前言
当前的应用服务很多都有着高并发的业务场景,对于高并发的解决方案一般会用到缓存来降低数据库压力,并且还能够提高系统性能减少请求耗时,比如我们常用的redis缓存。当然,一般业务在更新要刷新缓存,但是如果采用的方式方法不对是会造成数据不一致的情况,让用户拿到错误的缓存数据。今天,就来讨论一下缓存与数据不一致的原因并提供解决方案。

技术积累
查询缓存业务流程
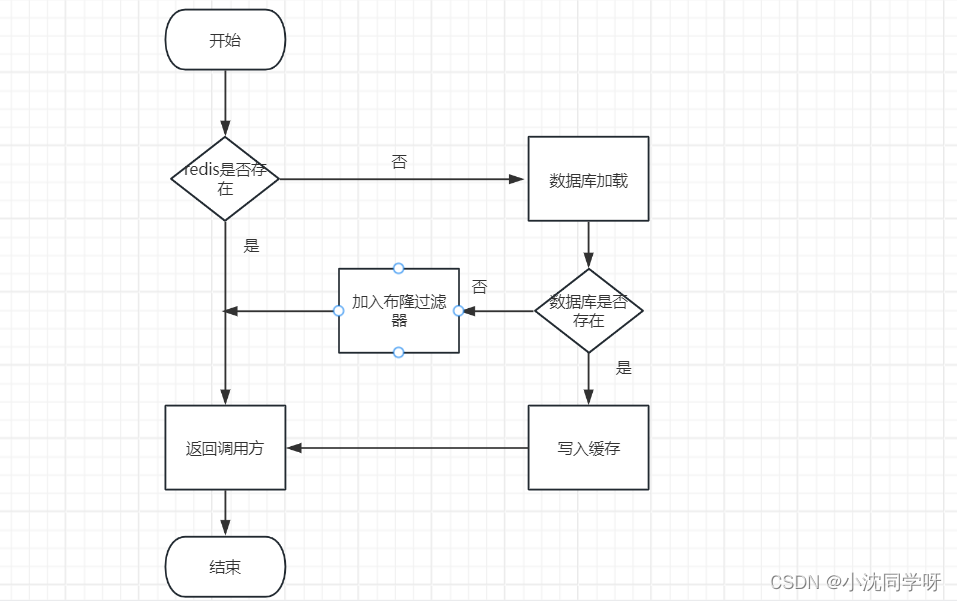
查询步骤:
1、请求打到服务端首先到redis查看是否存在缓存
2、存在缓存直接返回前端,不存在直接查询数据库
3、查询数据库存在写入缓存并返回,不存在则写入布隆过滤器返回
注意:在写入缓存的步骤需要加上分布式锁并设置未获取到锁立即失败的策略,以防止高并发下多个线程争抢资源的情况。
为什么数据库没有会写入布隆过滤器?
主要用来解决redis缓存击穿。
布隆过滤器的主要原理是使用一组哈希函数,将元素映射成一组位数组中的索引位置。当要检查一个元素是否在集合中时,将该元素进行哈希处理,然后查看哈希值对应的位数组的值是否为1。如果哈希值对应的位数组的值都为1,那么这个元素可能在集合中,否则这个元素肯定不在集合中。
更新缓存业务流程
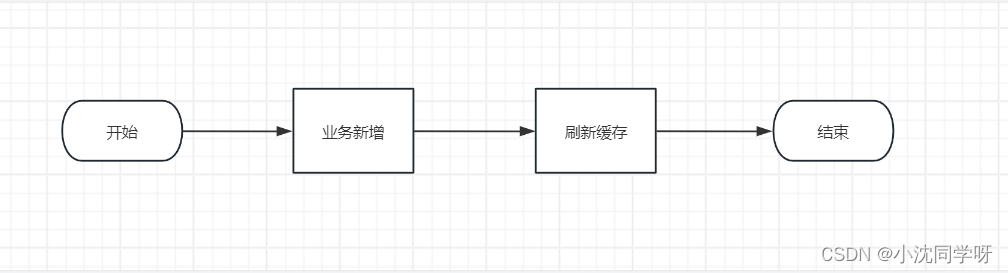
以上是常规的新增缓存的业务流程,其步骤是:
1、业务更新数据
2、刷新缓存
更新缓存问题
以上更新缓存有什么问题?
如果并发量不高的情况下,可能用户并不会发现缓存与数据库不一致的情况。
但是在高并发的情况下,A线程新增数据后还没有来得及刷新缓存,线程B又修改了数据库数据并刷新了缓存,此时线程A由于运行太慢才拿着A的数据去刷新缓存,这样就导致redis数据是A线程的数据与数据库B线程数据不一致。
当然,有的同学可能会采用先删除缓存后更新业务数据库的策略,比如线程A刚刚删除了缓存还没有更新数据库,线程B访问了就立即会讲数据库数据加入缓存并返回,然后A线程继续更新业务数据库。导致redis数据是B线程数据与数据库A线程数据不一致。
所以,如果你的业务系统对缓存敏感就必须要解决缓存不一致的问题。
解决方案
1、redis延迟双删
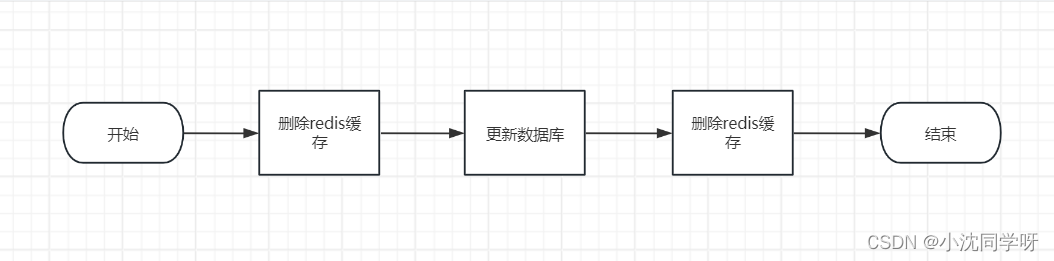
1.1 具体的操作步骤:
先删除缓存;
再写数据库;
休眠300毫秒 休眠时间根据自身业务情况进行增减;
再次删除缓存。
1.2 设置缓存过期时间
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。所有的写操作以数据库为准,只要到达缓存过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。
方案的缺点
结合双删策略+缓存超时设置,这样最差的情况就是在超时时间内数据存在不一致,而且又增加了写请求的耗时。
2、异步更新缓存(基于订阅binlog的同步机制)
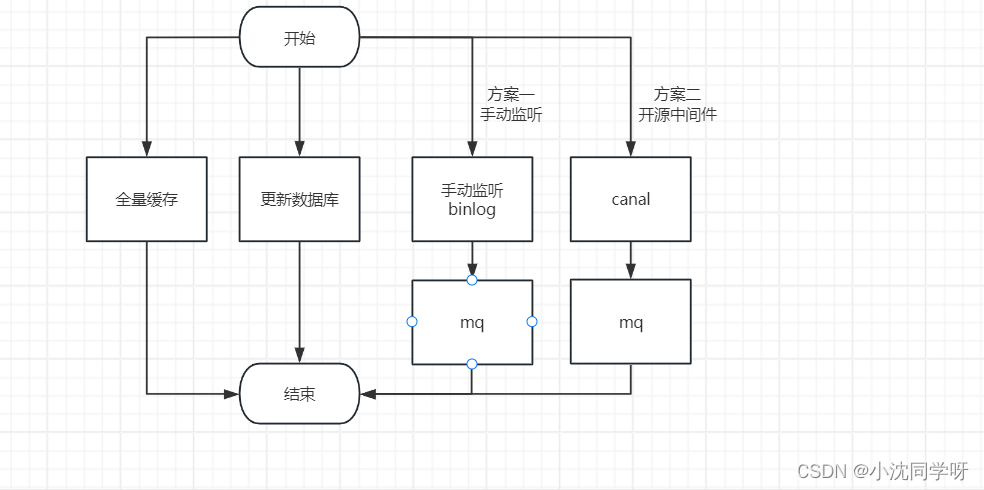
2.1 方案一手动监听mysql binlog+消息队列mq
项目启动立即将缓存全量加入redis;
我们不再关心业务数据跟新,直接加上事务写入mysql数据库即可,此时mysql会产生binlog日志;
mq生产者监听mysql binlog,发现binlog变动将具体的日志发送到mq相关队列
mq消费者监听到有消息立即消费,并解析出具体的数据调用redis更新
2.2 方案二开源中间件canal
其实canal的思路与方案一差不多,不同的是canal将自己伪装成一个mysql slave从节点。
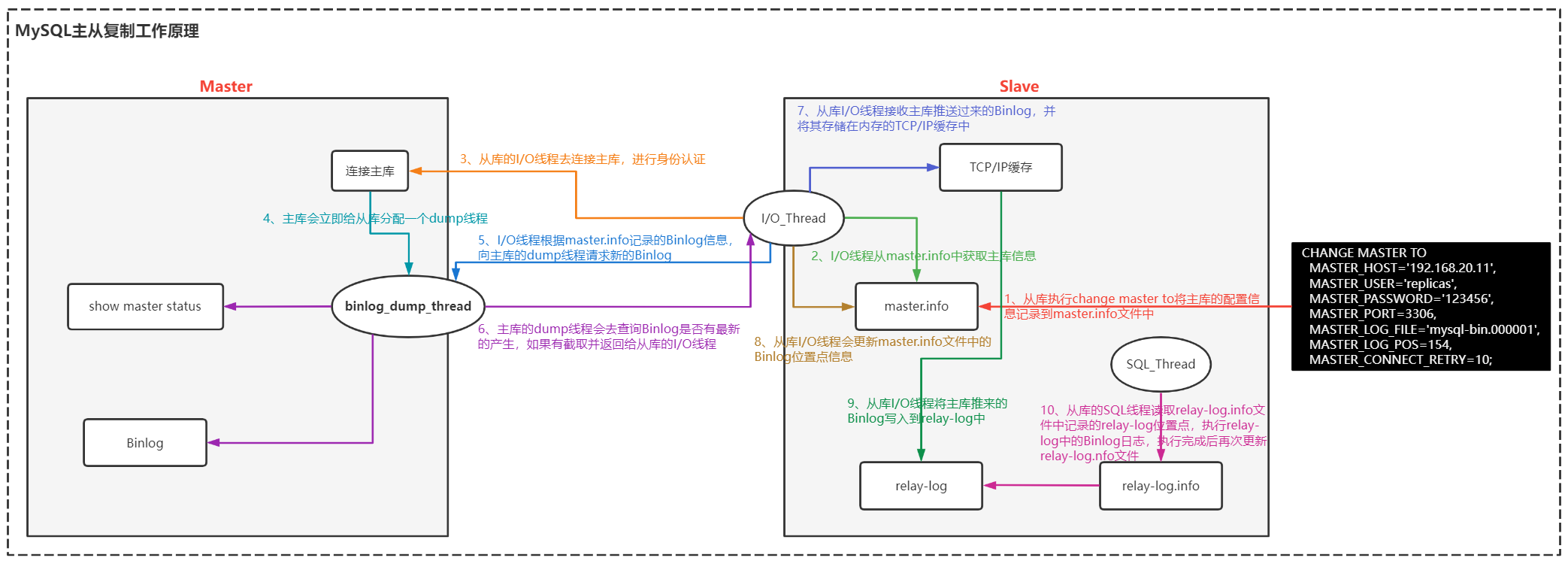
大家应该都知道mysql主从同步的原理:
当mysql slave连接到master节点时,master会开一个binlog dump线程来监听binlog变化,slave也会开启一个IO线程。当有数据变更的时候,binlog dump线程就会将日志名字和同步位置等信息发送给slave IO线程,slave IO线程会根据接收到的同步信息去master拉取binlog并保存到自己的relay log中继日志中。这个时候slave节点的sql 线程会不断地从relay log中继日志将数据写入数据库。
具体步骤:
canal的服务端启动伪装为mysql slave注册到mysql 集群
canal服务端拿到binlog日志后会进行解析和封装为带有DML语句的对象数据
canal服务端创建线程将封装好的对象数据发送到消息队列mq
canal客户端会监听具体的消息队列,获取到具体的DML语句进行解析
canal客户端创建线程对redis进行操作
写在最后
在高并发的业务场景下redis与mysql数据库非常容易产生数据不一致的情况,我们可以采用redis缓存延迟双删除策略达到数据的最终一致性,也可以采用一部缓存更新自定义监听mysql binblog和采用canal开源中间件实现缓存的实时一致性方案。总的来说,都是比较简单的,而且都能够达到良好的效果。
相关文章
Redis高并发分布锁实战

Redis是否为单线程?

Git如何清除缓存?这四个命令得会!

MySQL中的高级查询

ubuntu20.04安装实时内核补丁PREEMPT_RT
日常遇到Maven出现依赖版本/缓存问题通用思路。
mysql中文首字母排序查询
使用redis-insight连接到服务器上的redis数据库

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案
数据湖Paimon入门指南

虚拟机Windows Server 2016 安装 MySQL8
基于SQL数据库的大模型RAG实现
MySQL运行在docker容器中会损失多少性能

Mysql大数据量分页优化
oracle data block , extent 和segment区别
MySQL数据库主从复制集群原理概念以及搭建流程


【.NET Core】Lazy<T> 实现延迟加载详解
【MySQL】MySQL表的约束-空属性/默认值/列属性/zerofill/主键/自增长/唯一键/外键
CentOS本地部署SQL Server数据库无公网ip环境实现远程访问

[redis] redis的安装,配置与简单操作

Redis的IO多路复用原理解析
在 Docker 中配置 MySQL 数据库并初始化 Project 项目
Redis内存使用率高,内存不足问题排查和解决

深入理解Mysql事务隔离级别与锁机制

MySQL:为什么明明创建了索引还是走了全表扫描