云原生架构原则
云原生架构本身作为一种架构,也有若干架构原则作为应用架构的核心架构控制面,通过遵从这些架构原则可以让技术主管和架构师在做技术选择时不会出现大的偏差。
服务化原则
当代码规模超出小团队的合作范围时,就有必要进行服务化拆分了,包括拆分为微服务架构、小服务( Mini Service)架构,通过服务化架构把不同生命周期的模块分离出来,分别进行业务迭代,避免迭代频繁模块被慢速模块拖慢,从而加快整体的进度和稳定性。同时服务化架构以面向接口编程,服务内部的功能高度内聚,模块间通过公共功能模块的提取增加软件的复用程度。
分布式环境下的限流降级、熔断隔仓、灰度、反压、零信任安全等,本质上都是基于服务流量(而非网络流量)的控制策略,所以云原生架构强调使用服务化的目的还在于从架构层面抽象化业务模块之间的关系,标准化服务流量的传输,从而帮助业务模块进行基于服务流量的策略控制和治理,不管这些服务是基于什么语言开发的。
弹性原则
大部分系统部署上线需要根据业务量的估算,准备一定规模的机器,从提出采购申请,到供应商洽谈、机器部署上电、软件部署、性能压测,往往需要好几个月甚至一年的周期;而这期间如果业务发生变化了,重新调整也非常困难。弹性则是指系统的部署规模可以随着业务量的变化自动伸缩,无须根据事先的容量规划准备固定的硬件和软件资源。好的弹性能力不仅缩短了从采购到上线的时间,让企业不用操心额外软硬件资源的成本支出(闲置成本),降低了企业的IT成本,更关键的是当业务规模面临海量突发性扩张的时候,不再因为平时软硬件资源储备不足而“说不”,保障了企业收益。
可观测原则
今天大部分企业的软件规模都在不断增长,原来单机可以对应用做完所有调试,但在分布式环境下需要对多个主机上的信息做关联,才可能回答清楚服务为什么宕机、哪些服务违反了其定义的SLO、目前的故障影响哪些用户、最近这次变更对哪些服务指标带来了影响等等,这些都要求系统具备更强的可观测能力。可观测性与监控、业务探活、APM等系统提供的能力不同,前者是在云这样的分布式系统中,主动通过日志、链路跟踪和度量等手段,让一次APP点击背后的多次服务调用的耗时、返回值和参数都清晰可见,甚至可以下钻到每次三方软件调用、SQL请求、节点拓扑、网络响应等,这样的能力可以使运维、开发和业务人员实时掌握软件运行情况,并结合多个维度的数据指标,获得前所未有的关联分析能力,不断对业务健康度和用户体验进行数字化衡量和持续优化。
韧性原则
当业务上线后,最不能接受的就是业务不可用,让用户无法正常使用软件,影响体验和收入。韧性代表了当软件所依赖的软硬件组件出现各种异常时,软件表现出来的抵御能力,这些异常通常包括硬件故障、硬件资源瓶颈(如CPU/网卡带宽耗尽)、业务流量超出软件设计能力、影响机房工作的故障和灾难、软件 bug、黑客攻击等对业务不可用带来致命影响的因素。
韧性从多个维度诠释了软件持续提供业务服务的能力,核心目标是提升软件的MTBF ( Mean TimeBetween Failure,平均无故障时间)。从架构设计上,韧性包括服务异步化能力、重试/限流/降级/熔断Ⅰ反压、主从模式、集群模式、AZ内的高可用、单元化、跨region容灾、异地多活容灾等。
所有过程自动化原则
技术往往是把“双刃剑”,容器、微服务、DevOps、大量第三方组件的使用,在降低分布式复杂性和提升迭代速度的同时,因为整体增大了软件技术栈的复杂度和组件规模,所以不可避免地带来了软件交付的复杂性,如果这里控制不当,应用就无法体会到云原生技术的优势。通过 laC ( lnfrastructure asCode ) . GitOps、OAM (Open Application Model ) . Kubernetes operator和大量自动化交付工具在CIICD流水线中的实践,一方面标准化企业内部的软件交付过程,另一方面在标准化的基础上进行自动化,通过配置数据自描述和面向终态的交付过程,让自动化工具理解交付目标和环境差异,实现整个软件交付和运维的自动化。
零信任原则
零信任安全针对传统边界安全架构思想进行了重新评估和审视,并对安全架构思路给出了新建议。其核心思想是,默认情况下不应该信任网络内部和外部的任何人/设备/系统,需要基于认证和授权重构访问控制的信任基础,诸如IP地址、主机、地理位置、所处网络等均不能作为可信的凭证。零信任对访问控制进行了范式上的颠覆,引导安全体系架构从“网络中心化”走向“身份中心化”,其本质诉求是以身份为中心进行访问控制。
零信任第一个核心问题就是ldentity,赋予不同的Entity 不同的 Identity,解决是谁在什么环境下访问某个具体的资源的问题。在研发、测试和运维微服务场景下,ldentity 及其相关策略不仅是安全的基础,更是众多(资源,服务,环境)隔离机制的基础;在员工访问企业内部应用的场景下,ldentity 及其相关策略提供了灵活的机制来提供随时随地的接入服务。
架构持续演进原则
今天技术和业务的演进速度非常快,很少有一开始就清晰定义了架构并在整个软件生命周期里面都适用,相反往往还需要对架构进行一定范围内的重构,因此云原生架构本身也应该和必须是一个具备持续演进能力的架构,而不是一个封闭式架构。除了增量迭代、目标选取等因素外,还需要考虑组织(例如架构控制委员会)层面的架构治理和风险控制,特别是在业务高速迭代情况下的架构、业务、实现平衡
关系。云原生架构对于新建应用而言的架构控制策略相对容易选择(通常是选择弹性、敏捷、成本的维度),但对于存量应用向云原生架构迁移,则需要从架构上考虑遗留应用的迁出成本/风险和到云上的迁入成本/风险,以及技术上通过微服务Ⅰ应用网关、应用集成、适配器、服务网格、数据迁移、在线灰度等应用和流量进行细颗粒度控制。
图书推荐
关键点
1.架构设计新模式:让架构设计更高效、更快捷、更完美。
2.全流程解析:涵盖架构设计的不同应用场景,介绍从编写各种文档,到应用图形图表与UML建模、设计模式、数据库设计,再到编写代码、开发软件架构等关键环节。
3.实战检验:ChatGPT结合多种架构设计工具及案例实操讲解,理解更加透彻。
4.100%提高架构设计效率:揭秘ChatGPT与架构设计高效融合的核心方法论和实践经验。
5.超值资源:赠送教学视频及配套工具,供读者下载学习。
内容简介
本书是一本旨在帮助架构师在人工智能时代展翅高飞的实用指南。全书以ChatGPT为核心工具,揭示了人工智能技术对架构师的角色和职责进行颠覆和重塑的关键点。本书通过共计 13 章的系统内容,深入探讨AI技术在架构
设计中的应用,以及AI对传统架构师工作方式的影响。通过学习,读者将了解如何利用ChatGPT这一强大的智能辅助工具,提升架构师的工作效率和创造力。
本书的读者主要是架构师及相关从业人员。无论你是初入职场的新手架构师还是经验丰富的专业人士,本书都将成为你的指南,帮助你在人工智能时代展现卓越的架构设计能力。通过本书的指导,你将学习如何运用ChatGPT等工具和技术,以创新的方式构建高效、可靠、可扩展的软件架构。
同时,本书也适用于对架构设计感兴趣的其他技术类从业人员,如软件工程师、系统分析师、技术顾问等。通过学习本书的内容,你可以深入了解人工智能对架构设计的影响和带来的挑战,拓展自己的技术视野,提升对软件系统整体架构的理解和把握能力。
作者简介
关东升,一个在IT领域摸爬滚打20多年的老程序员、知名培训专家、畅销书作家,精通多种信息技术。曾参与设计和开发北京市公交一卡通系统、国家农产品追溯系统、金融系统微博等移动客户端项目,并在App Store发布多款游戏和应用软件。长期为中国移动、中国联通、中国南方航空、中国工商银行和天津港务局等企事业单位提供培训服务。先后出版了50多部IT图书,广受读者欢迎。

相关文章

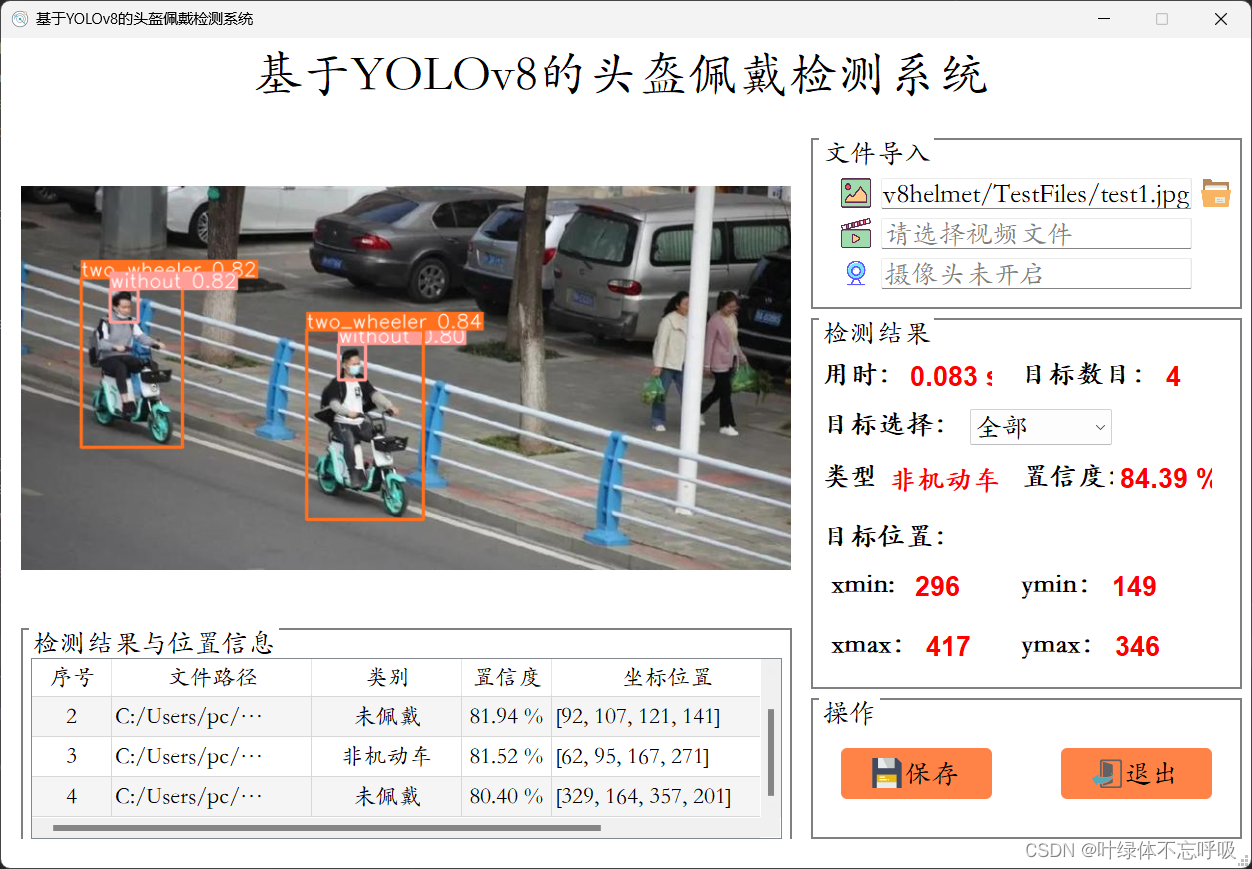
基于YOLOv8深度学习+Pyqt5的电动车头盔佩戴检测系统

chatgpt的大致技术原理

云计算与边缘计算:有什么区别?

ChatGPT高效提问—prompt基础

二维平面阵列波束赋形原理和Matlab仿真

人工智能与机器学习——开启智能时代的里程碑
【GPU】深入理解GPU硬件架构及运行机制
新能源汽车智慧充电桩管理方案:环境监测与充电安全多维感知
RAG中的3个高级检索技巧

大数据深度学习卷积神经网络CNN:CNN结构、训练与优化一文全解

从虚拟到现实:数字孪生驱动智慧城市可持续发展

如何使用人工智能优化 DevOps?
C# Onnx Chinese CLIP 通过一句话从图库中搜出来符合要求的图片

感知与认知的碰撞,大模型时代的智能文档处理范式
人工智能有哪些领域?

OpenCV:计算机视觉的强大工具库

使用LOTR合并检索提高RAG性能

【AI】人工智能复兴的推进器之神经网络

目标检测与测距算法在极端天气下的应用

深度解析 PyTorch Autograd:从原理到实践

AIGC实战——WGAN(Wasserstein GAN)

ChatGPT的常识


人工智能时代:AIGC的横空出世

【图像处理】使用各向异性滤波器和分割图像处理从MRI图像检测脑肿瘤(Matlab代码实现)

用AI攻克“智能文字识别创新赛题”,这场大学生竞赛掀起了什么风潮?
