环境:
没有linux命令,没有initrd命令,没有init6命令由于删除了/boot/efi/EFI/centos/grub.cfg ,重启服务器后,无法进入原来正常的系统,进入了grub命令行界面
备注:对于centos7/8/openEuler:
如果是采用的UEFI方式引导的,那系统的GRUB的有效配置文件是 /boot/efi/EFI/centos/grub.cfg;
如果是采用的Legacy方式引导,那对应的GRUB的有效配置文件是/boot/grub2/grub.cfg。
解决办法:
采用系统镜像/U盘Centos,设置开机从镜像/U盘启动,如图进入启动界面


然后点击第二项,进入救援模式。 然后进入如下模式,选择1,继续进行回车,接下来,我们就会进入到一个shell模式中,需要切换根目录,进行系统修复:
1.bash-5.1# chroot /mnt/sysroot/ # 根据输入完1之后的提示进行chroot
2.cd /boot/efi/EFI/centos
grub2-mkconfig -o /boot/efi/EFI/centos/grub.cfg 或者grub2-mkconfig > /boot/efi/EFI/centos/grub.cfg
3.sync 切记一定要执行,否则重启不生效,再次在救援模式下查看grub.cfg可能会被修改为grub.cfg.new
4.exit + reboot
备注:如果是Legacy方式引导时:
1、chroot /mnt/sysroot/ 切换根目录
2、在/boot/grub2/目录下生成grub.cfg文件
grub2-mkconfig -o /boot/grub2/grub.cfg 或者grub2-mkconfig > /boot/grub2/grub.cfg
3、sync (切记一定要执行,否则重启不生效,再次在救援模式下查看grub.cfg可能会被修改为grub.cfg.new)
4、然后exit退出,再reboot重启。
扩展:
在 CentOS 中,进入救援模式后输入 sync 命令可以将内存中的数据同步到磁盘中。这是因为在正常关机时,操作系统会自动将内存中的数据写入到磁盘中,但在异常关机或重启时,可能会导致部分数据还未及时写入磁盘而发生数据丢失或损坏。
sync 命令的作用是告诉操作系统立即将内存中的数据写入到磁盘中,以强制完成数据同步。这样可以确保在接下来的操作中,已经写入到磁盘中的数据不会丢失或损坏,从而避免数据恢复或修复工作的复杂性和风险。
需要注意的是,sync 命令并不能修复已经损坏或丢失的数据,它只能保证已经写入到磁盘中的数据是完整和正确的。如果您遇到了数据损坏或丢失的问题,可能需要使用更专业的数据恢复工具或服务来解决。
相关文章
C语言中strstr函数的使用!
这里要进行分析,有一个重要的点就是,成勋会返回abc及其后面的字符,如上图所示p2代表abc,而abc在p1中能够找到,所以返回abc和p1中abc后面的所有字符,这是一个需要注意的地方。//判断p2字符串是不是在p1中,如果在就是子字符串,否则不是。if (ret == NULL) //函数返回值是保存在ret这个字符指针变量中的,为空说明不是子字符串。printf("子字符串不在\n");具体直接看下面的这段代码我相信你必明白。
编程日记 2024/02/28 09:12:59

ubuntu20.04安装实时内核补丁PREEMPT_RT
下载实时内核补丁,我下载patch-5.15.148-rt74.patch.sign和patch-5.15.148-rt74.patch.xz。通过以下指令看具体报错并输出日志到make.log:make -j1 deb-pkg 2>&1 | tee ~/make.log。比较幸运没遇到问题,重启进入后,启动页面没有变化,还是进入ubuntu,但是查看内核版本已经自动变到5.15.148。我下载linux-5.15.148.tar.xz和linux-5.15.148.tar.sign。
编程日记 2024/02/23 08:40:54
如何使用 img 文件在 VirtualBox 中创建虚拟机?
在虚拟化环境中,.img 格式的磁盘映像文件是常见的分发形式。如果您想在 VirtualBox 中使用这样的映像文件创建虚拟机,以下是详细的步骤和命令示例。
编程日记 2024/02/22 08:58:12

Linux 目录磁盘满了,怎么查找大文件
如果你不确定某个文件或目录的用途,最好先进行调查或咨询专业人士,而不是直接删除它们。,这是一个基于文本的磁盘使用分析器,非常适合于查找大文件。如果它没有预装,你可以通过你的包管理器安装它(例如,在Ubuntu上使用。会分析根目录的磁盘使用情况,并提供一个交互式界面来浏览最大的文件和目录。请注意,运行这些命令可能需要一些时间,因为它们会检查许多文件。)磁盘满了,你可以使用以下方法来查找占用空间最大的文件和目录。这个命令会搜索根目录下所有的文件,并显示它们的大小。为了找到最大的文件,你可以使用。
编程日记 2024/02/19 20:50:57
Linux CentOS系统安装SQL Server并结合内网穿透实现公网访问本地数据
简单几步实现在Linux centos环境下安装部署sql server数据库,并结合cpolar内网穿透工具,创建安全隧道将其映射到公网上,获取公网地址,实现在外异地远程连接家里/公司的sqlserver数据库,而无需公网IP,无需设置路由器,亦无需云服务器。
编程日记 2024/02/19 20:49:01

如何在 Debian 12 上安装 Microsoft SQL Server?
在安装 Microsoft SQL Server 之前,我们需要确保系统是最新的,并安装一些必要的软件和依赖项。以下是详细的步骤:这将更新软件包列表并升级已安装的软件包。这将安装 curl 用于下载文件,gnupg 用于导入 GPG 密钥,以及 apt-transport-https 用于通过 HTTPS 访问软件包。
编程日记 2024/02/18 22:53:30
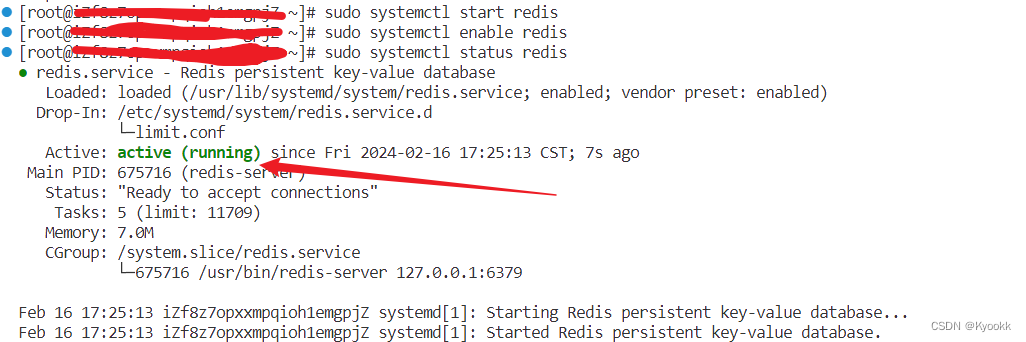
使用redis-insight连接到服务器上的redis数据库
我们现在虽然安装好了redis数据库,但是外界是连接不到的,我们需要打破这个限制!设置完之后,可以按以下图的命令查看,redis的密码是不是起作用了。的更改,并退出编辑器。在网上下载好redis-insight的客户端,打开。默认情况下,它可能被设置为只监听本地连接,如。这允许在没有进行身份验证的情况下接受外部连接。(3)为了增强安全性,强烈建议设置访问密码。三、使用redis-insight连接数据库。1.查找redis的配置文件。指令,并确保将其设置为。替换为你自己的强密码。
编程日记 2024/02/16 20:32:27
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务
编程日记 2024/02/13 19:58:42

服务器与电脑的区别?
服务器是指一种专门提供计算和存储资源、运行特定软件服务的物理或虚拟计算机。服务器主要用于接受和处理来自客户端(如个人电脑、手机等)的请求,并向客户端提供所需的服务或数据。服务器在网络环境中扮演着中心节点的角色,负责存储和管理数据、提供网络服务、处理计算任务等。
编程日记 2024/02/10 19:41:26

Linux 别名命令:如何创建和使用 Linux 别名
别名 my-update 等同于 sudo apt-get update && sudo apt-get upgrade alias my-update = 'sudo apt-get update && sudo apt-get upgrade'使用my-update命令快速更新和升级系统软件包。
编程日记 2024/02/09 09:30:41
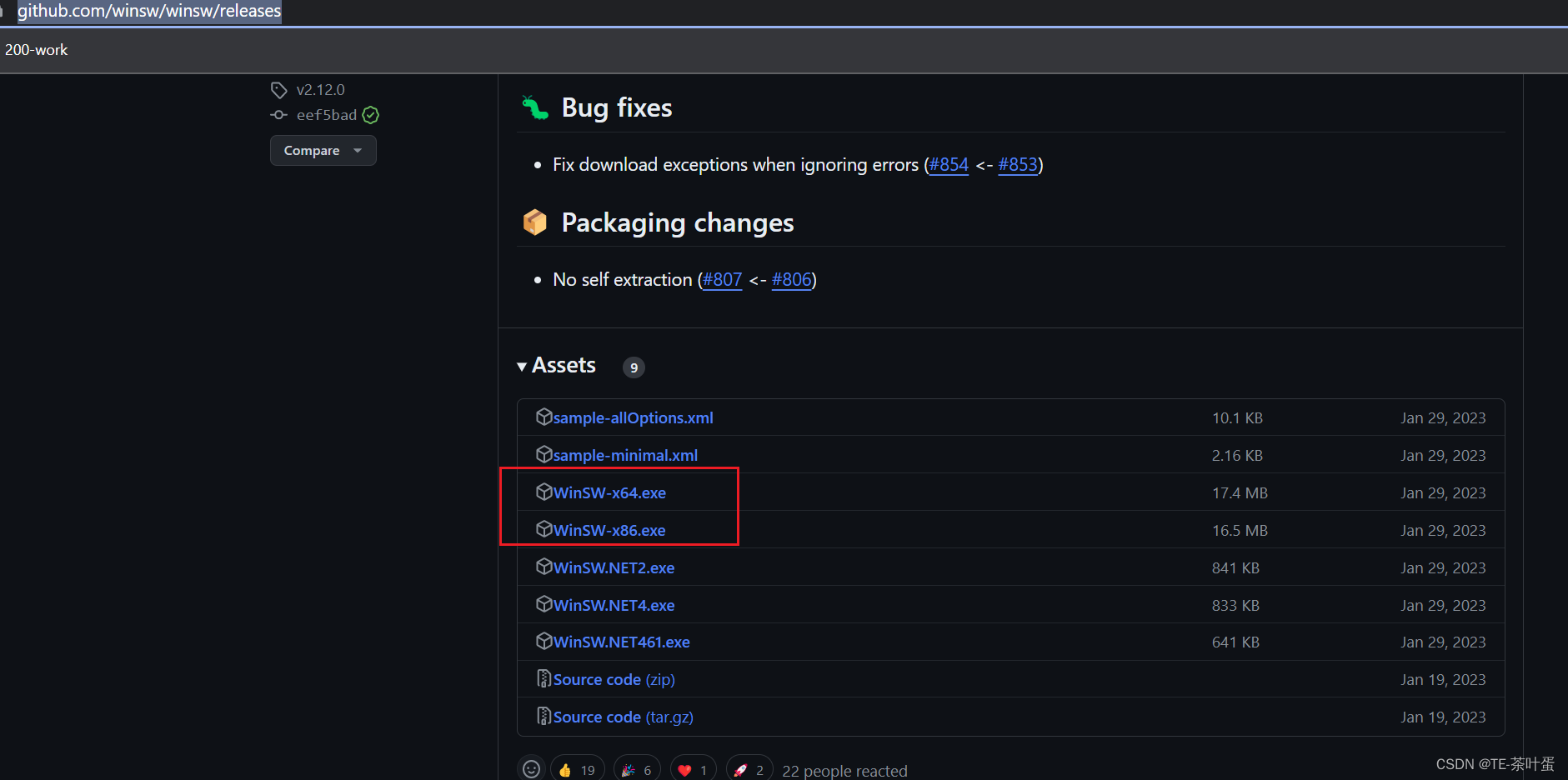
windows下ngnix自启动(借助工具winSw)
在windows下安装nginx后,不想每次都手动启动。本文记录下windows下ngnix自启动(借助工具winSw)的操作流程提示:以下是本篇文章正文内容,下面案例可供参考本文记录下windows下ngnix自启动(借助工具winSw)的操作流程。
编程日记 2024/02/08 18:11:23

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案
mysql8登录第一次遇到MYSQL_ROOT_PASSWORD时会自动把该密码尽兴登录,生成一个秘钥放在mysql的数据文件里面,命令里带的MYSQL_ROOT_PASSWORD密码是个参数,除了第一次运行mysql带上会设置密码生成秘钥,其他次启动而不是设置mysql的密码,而是作为参数去验证这个最初的秘钥是否核对正确,于是我进入挂载的data目录,发现我的猜想是对的。通过docker将服务部署完后,navicat连接报错,密码错误,于是我尝试进入mysql容器登录 发现也报错。
编程日记 2024/02/08 18:08:55

Linux 磁盘空间占用率100%的排查
max-size 最大数值 , max-file 最大日志数,但一两个容器还好,但是如果有很多容器需要管理,这样就很不方便了,最好还是可以统一管理(全局修改)结果显示多条如下数据,这里最关键的指标就是使用百分比,这个值较高一般需要处理,或者明确知道自己项目或工作目录是哪个,就只要找对应的位置去处理即可。/var/lib/docker/overlay2 【文件系统】基于容器文件系统保存的数据会写到本机的此目录下,进行限制,以减少日志文件对存储空间的占用,以下配置分别为日志文件最大容量、最大日志文件数。
编程日记 2024/02/04 09:53:28

chatchat部署在ubuntu上的坑
2. 安装后把代理关闭,全局的代理改为手动,重新打开一个新的控制台。1. 安装前要开代理,注意要下载很多东西,流量大。
编程日记 2024/02/03 10:52:45

解决Linux环境下gdal报错:ERROR 4: `/xxx.hdf‘ not recognized as a supported file format.
题外话:我发现linux系统和Windows系统下面,库的版本是有差异的。比如我的本机Windows上装的是gdal3.2.3和numpy1.19.1,linux服务器上装的却是gdal3.0.2和numpy1.21.5。这个是很常见的回复,网上许多回答都说低版本的 gdal 不支持 hdf5,让你重装高版本的gdal。我之前用pip安装了whl,暴力装上了,但用的时候就会有问题。安装了不冲突的gdal之后,就成功打开文件啦~一开始我是抱着试试的心态,用conda,不用pip,重新安装了一下我的gdal。
编程日记 2024/01/30 14:36:06

内网穿透、远程桌面、VPN的理解
针对不同的场景可能咱们可以选择不同的方法,局域网远程桌面这种其实也不是很常用,为什么呢,因为如果就在局域网的话,那么你本人直接过去操作就可以了,不需要远程桌面,而且远程桌面还需要给你的登录账户和密码,这些都是隐私的东西,一般最好不对外泄露。VPN其实是比较适合在家远程办公的场景的,电脑带回家,然后连接VPN,就可以实现办公了,但是也有一些问题,就是公司必须要一个固定的IP,还必须要配一个VPN服务器,固定IP这个是越来越少了,很多宽带都不是固定外网IP了。
编程日记 2024/01/29 23:50:23
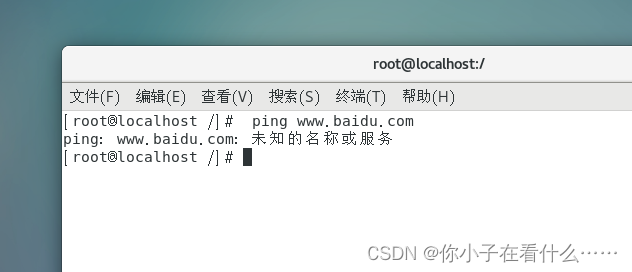
VMware中CentOS 7解决网络问题
在 VMware 中使用 CentOS 7 中使用 ping www.baidu.com 出现未知的名称和服务的问题
编程日记 2024/01/29 17:54:59
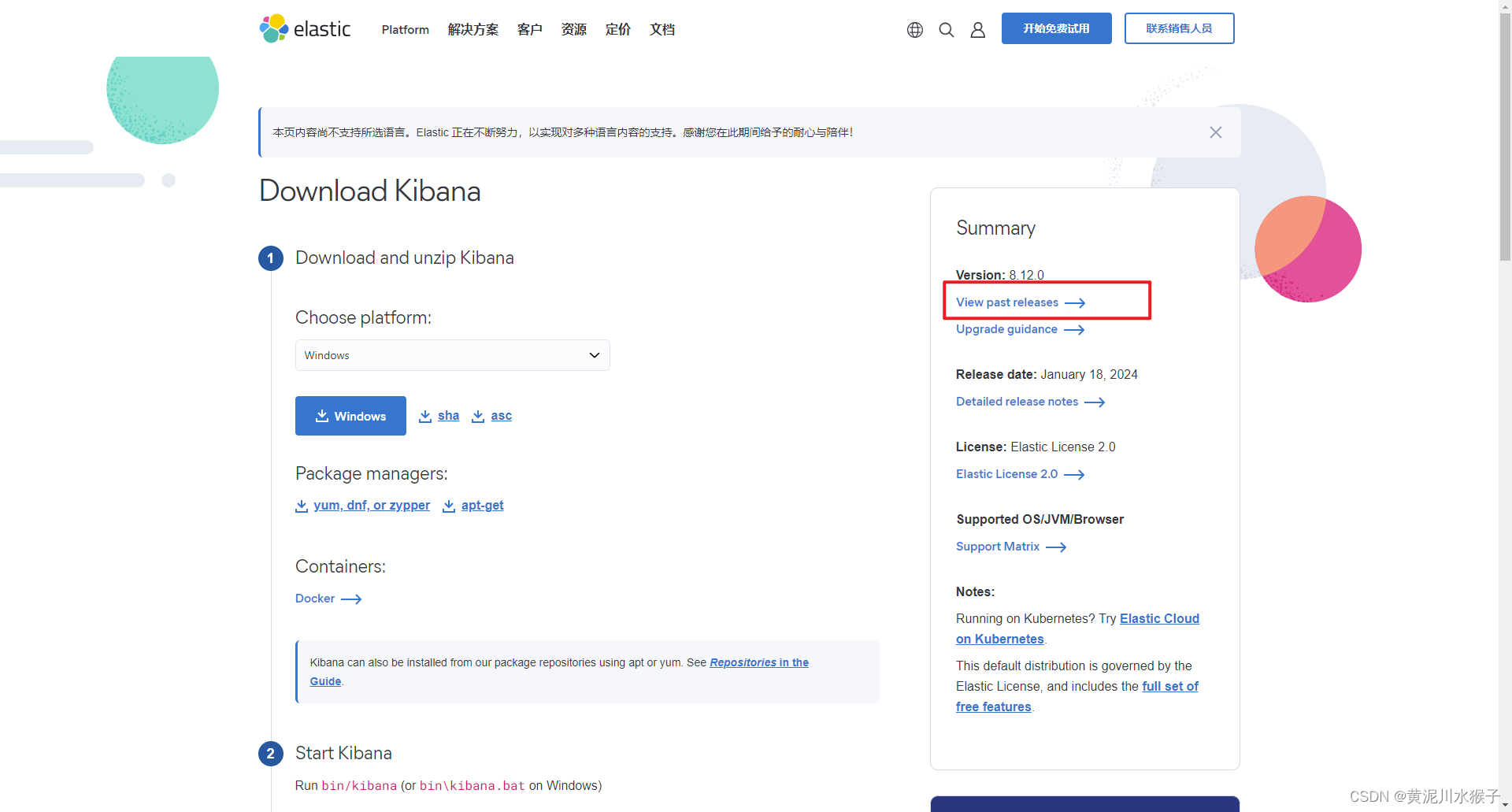
阿里云服务器上安装ElasticSearch基于CentOS 7.8,并且在本地Windows上可以通过Kibana访问
在单节点环境中运行,因此它不需要进行集群发现(discovery)。在单节点环境中,不涉及到与其他节点通信的情况,因此关闭集群发现可以简化配置。创建一个新的 .repo 文件,添加 Elasticsearch 仓库信息。解压后,在config文件中找到kibana.yml ,找到 elasticsearch.hosts 配置项。首先,配置阿里云服务器。进入编辑模式:按下 i 键,此时光标左下角会显示。: 设置 HTTP 访问的端口,默认是 9200。保存并退出:按下 Esc 键,然后输入。
编程日记 2024/01/26 11:10:01

Linux 服务器 CPU 详细信息查看、物理 CPU 以及逻辑 CPU
当两个线程都同时需要某一个资源时,其中一个要暂时停止,并让出资源,直到这些资源闲置后才能继续,因此超线程的性能并不等于两颗CPU的性能。超线程技术就是利用特殊的硬件指令,把两个逻辑内核模拟成两个物理芯片,让单个处理器都能使用线程级并行计算,进而兼容多线程操作系统和软件,查看CPU详细得知,服务器共有16个核心,物理CPU个数为 4,证明单个物理CPU上集成了4个核心处理器。日常我们所说的CPU核数指的是物理CPU上存在几个核心处理器或者核心处理单元总和(排除超线程技术)Linux内核支持关闭超线程技术。
编程日记 2024/01/23 11:01:35
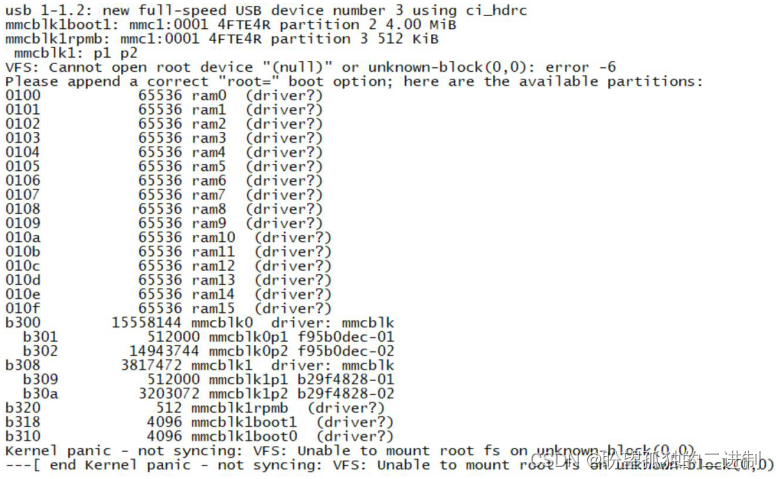
浅谈ARM嵌入式中的根文件系统rootfs
这里设置 console 为 ttymxc0,因为 linux启动以后 I.MX6ULL 的串口 1 在 linux 下的设备文件就是/dev/ttymxc0,在 Linux 下,一切皆文件。/dev/mmcblk1、/dev/mmcblk0p1、/dev/mmcblk0p2、/dev/mmcblk1p1 和/dev/mmcblk1p2 这样的文件,其中/dev/mmcblkx(x=0~n)表示 mmc 设备,而/dev/mmcblkxpy(x=0。有这个“根”,其他的文件系统或者软件就别想工作。
编程日记 2024/01/22 16:07:14
linux配置DNS主从服务器
主服务器:OpenElur Linux IP地址为192.168.188.129。从服务器:RedHat Linux IP地址为192.168.188.128。2.配置主服务器的`解析配置文件。3.进行从服务器的基础配置。1.进行主服务器的基础配置。
编程日记 2024/01/22 15:19:35
Centos系统上安装PostgreSQL和常用PostgreSQL功能
PostgreSQL安装成功之后,会默认创建一个名为postgres的Linux用户,初始化数据库后,会有名为postgres的数据库,来存储数据库的基础信息,例如用户信息等等,相当于MySQL中默认的名为mysql数据库。权限代码:SELECT、INSERT、UPDATE、DELETE、TRUNCATE、REFERENCES、TRIGGER、CREATE、CONNECT、TEMPORARY、EXECUTE、USAGE。为了方便我们使用postgres账号进行管理,我们可以修改该账号的密码。
编程日记 2024/01/21 15:11:21


Docker之nacos的安装和使用
在上一期的博客分享中我们分享了有关Nginx的安装和使用,当然我们知道上一期的博客分享的是使用Nginx实现负载均衡。本期的博客文章基于上一期的Docker之Nginx安装的基础上,本期的。
编程日记 2024/01/19 10:43:54
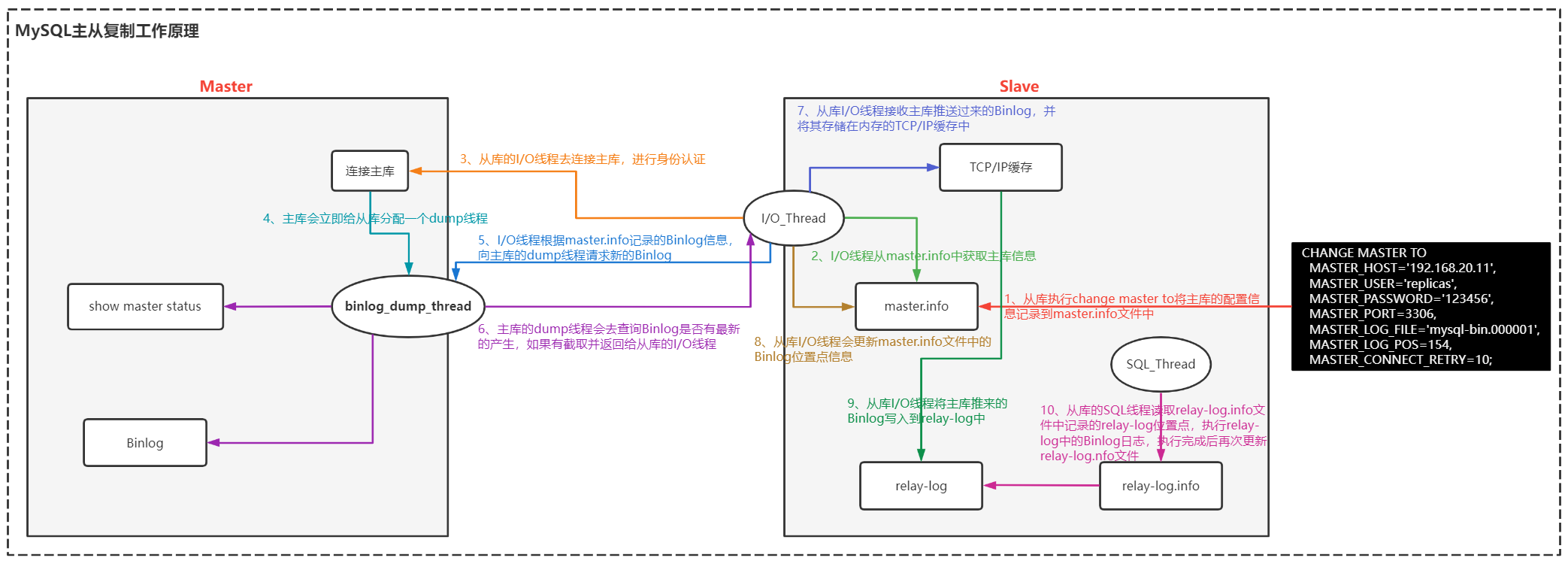
MySQL数据库主从复制集群原理概念以及搭建流程
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。主库出现问题,可以快速切换到从库提供服务。实现读写分离,降低主库的访问压力。可以在从库中执行备份,以避免备份期间影响主库服务。
编程日记 2024/01/18 16:22:43
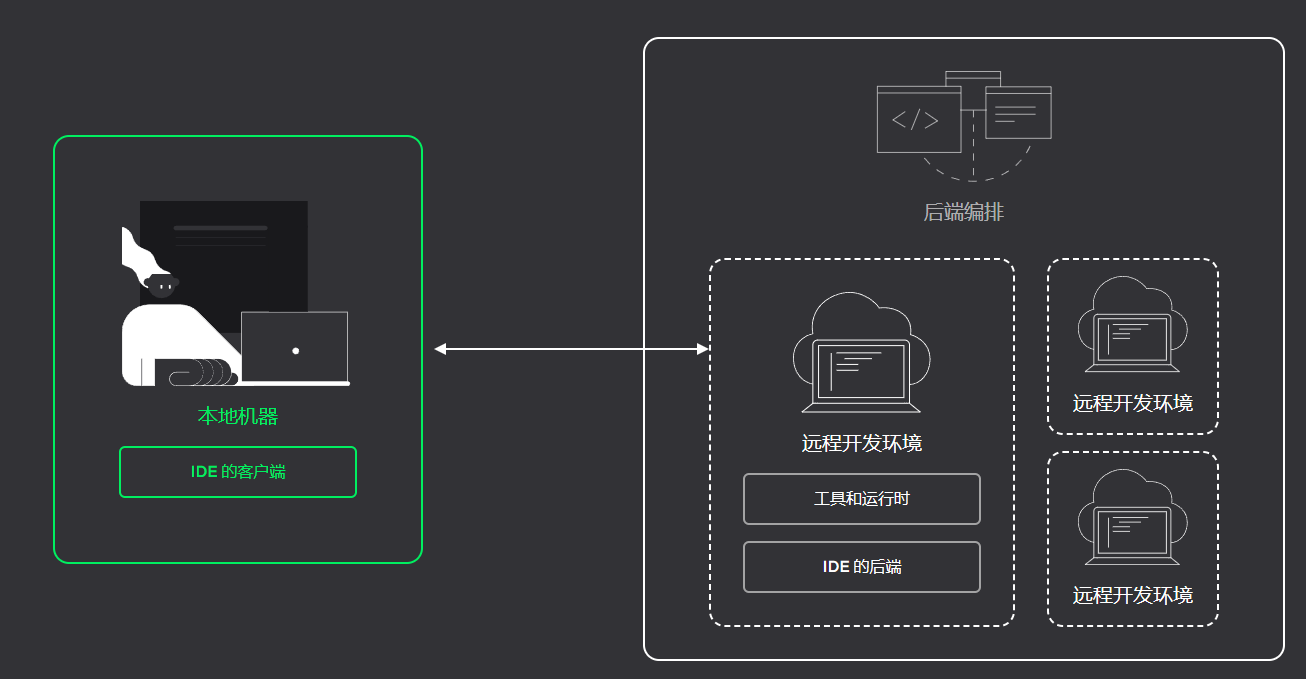
如何配置Pycharm服务器并结合内网穿透工具实现远程开发
本文主要介绍如何使用Pycharm进行远程开发,并实现在家远程与公司服务器资源同步。新版本Jetbrains系列开发IDE(IntelliJ IDEA,PyCharm,GoLand)等都支持远程使用服务器编译,并且可以通过SFTP同步本地与服务器项目代码。这样做的好处是我们只要连接上服务器就能开始干活儿,不用折腾环境,不占用个人笔记本资源,最重要的是不用忍受笔记本的烂风扇噪音。
编程日记 2024/01/17 01:28:38

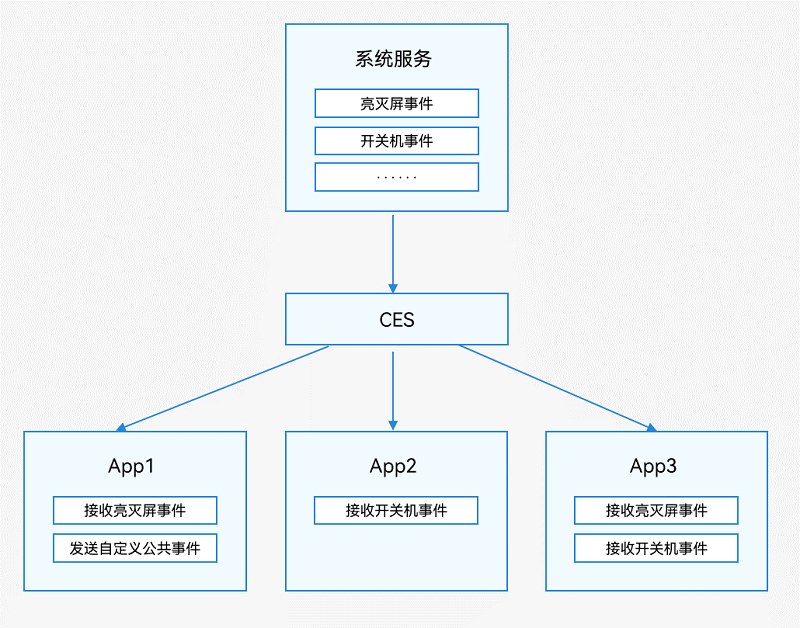
HarmonyOS4.0系统性深入开发19进程模型概述
HarmonyOS通过CES(Common Event Service,公共事件服务)为应用程序提供订阅、发布、退订公共事件的能力。公共事件从系统角度可分为:系统公共事件和自定义公共事件。系统公共事件:CES内部定义的公共事件,只有系统应用和系统服务才能发布,例如HAP安装,更新,卸载等公共事件。目前支持的系统公共事件详见系统公共事件列表。自定义公共事件:应用自定义一些公共事件用来实现跨进程的事件通信能力。公共事件按发送方式可分为:无序公共事件、有序公共事件和粘性公共事件。
编程日记 2024/01/15 09:47:24

如何使用人工智能优化 DevOps?
DevOps 和人工智能密不可分,影响着各种业务。DevOps 可以加快产品开发速度并简化现有部署的维护,而 AI 则可以改变整个系统的功能。DevOps团队可以依靠人工智能和机器学习来进行数据集成、测试、评估和发布系统。更重要的是,人工智能和机器学习可以以高效、快速、安全的方式改进 DevOps 驱动的流程。从开发人员实用性和业务支持的角度来看, 评估AI和ML在 DevOps 中的重要性对于企业来说是有益的。
编程日记 2024/01/12 22:25:05