文章目录
ZooKeeper相关文章参考:
ZooKeeper下载、安装、配置和使用
ZooKeeper配置文件zoo.cfg参数详解
启动server服务以及cli客户端
在cli客户端窗口中操作以下命令
1. help帮助命令
输入help可呼出所有相关命令
可根据需要找到指定的命令,然后输入找到的命令,就可继续往下查看对应命令的使用
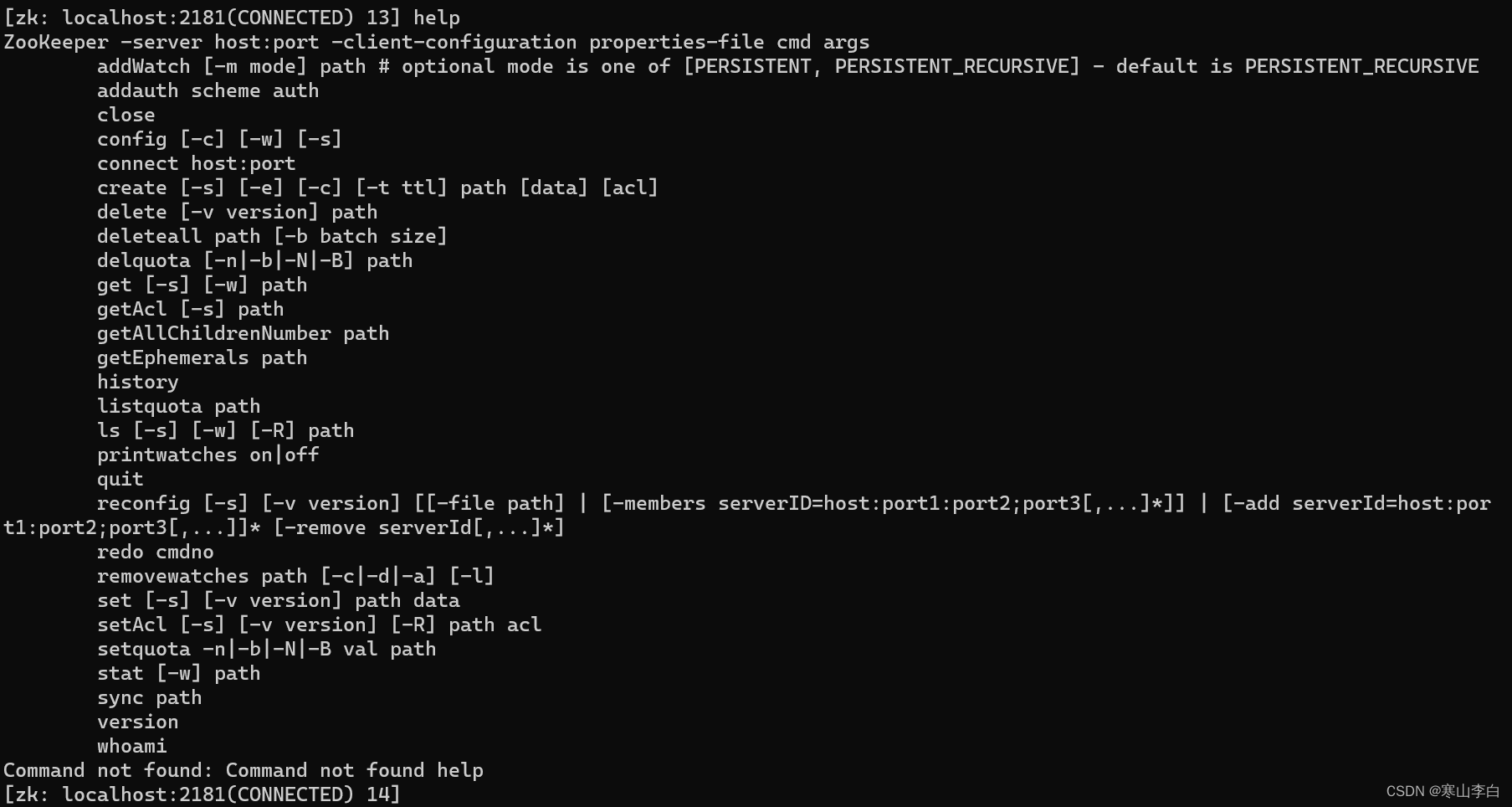
如ls命令来说,继续输入ls则会看到ls命令的详细用法

2. ls查看节点信息
语法:
ls [-s] [-w] [-R] path
-s表示查看详细信息,可省略
-w表示只看节点名称,可省略
-R表示查看根路径的所有节点及子节点,可省略
path表示节点路径,可以是根节点/,也可以是子节点路径如/a,或者/a/b/c
2.1 查看根节点信息
ls /

2.2 查看根节点的详细信息
ls -s /
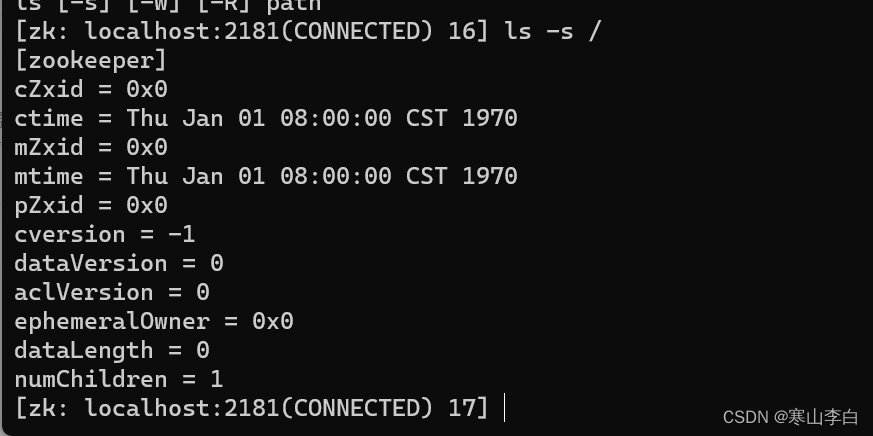
参数详细描述如下:
[zookeeper]
表示子节点名称数组如果多个则在中括号中以逗号隔开
接下来是节点的状态信息,也称为stat结构体
cZxid = 0x0
表示创建znode的事务的zxid(ZooKeeper Transaction ID)
事务ID是ZooKeeper每次更新操作/事务操作分配一个全局唯一的id,表示zxid,值越小表示越先执行
0x0表示十六进制数0
ctime = Thu Jan 01 08:00:00 CST 1970
表示创建时间
mZxid = 0x0
表示最后一次更新的zxid
mtime = Thu Jan 01 08:00:00 CST 1970
表示最后一次更新的时间
pZxid = 0x0
表示最后更新的子节点的zxid
cversion = -1
表示子节点的变化号,即子节点被修改的次数,-1表示未被修改过
dataVersion = 0
表示当前节点的变化号,0表示未被修改过
aclVersion = 0
表示访问控制列表的变化号,access control list
ephemeralOwner = 0x0
表示如果临时节点,表示当前节点的拥有者的sessionId
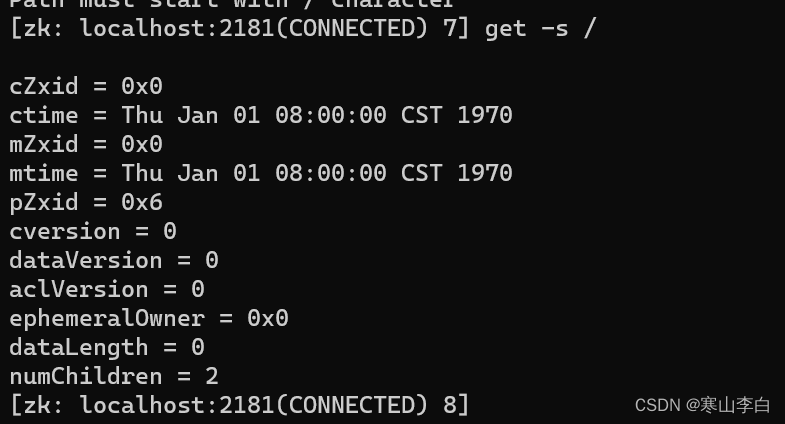
dataLength = 0
表示数据长度
numChildren = 1
表示子节点的数量
2.3 查看根节点的名称
ls -w /

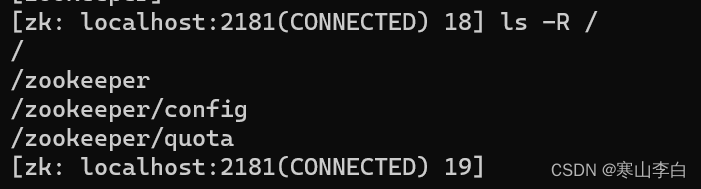
2.4 查看根节点的所有节点及子节点
ls -R /
3. get获取节点信息
语法:
get [-s] [-w] path
如获取根节点信息
get -s /
4. create创建节点
语法:
create 节点名称 节点内容
创建节点,如果节点内容含有空格则需要将其用双引号括起来
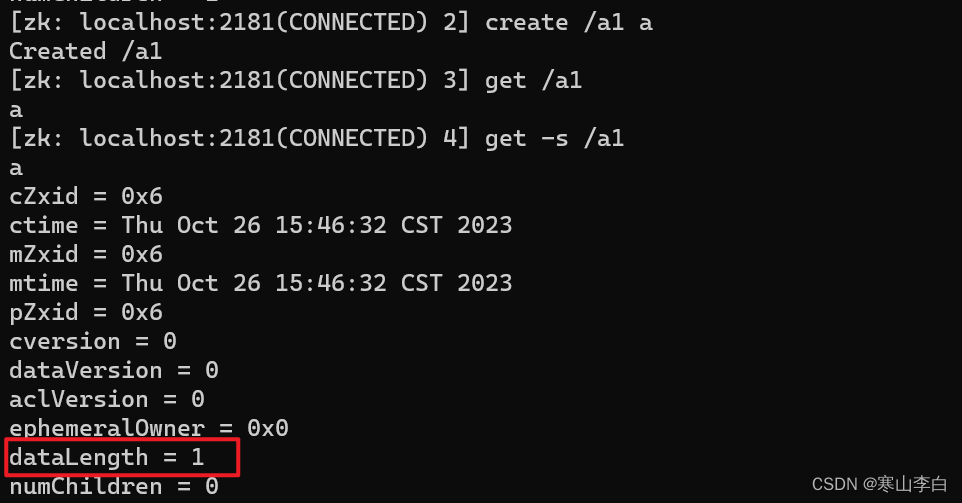
如创建名为a1的节点,内容为a
create /a1 a
然后获取子节点a1的信息,看到数据长度dataLength为a的长度1
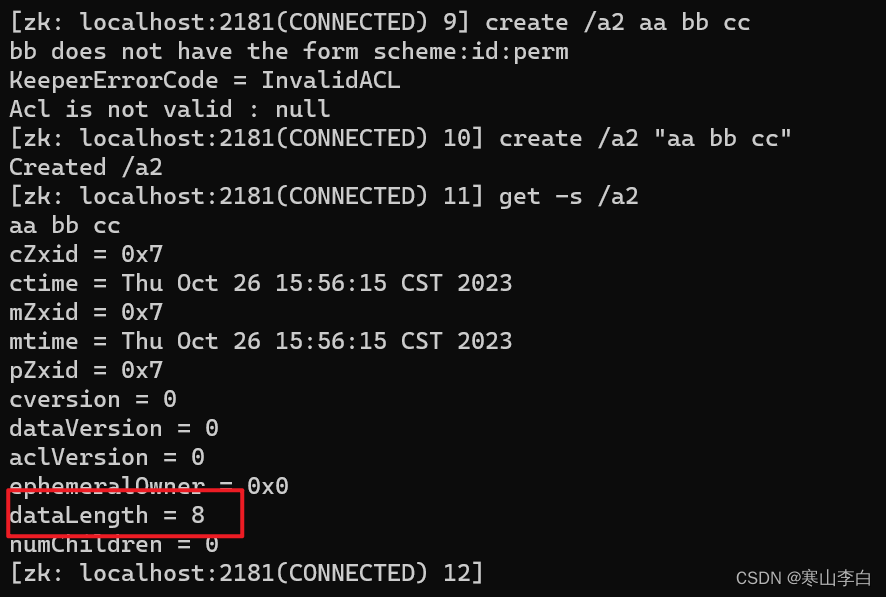
创建子节点a2内容为aa bb cc,加双引号"",不加会报错
create /a2 "aa bb cc"
使用get命令查看数据长度dataLength为8即aa bb cc的长度,包含了空格在内
5. create -e创建临时节点
语法:
create -e 节点名称 节点内容
创建临时节点,当连接断开后,临时节点会被自动删除
如下创建临时节点a3内容为aaa
create -e /a3 aaa
然后查看所有节点列表
ls -s /
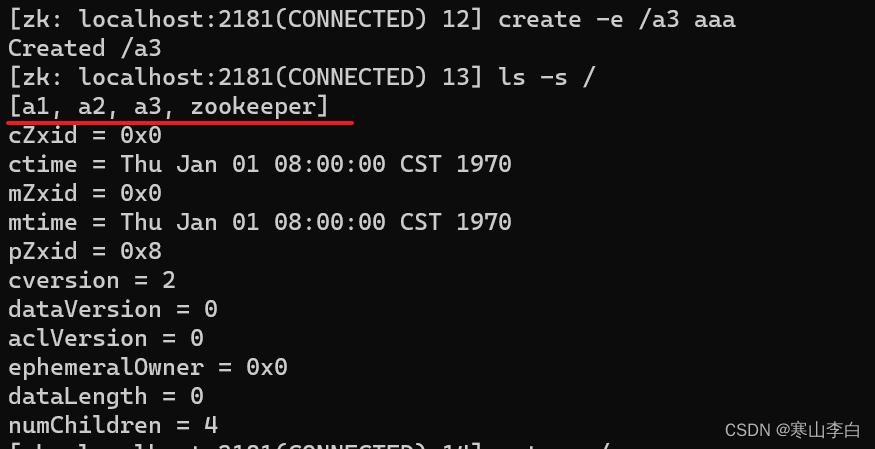
此时子节点a3已经创建好
关闭服务重启客户端,在zkCli的窗口按快捷键Ctrl+C关闭服务,zkCli.cmd回车启动

再次查看根节点所有节点数据
ls -s /
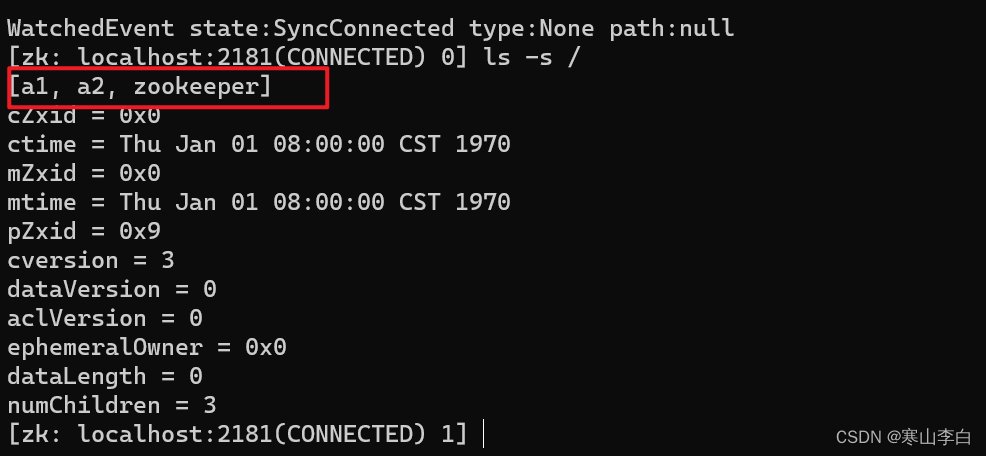
临时节点a3经没了
6. create -s创建顺序编号节点
语法:
create -s 节点路径 节点内容
创建顺序编号节点,即带序号的节点,序号的规则为新建节点的同级节点的数量的排序,从0开始,且包括临时节点和被删除的节点(即被删除后的节点也会算作序号)
如创建顺序节点/a4 aaaa
create -s /a4 aaaa
此时看到新建节点的名称变为a40000000003
然后查看根节点的所有节点数据
ls -s /
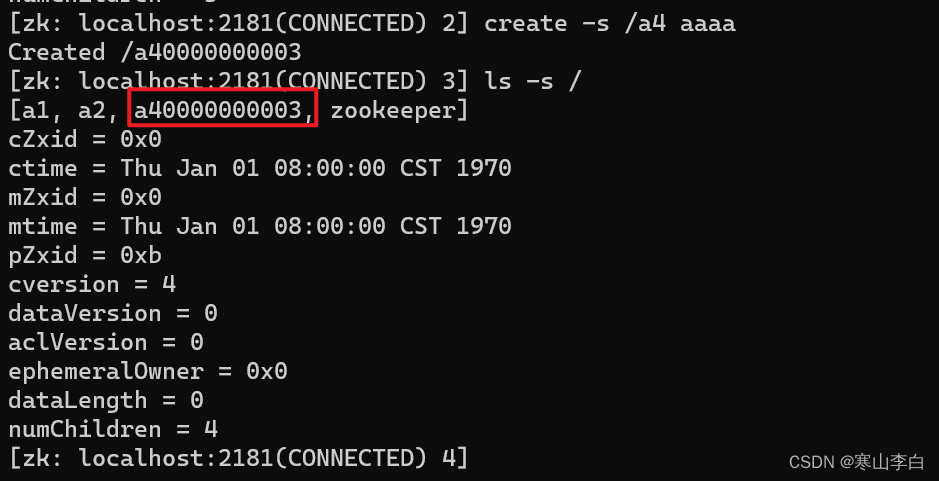
zookeeper节点不算在其中
因为同级的节点数为a1、a2、a3(临时节点,重启后已经没了)共三个节点
依次排序为0-1-2
故a4的序号为a4加上分配的序号0000000003
顺序编号节点的特点如下:
- 顺序编号节点会紧跟在节点名称后面,节点最终名称为
节点名+序号,如/a40000000003 - 顺序编号是一个
递增的计数器 - 顺序编号是由
父节点维护,从已有的子节点个数开始(包括可临时节点和被删除的节点) - 如果子节点为空,则从
0000000000开始,依次递增1 - 在分布式系统中,顺序编号可用于为所有事件进行全局排序,客户端可根据序号推断事件的顺序
7. delete删除节点(空节点)
语法:
delete 节点路径
注:delete删除节点只针对于空节点,非空节点(其中含有子节点)delete删除不掉
先创建一些节点及子节点
create /a1/b1 b
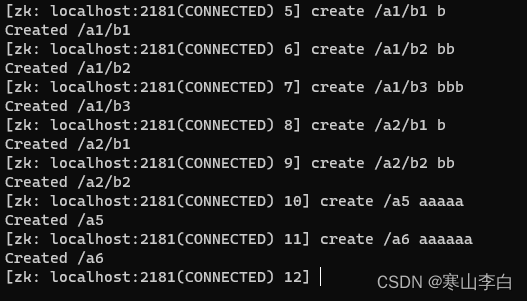
查看根节点下的所有节点
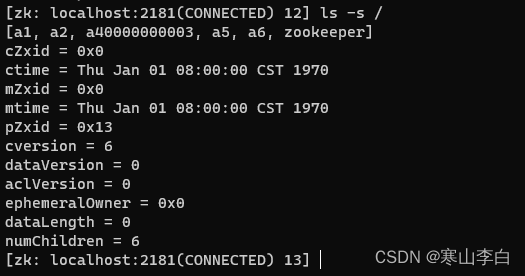
如图可看到节点a1,a2,a40000000003,a5,a6,zookeeper
其中a1和a2节点中含有子节点
我们先删除含有子节点的a1节点
delete /a1
报错,节点不是空的,即非空节点用delete删不掉

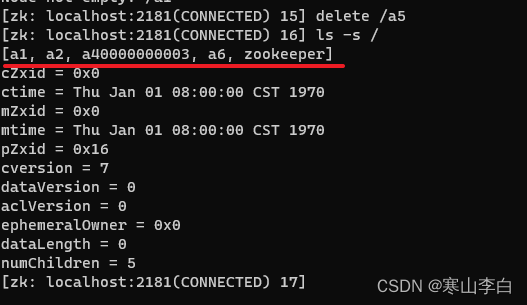
现在删不含子节点(也就是空节点)的节点a5
delete /a5
没报错,表示删除成功,然后查看所有节点看a5还在不在,已经不在了
8. deleteall删除节点(非空节点)
语法:
deleteall 节点路径
先查看非空节点a1中的子节点,确定它是含有子节点的非空节点
ls -s /a1
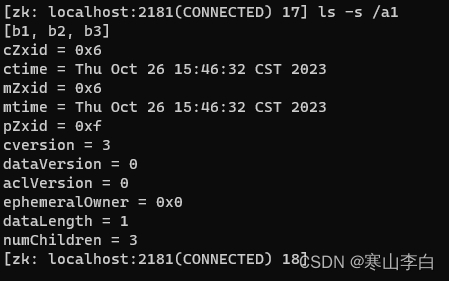
如图看到a1中含有b1,b2,b3三个子节点,说明它是一个非空节点
使用deleteall删除a1
deleteall /a1
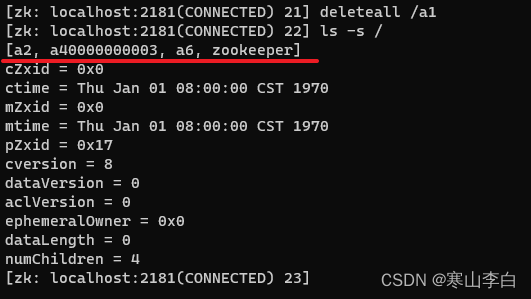
然后查看根节点下的所有节点,发现a1节点已经没了
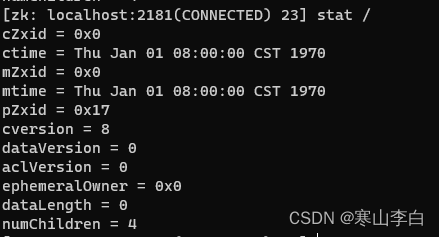
9. stat查看节点状态
查看节点状态,这个跟ls和get的命令感觉一样
stat 节点路径
如
stat /
感谢阅读,祝君暴富!
相关文章

ubuntu20.04安装实时内核补丁PREEMPT_RT
如何使用 img 文件在 VirtualBox 中创建虚拟机?

Linux 目录磁盘满了,怎么查找大文件
Linux CentOS系统安装SQL Server并结合内网穿透实现公网访问本地数据

如何在 Debian 12 上安装 Microsoft SQL Server?
使用redis-insight连接到服务器上的redis数据库
树莓派4B(Raspberry Pi 4B)使用docker搭建springBoot/springCloud服务

服务器与电脑的区别?

Linux 别名命令:如何创建和使用 Linux 别名

linux docker 部署mysql8以上版本时弹出Access denied for user root @ localhost (using password: YES)的解决方案

Linux 磁盘空间占用率100%的排查

chatchat部署在ubuntu上的坑
Kafka常见生产问题详解
Zookeeper分布式队列实战

解决Linux环境下gdal报错:ERROR 4: `/xxx.hdf‘ not recognized as a supported file format.

内网穿透、远程桌面、VPN的理解
VMware中CentOS 7解决网络问题

Linux 服务器 CPU 详细信息查看、物理 CPU 以及逻辑 CPU
浅谈ARM嵌入式中的根文件系统rootfs
linux配置DNS主从服务器
Centos系统上安装PostgreSQL和常用PostgreSQL功能

ZooKeeper 应用场景深度解析
如何配置Pycharm服务器并结合内网穿透工具实现远程开发


Linux(Ubantu)交叉编译生成windows(32位,64位)可执行程序和库

Zoho SalesIQ:构建客户服务知识库的实用工具与指南
如何使用Node.js快速创建本地HTTP服务器并实现公网访问服务端

如何使用Docker将.Net6项目部署到Linux服务器(三)