随着双碳战略的提出和电池技术、电动机技术等的不断进步,新能源汽车最近几年势头很猛,借着一份汽车销售数据一起来了解一下新能源汽车目前的市场情况,大家买电车的说不定可以用上,毕竟这可是购车群体用脚投票出来的大数据。
1.数据处理
本文数据来自和鲸平台,主要包含了2015~2023年11月各厂商各新能源车型的销量数据。
import pandas as pd
data=pd.read_excel('中国电动车每月销售表.xlsx')
data.head()

car_data=pd.read_excel('中国汽车总体销量.xlsx')
car_data['年份']=car_data['时间'].map(lambda x:int(str(x)[:4]))
car_data=car_data.groupby(['年份']).agg({"销量":"sum"}).reset_index()
car_data.columns=['年份','汽车总体销量']
car_data.head()

2.数据解读
2.1 近几年新能源汽车发展趋势
a.新能源汽车销量变化
## 15~23年销量变化
t1=data.groupby(['年份']).agg({"销量":"sum"}).reset_index()
t1['上一年销量']=t1['销量'].shift(periods=1,fill_value=0)
t1['同比增速']=(t1['销量']/t1['上一年销量'])-1
t1=pd.merge(t1,car_data,on=['年份'],how='left')
t1['电动车销量占比']=t1['销量']/t1['汽车总体销量']
##电动车销量占比
t1=pd.merge(t1,car_data,on=['年份'],how='left')
t1['电动车销量占比']=t1['销量']/t1['汽车总体销量']
t1

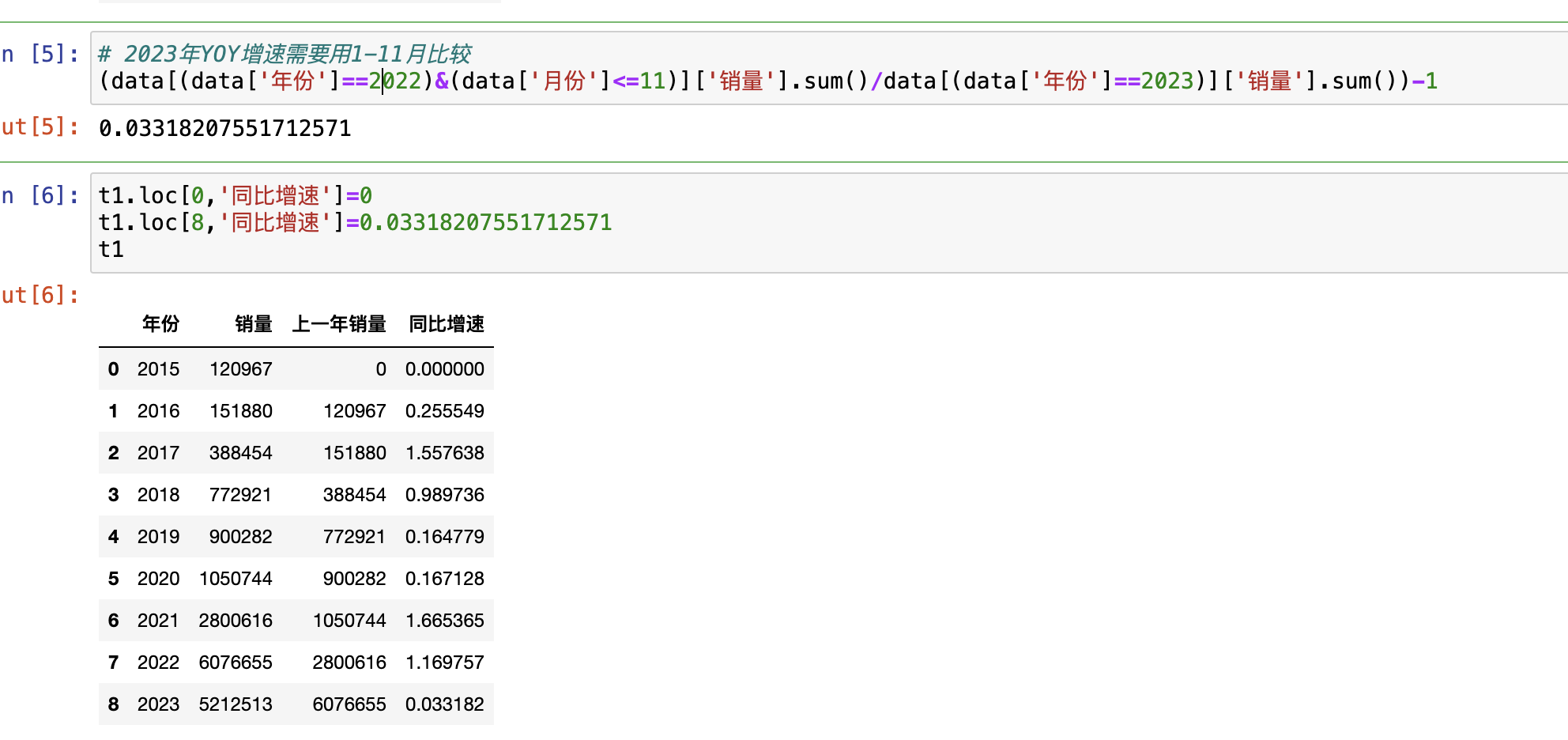
2015年新能源汽车仅12万辆,占比汽车总销量仅0.6%。2016至2018年增长迅速,但在2019和2022年停在100万辆,2021年又开始增长,到2023年(截止11月份),新能源汽车销量达到521万辆,占比汽车总销量达到34%。
b.新能源汽车厂商数量变化
data.groupby(['年份']).agg({"厂商":"nunique"}).reset_index()

2015年新能源汽车厂商仅7家,从2018年开始剧增,到2021年稳定在80多家,2023年为85家。
- 2015年哪7家是最早吃螃蟹的人?
data[data['年份']==2015]["厂商"].unique()
2015年新能源汽车厂商仅有7家,分别为’众泰新能源’, ‘一汽丰田’, ‘比亚迪’, ‘上汽集团’, ‘东风日产’, ‘腾势汽车’, ‘知豆电动车’。
list_2015=data[data['年份']==2015]["厂商"].unique()
list_2023=data[data['年份']==2023]["厂商"].unique()
list3=[x for x in list_2023 if x in list_2015]
list3
很牛的是这7家中到了2023年,还有5家(‘比亚迪’, ‘腾势汽车’, ‘东风日产’, ‘上汽集团’, ‘一汽丰田’)仍然活跃在市场上,
- 2015到2023年中哪些厂商消失在新能源汽车市场里了?
list_all=data["厂商"].unique()
print(len(list_all)-len(list_2023))
len(list_2023)/len(list_all)
2015到2023年一共有116家厂商在新能源汽车市场活跃过,到2023年有85家还在活跃,存活率73%,期间有31家厂商退出市场。
list_out=[x for x in list_all if x not in list_2023]
data[data['厂商'].isin(list_out)].groupby(['厂商']).agg({"销量":"sum"}).reset_index().\
sort_values(by=['销量'],ascending=False)

退出市场的31家中,历史销量破10万辆的为’众泰新能源’和’江淮汽车’。'众泰新能源’为2015年吃螃蟹的7家厂商之一,另一家类似命运的’知豆电动车’历史销量为7万辆。
2.2 2023年新能源汽车市场
a.2023哪些厂商卖的好
t2=data[data['年份']==2023].groupby(['厂商']).agg({"销量":"sum"}).sort_values(by=['销量'],ascending=False).reset_index()
t2['厂商']=t2.apply(lambda x: '其他' if x.销量<=50000 else x.厂商,axis=1)
t2=t2.groupby(['厂商']).agg({"销量":"sum"}).sort_values(by=['销量'],ascending=False).reset_index()
t2
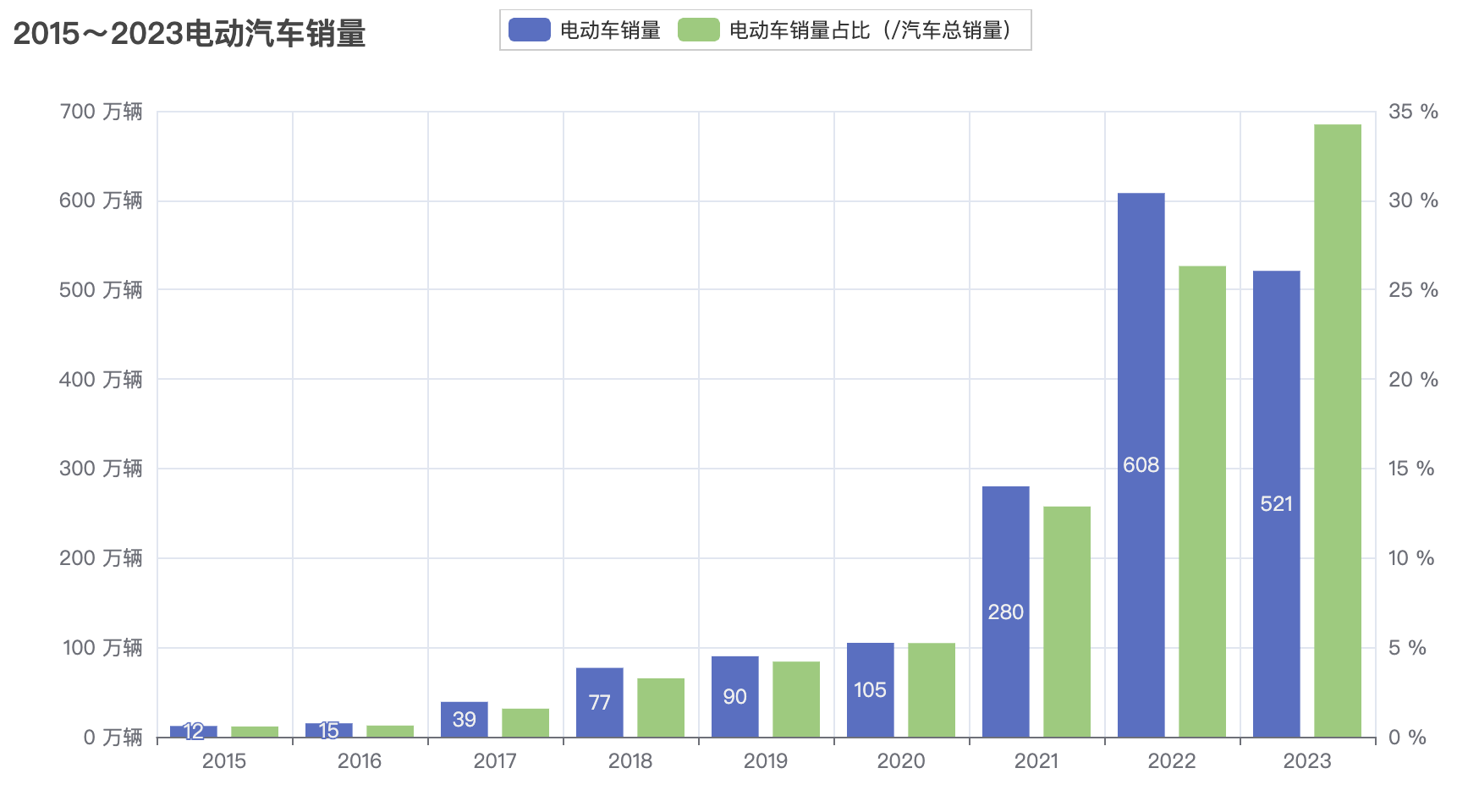
2023年(截止11月份)比亚迪市场销量203万辆,占比39%,稳居top1。远超第二名特斯拉(46万辆,9%)和第三名上汽通用五菱(32万辆,6%)。
蔚小理中目前理想遥遥领先(28万辆,5%),蔚来(11万辆,2%),小鹏(7万辆,1%)。
b.2023哪些车型卖的好
t3=data[data['年份']==2023].groupby(['车型','厂商']).agg({"销量":"sum",'平均价位':"mean"}).sort_values(by=['销量'],ascending=False).reset_index()
t3.head(20)

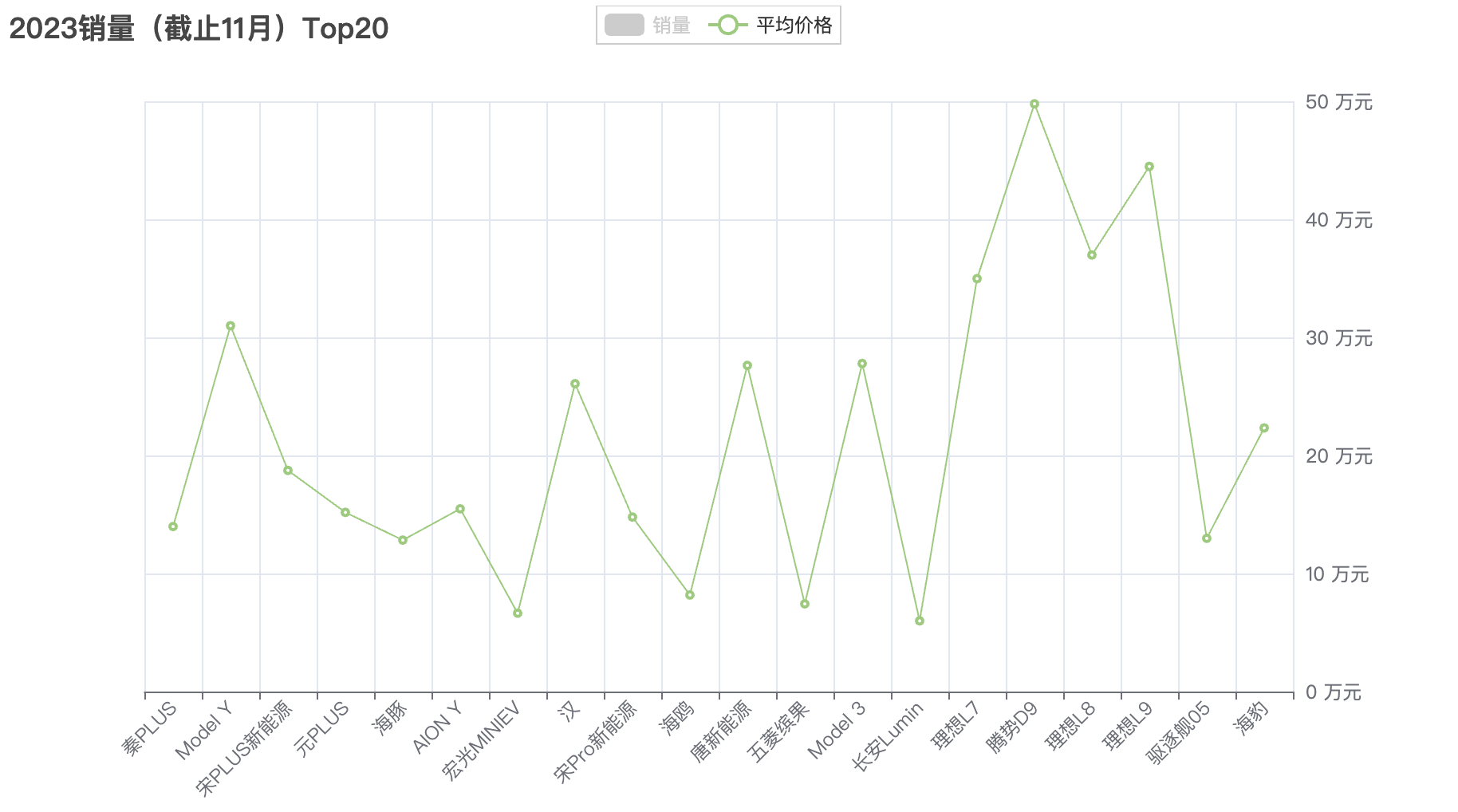
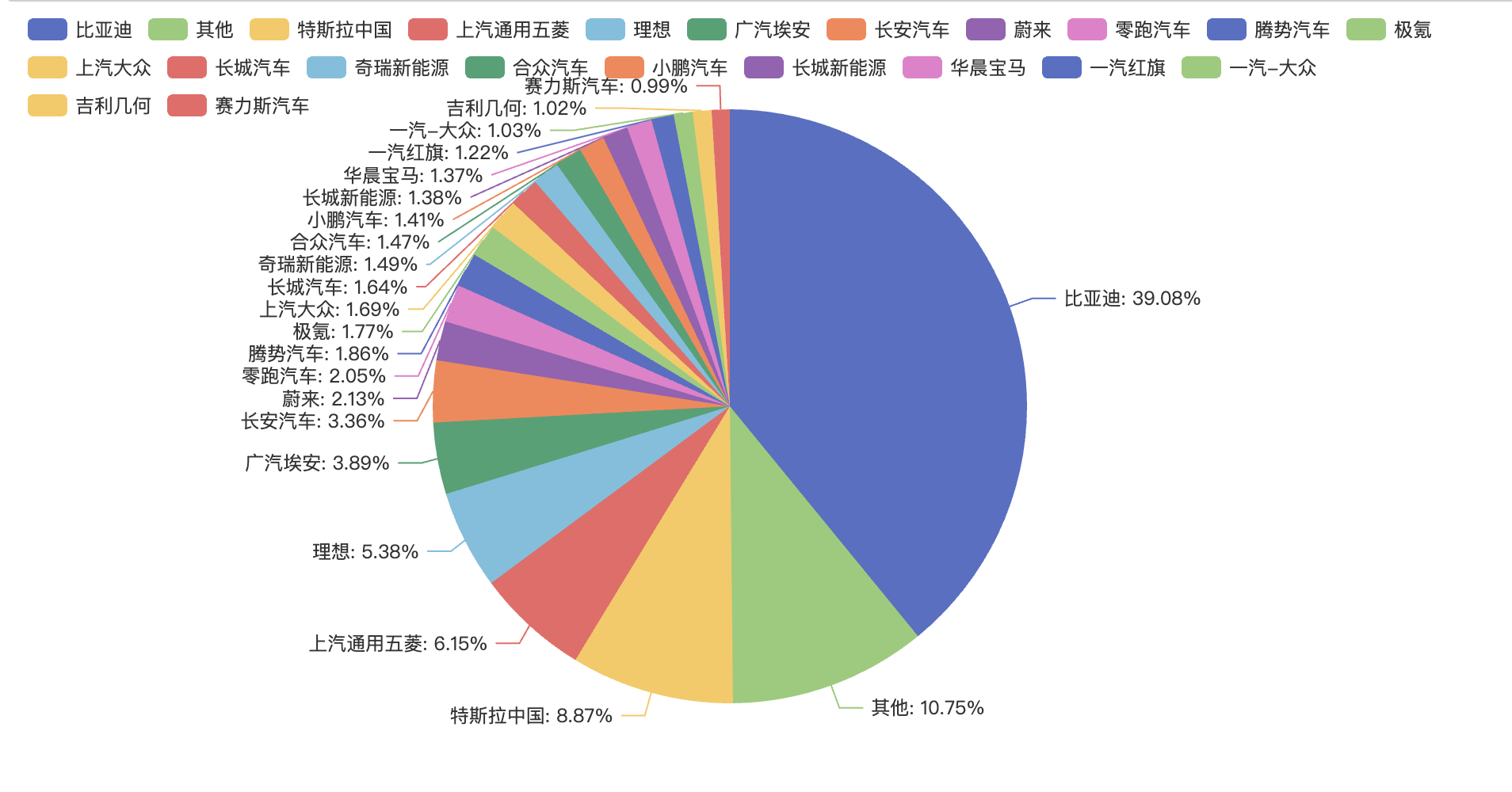
2023年(截止11月份)Top20车型里有10个车型都是比亚迪的,均价大都在20万以下,走的亲民路线。而其中比亚迪汉和比亚迪唐均价达到30万附近。
特斯拉的爆款是ModelY和Model3,均价都在30万左右,分别卖了35万辆(销量第2)和12万辆(销量第13)。
理想的3款爆款车为L7、L8、L9,均在30万以上,理想L9更是达到44万。
腾势汽车的D9均价50万,是Top20畅销车型里最贵的,卖了9.7万辆。
Top20畅销车型有4款车在10万以下,长安Lumin 5.9万、宏光MINIEV 6.6万、五菱缤果 7.4万、比亚迪海鸥 8.2万
相关文章


Go 是否有三元运算符?Rust 和 Python 是怎么做的?


Python3基础之import和from import的用法和区别

Python和Java的区别(不断更新)
梯度是什么,为什么联邦学习传递这个就可以更新模型?

VSCode python插件:找不到自定义包导致语法解析失败



解决Linux环境下gdal报错:ERROR 4: `/xxx.hdf‘ not recognized as a supported file format.

使用Opencv-python库读取图像、本地视频和摄像头实时数据
新能源汽车智慧充电桩管理方案:环境监测与充电安全多维感知

大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解
详解动态网页数据获取以及浏览器数据和网络数据交互流程-Python

学习如何使用 Python 连接 MongoDB: PyMongo 安装和基础操作教程

从虚拟到现实:数字孪生驱动智慧城市可持续发展
ElasticSearch 集群搭建与状态监控cerebro

Zoho SalesIQ:构建客户服务知识库的实用工具与指南

详解静态网页数据获取以及浏览器数据和网络数据交互流程-Python

Hadoop之MapReduce 详细教程
Jupyter Notbook+cpolar内网穿透实现公共互联网访问使用数据分析工作
如何在Spring Boot中优雅地进行参数校验

Python使用多线程解析超大日志文件
基于Python Django的内容管理系统Wagtail CMS部署与公网访问

Python将列表中的数据写入csv并正确解析出来

【Java 基础篇】Java TCP通信详解

【Java 基础篇】Java网络编程实战:P2P文件共享详解
