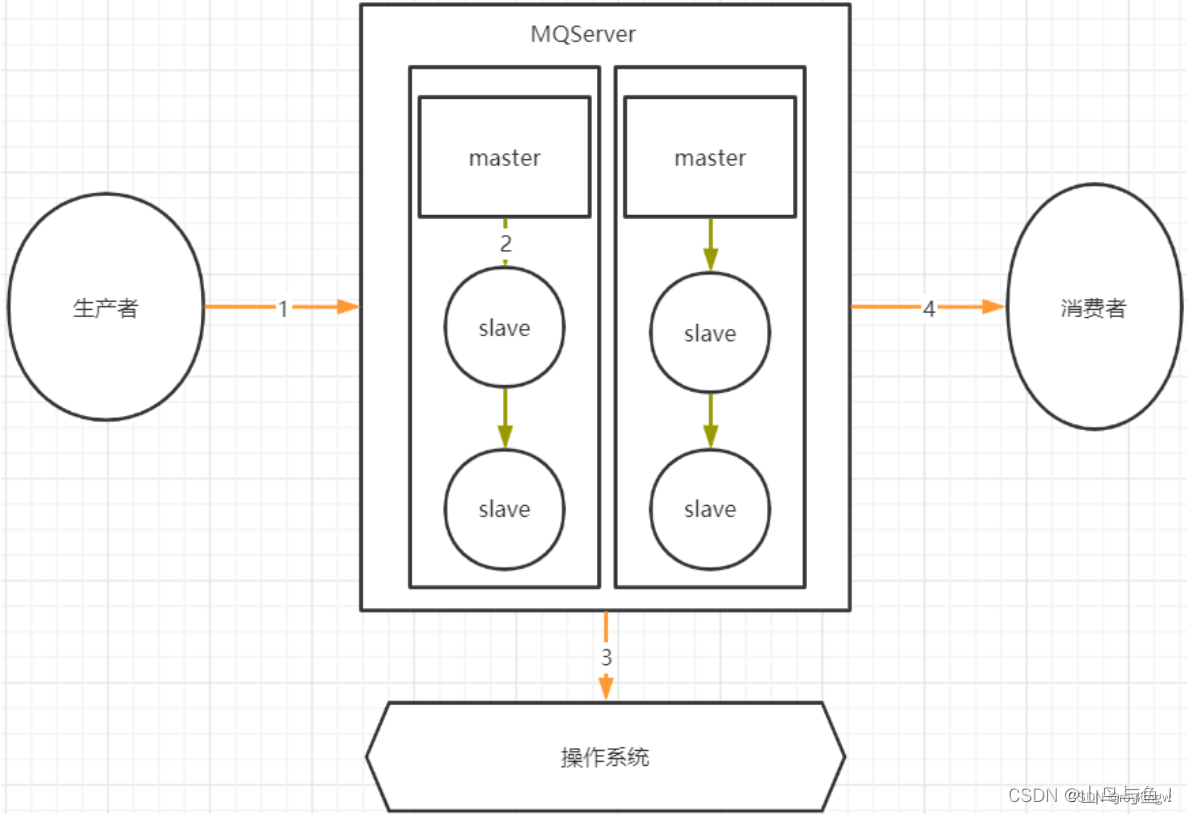
Kafka常见生产问题详解
Zookeeper分布式队列实战


解决Linux环境下gdal报错:ERROR 4: `/xxx.hdf‘ not recognized as a supported file format.
C语言常见面试题:什么是枚举,枚举的作用是什么?
Web 安全之点击劫持(Clickjacking)攻击详解
为什么Java中的String类被设计为final类?

SpringBoot:详解Bean生命周期和作用域
计算机组成原理 CPU的功能和基本结构和指令执行过程
Promise和箭头函数和普通函数的区别
ElasticSearch 集群搭建与状态监控cerebro
【HarmonyOS】ArkTS语言介绍与组件方式运用

SpringMVC之获取请求参数和域对象共享数据
