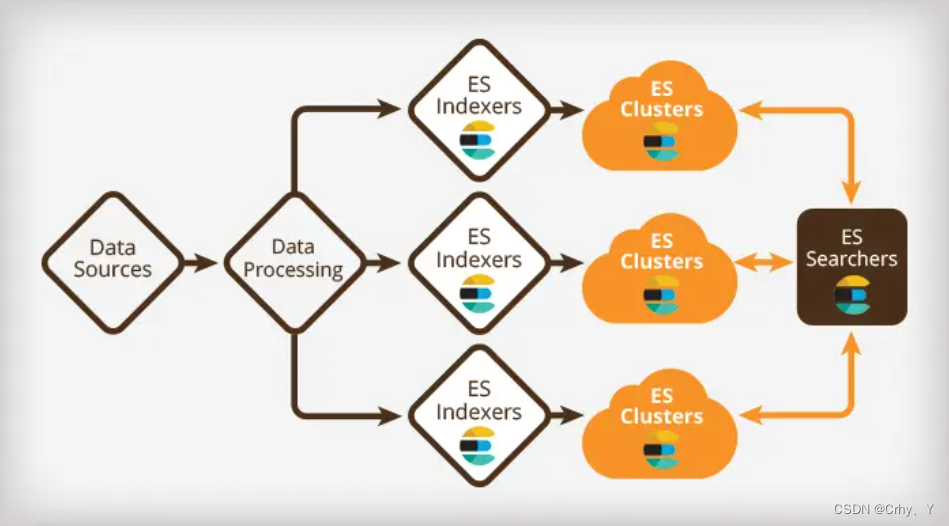
单机的elasticsearch做数据存储,必然面临两个问题:海量数据存储问题、单点故障问题。为了解决存储能力上上限问题就可以用到集群部署。
- 海量数据存储问题:将索引库从逻辑上拆分为N个分片(shard),存储到多个节点
- 单点故障问题:将分片数据在不同节点备份 (replica )
目录
二、集群搭建案例:利用3个docker容器模拟3个es的节点
2.1 首先编写一个docker-compost文件,代码如下
一、部署es集群
在单机上利用docker容器运行多个es实例来模拟es集群。在生产环境中推荐每一台服务节点仅部署一个es的实例。
部署es集群可以直接使用docker-compose来完成,但要求Linux虚拟机至少有4GI的内存空间。
二、集群搭建案例:利用3个docker容器模拟3个es的节点
2.1 首先编写一个docker-compost文件,代码如下
version:"2.2
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node .name=ego1
-cluster.name=es-docker-cluster
-discovery.seed_hosts=es02,es3
-cluster.initial_master_nodes=es1es02 ,es03
-"ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
-data01:/usr/share/elasticsearch/data
ports:
-9200:9200
networks:
-elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
-node.name=es02
-cluster.name=es-docker-cluster
-discovery.seed_hosts=es01,es03
-cluster.initial_master_nodes=es01,es02,es03
-"ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
-data02:/usr/share/elasticsearch/data
ports:
9201:9200
networks:
-elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
-node.name=es03
-cluster.name=es-docker-cluster
-discovery.seed_hosts=es01,es02
-cluster.initial_master_nodes=es01,es02,es03
-"ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
-data03:/usr/share/elasticsearch/data
ports:
9202:9200
networks:
-elastic
2.2 es运行需要修改一些lintx系统权限
(1) 修改 /etc/sysctl.conf 文件
vi /etc/sysctl.conf
(2) 添加下面的内容
vm.max_map_count=262144
(3) 然后执行命令,让配置生效
sysctl -p
(4) 通过docker-compose启动集群
docker-compose up -d
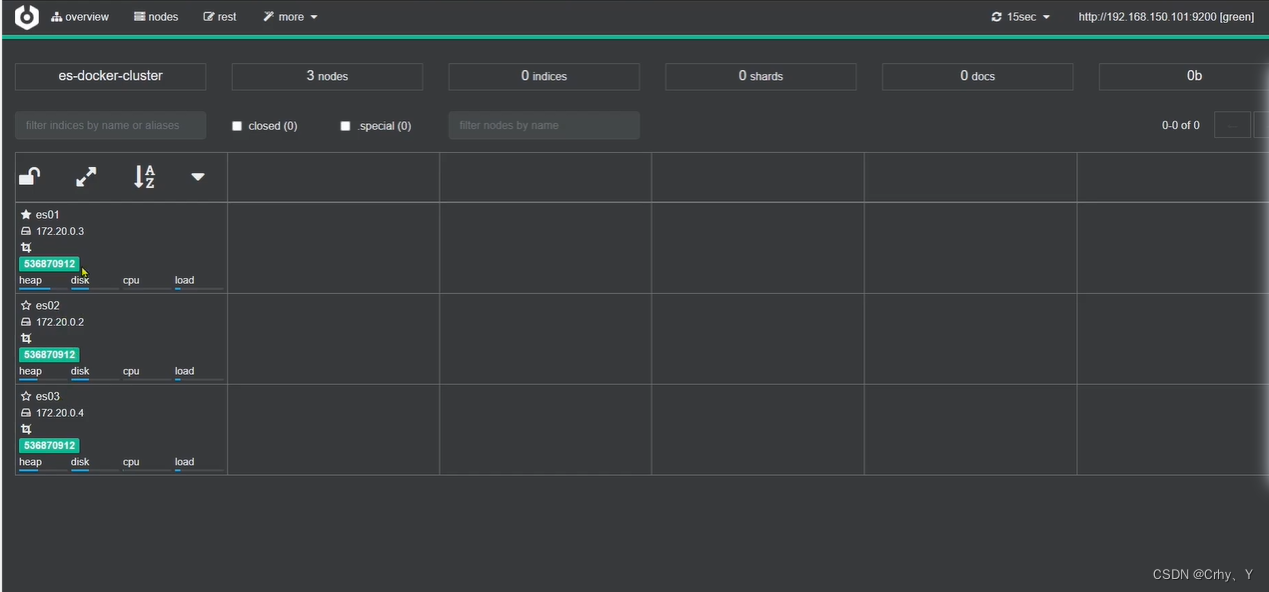
2.3 集群状态监控(cerebro)
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能,配置比较复杂。
推荐使用cerebro来监控es集群状态,官方网址:https://github.com/lmenezes/cerebro
启动 cerebro 服务

访问登录cerebro
集群状态
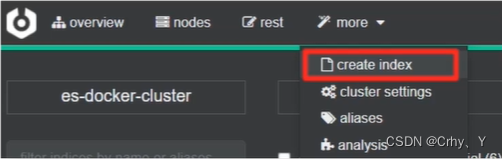
2.4 创建索引库
第一种方式:利用kibana的DevTools创建索引库 ,在DevTools中输入指令
PuT /itcast
{
"settings" : {
"number_of_shards": 3,// 分片款量"number_of_replicas": 1 // 副本数
},
"mappings" : {
"properties":{
//mapping晚射定义
}
}
}
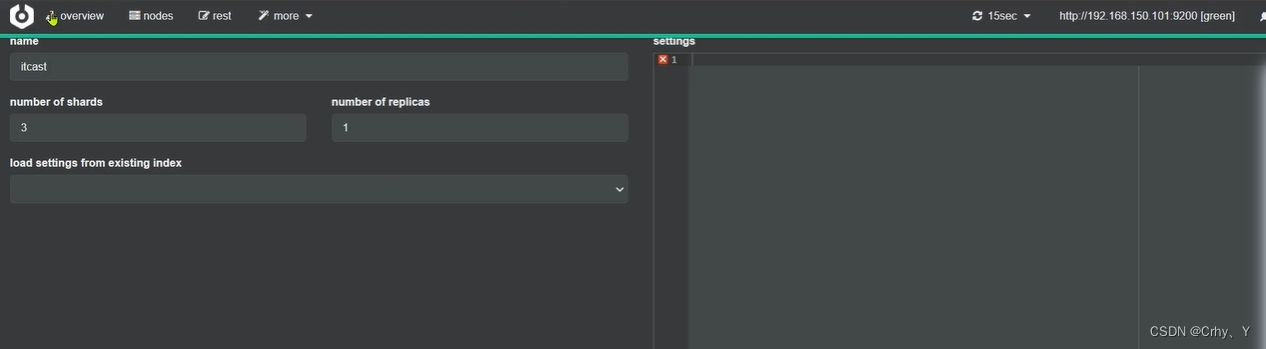
第二种方式:利用cerebro创建索引库
填写索引库信息
相关文章

使用Go Validator在Go应用中有效验证数据
Go Validator是一个开源的包,为Go结构体提供强大且易于使用的数据验证功能。该库允许开发者为其数据结构定义自定义验证规则,并确保传入的数据满足指定的条件。Go Validator支持内置验证器、自定义验证器,甚至允许您链式多个验证规则以满足更复杂的数据验证需求。如果内置验证器无法满足您的需求,您可以通过定义自己的验证函数来创建自定义验证器。这个功能允许您实现特定于应用程序需求的验证逻辑。
编程日记 2024/03/03 13:53:57
【JS】【Vue3】【React】获取鼠标位置的方法:JavaScript、Vue 3和React示例
随着Web应用程序的复杂性不断增加,获取用户交互信息变得越来越重要。其中,获取鼠标位置是一项常见的任务,可以用于实现各种交互效果,如拖拽、悬停提示等。本文将探讨在JavaScript、Vue 3和React中获取鼠标位置的不同方法,并提供相应的示例。
编程日记 2024/02/28 09:12:05

Springboot中如何记录好日志
springboot项目如何配置日志,日志门面和日志实现的区别是什么,如何通过日志切面将日志和代码解耦,这里都有分享。
编程日记 2024/02/27 21:34:27
Java实战:定制Spring MVC拦截器链
本文将详细介绍如何定制Spring MVC拦截器链。我们将探讨Spring MVC拦截器的基本概念,以及如何使用Spring Boot和Spring MVC来实现自定义拦截器
编程日记 2024/02/24 08:34:15
C语言中关于#include的一些小知识
如果是你自己编写的头文件,那么如果没加唯一包含标识的话,那么编译器会编译报错的。如果是系统自带的头文件,由于其每个头文件都加了特殊标识,所以即使你包含两遍,也不会有问题。上面的代码片段会首先判断HEADER_FILE_NAME_H是否被定义,若未定义则进行后续操作;#ifndef HEADER_FILE_NAME_H // 定义了一个名为HEADER_FILE_NAME_H的标记符号。#define HEADER_FILE_NAME_H // 当第一次包含该头文件时,将此标记设置为已定义状态。
编程日记 2024/02/22 09:01:42

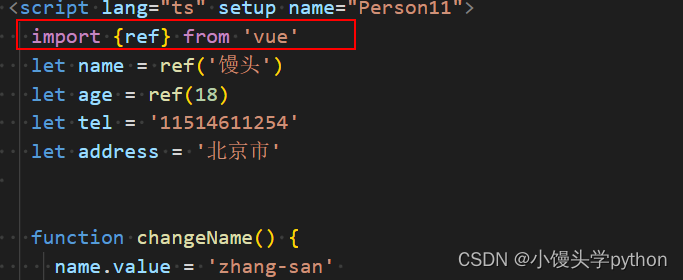
【Vue3】使用ref与reactive创建响应式对象
先来简单介绍一下ref,它可以定义响应式的变量let xxx = ref(初始值)。**返回值:**一个RefImpl的实例对象,简称ref对象或refref对象的value属性是响应式的。JSxxx.value,但模板中不需要.value,直接使用即可。对于let name = ref('张三')来说,name不是响应式的,name.value是响应式的。下面我们看一看上图红框中代表的意思是,我们哪里需要响应就在哪个里面导入上述代码即可。
编程日记 2024/02/21 09:49:43
如何设置页面恢复运行事件触发回调
由于 Android 原生的 resume 和 pause 事件不能区分是压后台导致还是页面切换导致,所以 pageResume 和 pagePause 事件是通过 JSAPI 调用记录回调的,仅适用于同一个 session 内 Window 之间的互相切换。当一个 WebView 界面重新回到栈顶时,例如从后台被唤起、锁屏界面恢复、从下个页面回退,会触发页面恢复运行(resume)事件。如果这个界面是通过 popWindow 或 popTo 到达,且传递了 data 参数,则此页可以获取到这些参数。
编程日记 2024/02/21 09:47:28

日常遇到Maven出现依赖版本/缓存问题通用思路。
如果怀疑是本地仓库中缓存的依赖有问题,可以手动删除本地仓库(默认位置在用户的.m2/repository目录下),但这是一个较为极端的做法,因为这会删除所有项目的所有本地依赖,之后Maven将不得不重新下载这些依赖。针对于这样的问题 首先我们的第一思路 就是怀疑到是缓存的问题,那么我在这里去描述一下 我们遇到这类通用类的问题如何解决。检查项目的pom.xml文件,确认依赖声明正确无误,没有冲突的版本号或不正确的依赖范围。版本问题导致的,但是我确认过了一下的一些操作 依然没有解决我的问题。
编程日记 2024/02/21 09:45:27

Python3基础之import和from import的用法和区别
一个 python 的文件就叫做模块(module),如 xxx.py。模块就是一组功能的集合体,我们的程序可以导入模块来复用模块里的功能。
编程日记 2024/02/20 22:34:44
【C++】类与对象(构造函数、析构函数、拷贝构造函数、常引用)
💬 hello!各位铁子们大家好哇。今日更新了类与对象的构造函数、析构函数、拷贝构造函数、常引用的内容。
编程日记 2024/02/20 22:31:57
什么是tomcat?tomcat是干什么用的?
Tomcat是一个开源的、轻量级的应用服务器,是Apache软件基金会的一个项目。它实现了Java Servlet、JavaServer Pages(JSP)和Java Expression Language(EL)等Java技术,用于支持在Java平台上运行的动态Web应用程序。AJP是用于Apache服务器与Tomcat之间进行通信的协议,通常用于将动态生成的内容传递给Apache服务器进行处理。它能够运行Servlet和JSP,提供了一个环境,使得开发者能够构建和运行基于Java的Web应用。
编程日记 2024/02/19 20:51:12
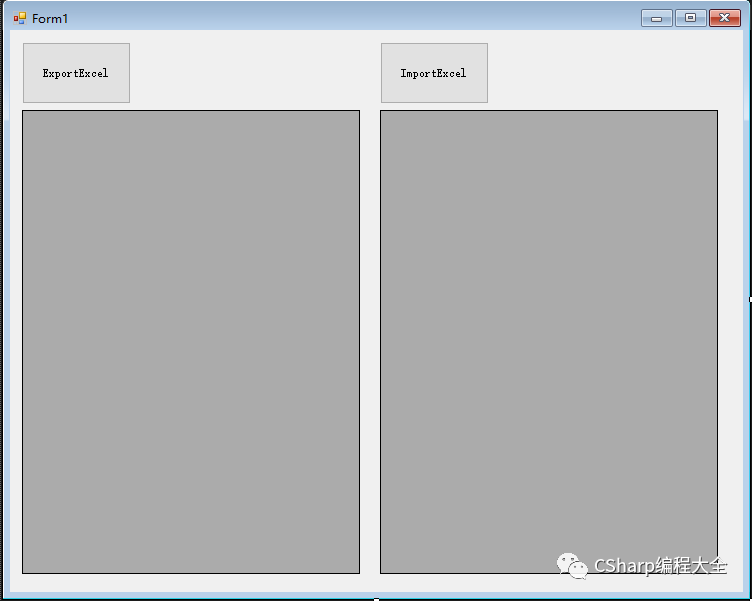
C# winfrom中excel文件导入导出
在C#交流群里,看到很多小伙伴在excel数据导入导出到C#界面上存在疑惑,所以今天专门做了这个主题,希望大家有所收获!环境:win10+vs2017界面:主要以演示为主,所以没有做优化,然后主界面上添加两个按钮,分别命名为ExportExcel和ImportExcel,添加两个dataGridView,分别是dataGridView1和dataGridView2然后在窗体加载程序中给dataGr...
编程日记 2024/02/17 14:00:34
maven实战:Centos7.9原生安装maven
通过官网https://maven.apache.org下载 后缀名为.tar.gz的压缩包。将压缩包上传到服务器/usr/local/bin 目录下,使用以下命令解压。
编程日记 2024/02/16 20:31:50
Java 与 JavaScript 的区别与联系
Java 和 JavaScript 两种编程语言在软件开发中扮演着重要的角色。尽管它们都以“Java”命名,但实际上它们是完全不同的语言,各有其独特的特点和用途。本文将深入探讨 Java 和 JavaScript 的区别与联系,帮助大家更好地理解它们在编程世界中的作用。
编程日记 2024/02/13 20:01:28
C语言中的作用域与生命周期
但是全局变量被 static 修饰之后,外部链接属性就变成了内部链接属性,只能在自己所在的源文件内部使用了,其他源文件,即使声明了,也是无法正常使用的。结论:static修饰局部变量改变了变量的生命周期,生命周期改变的本质是改变了变量的存储类型,本来一个局部变量是存储在内存的栈区的,但是被 static 修饰后存储到了静态区。extern 是用来声明外部符号的,如果一个全局的符号在A文件中定义的,在B文件中想使用,就可以使用extern进行声明,然后使用。全局变量的生命周期是:整个程序的生命周期。
编程日记 2024/02/13 20:00:24
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务
编程日记 2024/02/13 19:58:42
Python和Java的区别(不断更新)
运行效率:一般来说,Java的运行效率要高于Python,这主要是因为Java是编译型语言,其代码在执行前会进行预编译,而Python是解释型语言,边解释边执行。而Python没有类似的强大虚拟机,但它的核心是可以很方便地使用C语言函数或C++库,这使得Python可以轻松地与底层硬件进行交互。**类型系统:**Java是一种静态类型语言,所有变量需要先声明(类型)才能使用,且类型在编译时就已经确定。总的来说,Python和Java各有其优势和特点,选择哪种语言取决于具体的项目需求、开发环境以及个人偏好。
编程日记 2024/02/11 20:37:25


服务器与电脑的区别?
服务器是指一种专门提供计算和存储资源、运行特定软件服务的物理或虚拟计算机。服务器主要用于接受和处理来自客户端(如个人电脑、手机等)的请求,并向客户端提供所需的服务或数据。服务器在网络环境中扮演着中心节点的角色,负责存储和管理数据、提供网络服务、处理计算任务等。
编程日记 2024/02/10 19:41:26

C#中的浅度和深度复制(C#如何复制一个对象)
接着,我们修改了复制得到的对象及其引用类型字段的属性值,最后输出原始对象和复制对象的属性值。这意味着如果一个类包含引用类型成员,在执行深度复制时,不仅复制这些引用,还会递归地复制引用所指向的对象,直到所有的引用都指向全新的对象实例。当进行浅复制时,系统会创建一个新的对象实例,但这个新对象的字段将与原始对象中的值类型字段具有相同的值,而对于引用类型字段,则仅仅是复制了。也就是说,如果一个类中有引用类型的成员变量(比如数组、其他自定义类的对象等),那么浅复制后,新对象和原对象的这些引用类型成员仍然指向。
编程日记 2024/02/10 19:40:51
windows下ngnix自启动(借助工具winSw)
在windows下安装nginx后,不想每次都手动启动。本文记录下windows下ngnix自启动(借助工具winSw)的操作流程提示:以下是本篇文章正文内容,下面案例可供参考本文记录下windows下ngnix自启动(借助工具winSw)的操作流程。
编程日记 2024/02/08 18:11:23

C++ STL精通之旅:向量、集合与映射等容器详解
STL 作为一个封装良好,性能合格的 C++ 标准库,在算法竞赛中运用极其常见。灵活且正确使用 STL 可以节省非常多解题时间,这一点不仅是由于可以直接调用,还是因为它封装良好,可以让代码的可读性变高,解题思路更清晰,调试过程往往更顺利。
编程日记 2024/02/07 09:13:30
synchronized 和 Lock 有什么区别?synchronized 和 ReentrantLock 区别是什么?说一下 atomic 的原理?
例如,AtomicInteger 的 incrementAndGet() 方法就是通过 CAS 操作实现的,它首先尝试原子地将共享变量加 1,如果操作成功,则返回新的值,否则重试直到操作成功为止。CAS 操作的原理是,当 V 的值等于 A 时,将 V 的值更新为 B,否则什么也不做。synchronized 和 Lock 都是 Java 中用于实现线程同步的关键字/类库,它们都能够提供对共享资源的安全访问和防止数据竞争的功能,但是在实现方式、特性、适用场景等方面存在一些差异。
编程日记 2024/02/07 09:09:26
C#之linq和lamda表达式GroupBy分组拼接字符串
点击提示信息,如:“售后单【SH001】序列号【001,002,006】;售后单【SH002】序列号【003,007,009】。已经过了质保期,确认要继续关闭吗”
编程日记 2024/02/05 08:46:19
Java开发四则运算-使用递归和解释器模式
四则运算Expression implement。ExpressionParser 核心实现类。Context 编写测试代码。
编程日记 2024/02/03 10:54:40
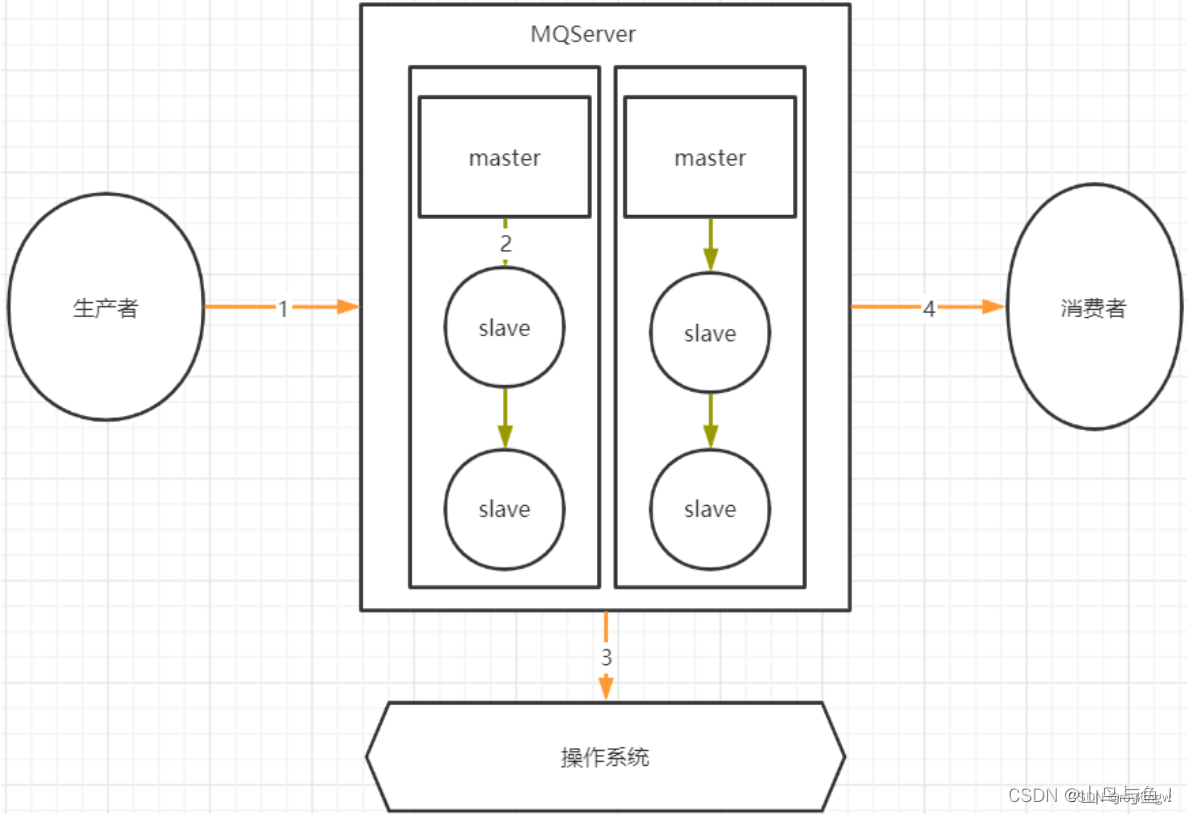
Kafka常见生产问题详解
比如,在原有Topic下,可以调整Producer的分区策略,让Producer将后续的消息更多的发送到新增的Partition里,这样可以让各个Partition上的消息能够趋于平衡。思路是可行的,但是重试的次数,发送消息的数量等都是需要考虑的问题。PageCache缓存中的消息是断电即丢失的。因为如果业务逻辑异步进行,而消费者已经同步提交了Offset,那么如果业务逻辑执行过程中出现了异常,失败了,那么Broker端已经接收到了消费者的应答,后续就不会再重新推送消息,这样就造成了业务层面的消息丢失。
编程日记 2024/02/02 14:04:11